
Service Mesh 双十一后的探索和思考

1、引言

2.能力建设
链路加密
为了达到一个更高的安全水位,我们预期在蚂蚁内部所有的通信 100% 加密覆盖,这就是链路加密。
设计
必须简化大规模场景下的运维复杂度问题,需要具备可灰度、可回滚的能力。 灰度运行期间,明文和加密切换不能对业务请求造成影响,需要进行热切换。 开启加密以后,对性能的影响必须控制在可接受的范围内。
基于这些需求,完成了链路加密的架构设计,主要思路包括:
通过统一的管控面控制服务端应用的配置,基于动态服务发布与订阅机制,在服务端支持加密能力以后,客户端自动进行加密的切换,运维人员只需要控制服务端配置节奏完成灰度;在灰度运行期间,服务端同一个端口需要同时支持明文和加密的能力。 相比于明文通信,基于 TLS 加密的通信主要消耗在连接建立的握手期间,服务端和客户端采用长连接的方式,减少连接的建立,以减少开启加密对性能的影响。 客户端在感知到服务端明文和加密状态变化以后,需要在不同的长连接之间进行稳定的切换,后文会详细介绍。
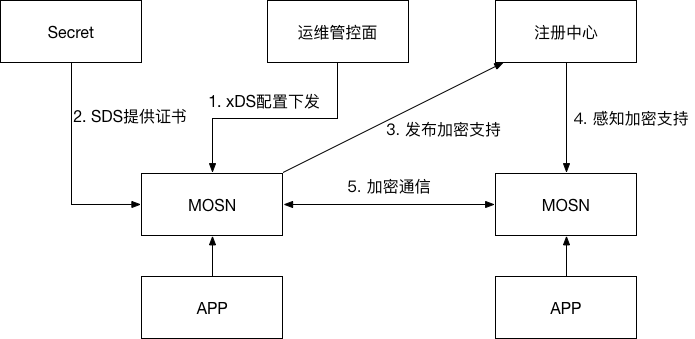
加密状态热切换:连接淘汰机制
优化
自适应限流
技术原理

能用一句话说清楚你们的技术原理吗?

类 PID 控制流量闭环自适应调节

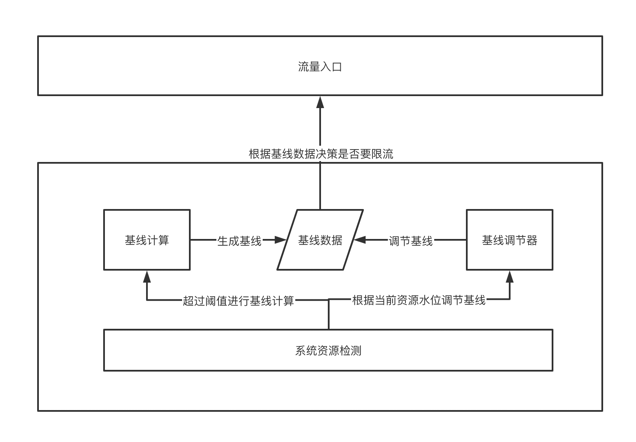
系统资源检测:秒级检测系统资源占用情况,如果连续超过阈值 N 秒则触发基线计算,同时开始拒绝压测流量进入。 基线计算:将当前所有的接口统计数据遍历一遍,通过一系列算法找出资源消耗大户,再把这些大户里明显上涨的流量找出来,把他们当前的资源占用做个快照存入基线数据中。 基线调节器:将上一步骤存入的基线数据根据实际情况进行调整,根据系统资源检测的结果秒级的调整基线值,若系统水位超过阈值则按比例下调基线值,否则按比例恢复基线值,如此反复。 限流决策:根据上述步骤生产的基线数据决策是否限流。
技术原理
| MOSN 自适应限流 | 传统 QPS 限流组件 | |
| 规则数量 | 每个应用只需要配一个 | 每个接口都需要配置一个 |
| 触发条件 | 按系统整体水位 | 按接口调用量 |
| 限流值 | 动态实时计算 | 固定值 |
| 生效点 | 在 MOSN 中拦截 | 在应用的限流组件拦截 |
| 接入与升级成本 | 已 Mesh 化的应用自带,无成本 | 应用接入 SDK ,接入和升级需做发布 |
精细化引流
单应用引流
单应用切流是指在单元化的架构下,利用 MOSN 对流量的代理和调度能力,将应用粒度的流量从当前部署单元引流到另外的部署单元。
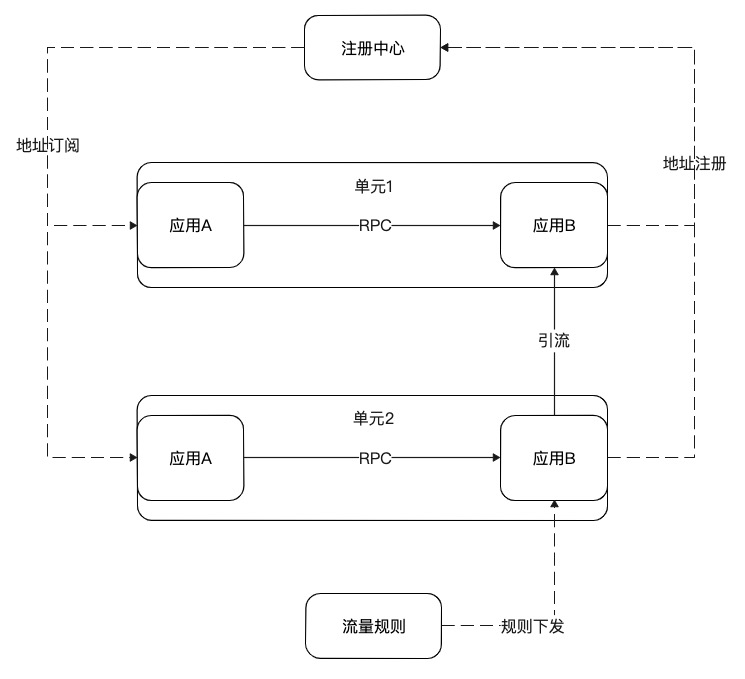
如图应用 A 和应用 B 是上下游关系,它们对等部署在单元 1 和单元 2 两个部署单元。应用 B 将自己的地址注册到注册中心。应用 A 通过注册中心发现应用 B 的地址,然后发起 RPC 调用,调用收敛在单元内。单元 2 内应用 B 的 MOSN 根据切流规则将来自上游的流量转发到单元 1 的应用 B。单应用引流的方式可用于多种场景,如:
灰度发布:当应用 B 需要做新的迭代发布,可以先将流量都 100% 切到单元 1,然后完成单元 2 集群的发布,再将单元 1 的流量逐量回切回来,中间有问题随时回切。
容灾:当应用 B 的其中一个单元因为代码配置变更或其它原因导致长时间不可用时,可将流量都切到其它部署单元。
机房新建:可将已有部署单元的应用的流量用该方式引流到新机房内的部署单元做验证。而当新的部署单元都完整引流后,这个时候如果出现个别应用有问题,也不必将整个部署单元的流量回切,利用单应用切流将出问题应用的流量切回原部署单元即可。
另外 MOSN 的单应用切流还支持接口级别的切流,支持部署单元之间的多到一,一到多,多到多的方式。这样灵活的切流方式,为业务带来了很大的想象空间,相信未来会有越来越多有价值的解决案例在此基础上生长出来。
引流压测
随着业务发展,应用不断发布,在多次迭代之后,应用的性能水位离之前的基线已经走远多少了呢。如果没有一个好的性能管理方式,日常机器集群不断扩容,增加成本。每次大促临近,大家开始梳理变更,设计压测方案,然后反复压测发现性能问题,再迭代发布解决问题,时间存在风险,问题的积累不可控。引流压测利用 MOSN 的精细化引流能力,将线上集群流量引流到单机进行性能压测。每天自动回归,常态化地绘制出应用的性能基线。
业务链路隔离
当你给别人转账,这笔流量其实会经过一条具有 n 个应用的链路的处理。微服务的架构带来了诸多好处,也会带来如稳定性的一些挑战。如这笔转账流量所涉及到链路中的 n 个应用,任意一个应用出现了不可用,就会导致这笔支付失败。是否可以让这些应用都识别出如支付这样重要的链路,为其提供高可用的保证。基于 MOSN 的引流能力我们做到了业务链路隔离的方案。
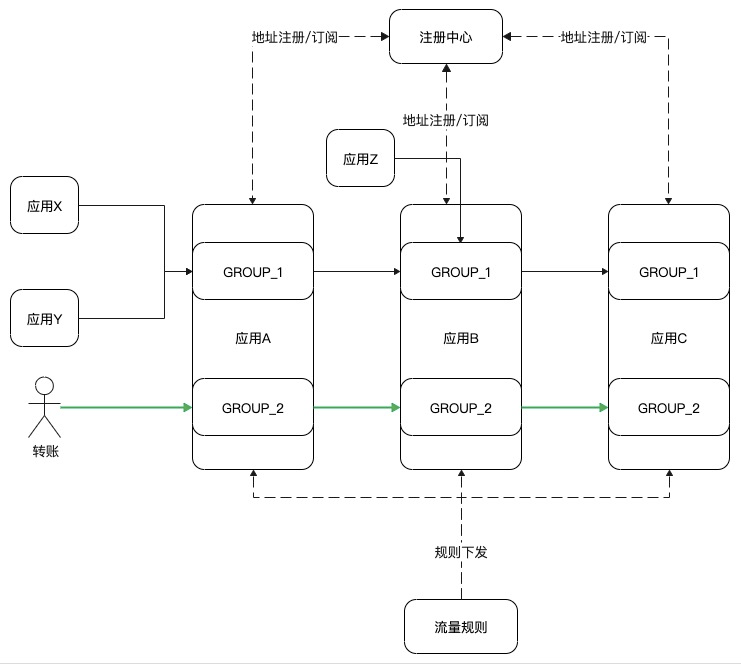
Match: type = transferAction: Group = Group_2
服务自愈
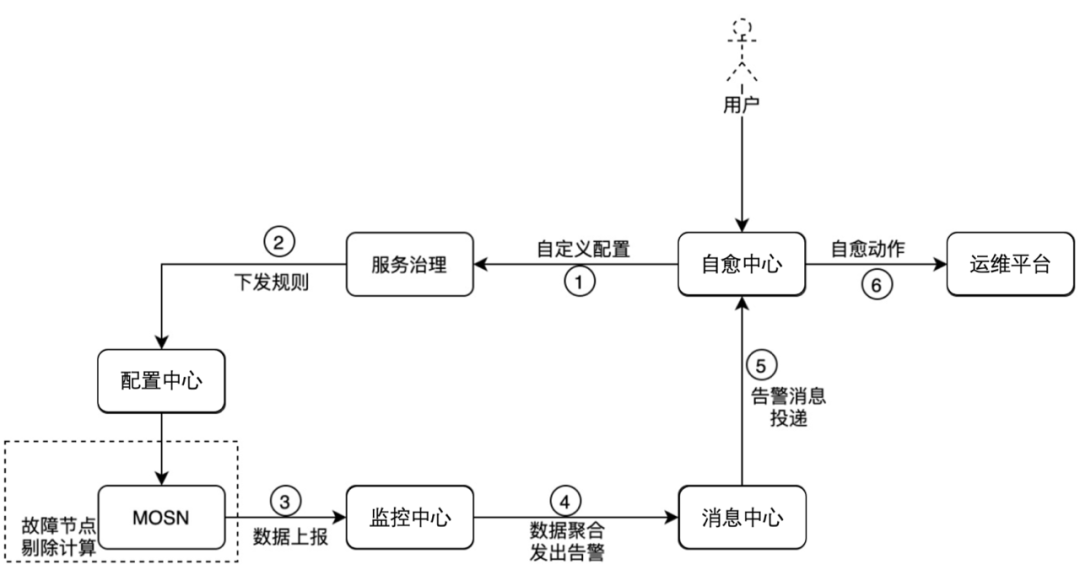
首先我们在 MOSN 内部对于每个服务的异常请求做了统计计数。当统计视角可以区分出有明显问题的远端节点时,可以暂时的将该节点放入本机的调用黑名单中,避免问题持续。依赖于调用请求的频率,统计的时间窗口可以从亚分钟级到秒级。对于高频的重要服务,单机问题的待续时间也被限制在了秒级,实现了服务的秒级自愈。
3. Service Mesh 的价值
4. 小结
推荐阅读: