
腾讯云在PostgreSQL领域的‘‘再次突破’’
日前,第11届PostgreSQL中国技术大会圆满落幕,大会上腾讯云多位顶级技术达人携手亮相,分别对腾讯云PostgreSQL系列产品技术亮点和创新实践案例进行了深入解读,针对TDSQL-C PostreSQL高可用特性、TDSQL-A发展历程、技术架构等做出了详细介绍。
会上腾讯云数据库开源产品TDSQL PostgreSQL版(开源代号Tbase)再次公布升级:分区表能力增强,分区剪枝性能提升30%,分布区表关联查询性能(Join)提升超十倍。此外,异地多活易用性增强、分布式死锁自动检测并解锁功能上线,2PC残留自动检测并清理等多方面升级,全方位的展示了腾讯云在PG技术领域的突破和服务。
同时在本次大会,腾讯云TDSQL凭借成熟的一站式解决方案和行业应用实践,斩获“数据库最佳应用奖’’,这是既获得中国开源软件联盟PostgreSQL分会颁发的‘‘2021 PostgreSQL中国最佳数据库产品’’奖之后,TDSQL在PostgreSQL领域的出色表现再获认可。本次主论坛现场,腾讯云数据库专家工程师刘少蓉详细解读了腾讯云在PostgreSQL领域的全线产品技术架构演进和应用场景,今天带大家一文纵览刘少蓉博士的演讲精华。

(数据库最佳应用奖)
腾讯云PostgreSQL家族
早在2008年开始,腾讯在PG方面就开始做相关数据库研发,经过十几年的研发和业务打磨,我们腾讯也为业界贡献了比较丰富的产品线:RDS云数据库(TencentDB for PG),TDSQL PG版 (企业级分布式数据库PG版,为用户提供TP、AP整体解决方案),TDSQL- A(基于分布式TDSQL架构专门研发的一款分析型产品)和TDSQL-C PG版(云原生数据库)。下面我们会详细介绍每款产品的架构和应用场景。
TencentDB for PG是腾讯云在PG方面的RDS,用于给用户提供开箱即用的云端数据库服务。用户可以通过云控制台一键创建和管理数据库。腾讯云负责处理绝大部分复杂而耗时的管理工作,如 PostgreSQL 软件安装、存储管理等,这样用户就可以更专注于业务程序开发。
我们来看一下TencentDB for PG的架构,这也是比较典型的单机云数据库的架构。一主一从的强同步保障服务的高可用。同时呢,在线的热数据也会定时的备份到COS上面,以便在数据库灾难时进行数据恢复,这也保证了高可靠性。TencentDB for PG也跟多种腾讯云产品集成和联通,比方说云监控可以自动监控数据库,省去了人工DBA,ES集群提供了日志查询服务等。
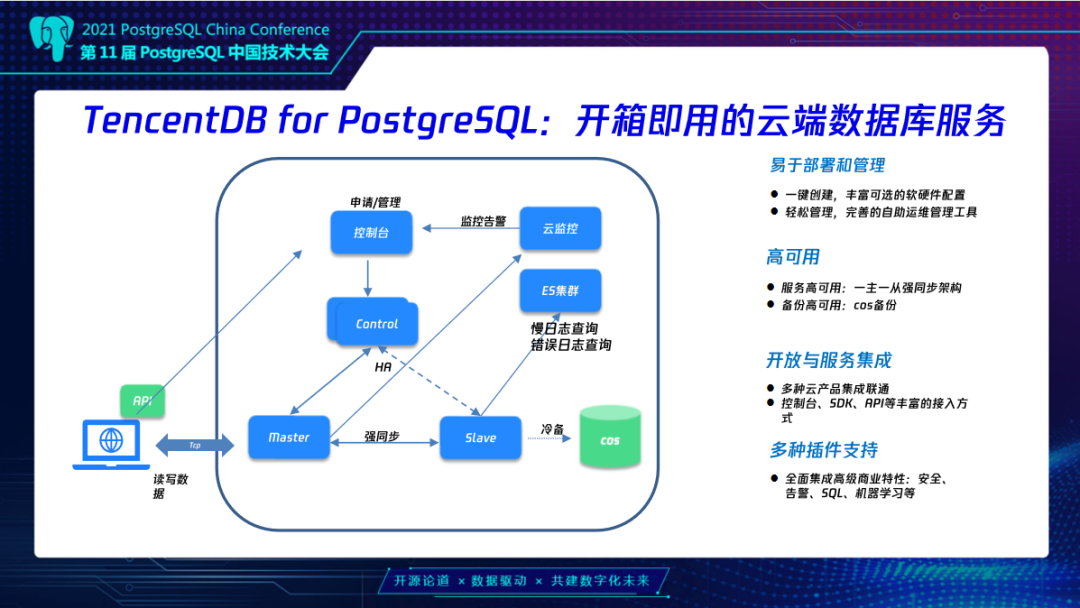
除了典型RDS服务,腾讯云TencentDB for PG还有一些比较独特的优势,可以根据业务的需求来定制化内核优化。举个例子,曾经有个用户在使我们RDS服务的时候,
反馈说当出现频繁CREATE TABLE / DROP TABLE的时候,尤其是大表的操作时,会造成主备之间较大的延迟,导致WAL大量的堆积、来不及重放并回收。根据这个场景我们在内核上加入异步DDL方式,在收到DROP TABLE的WAL 时,先进行标记,在空闲时逐步从shared_buffer和存储上删除数据。从而实现备库上 DDL 的异步处理、及时响应后续 WAL 的重放,避免了堆积。
TencentDB for PG在一定数量下提供了一种All In One的数据解决方案。大家也都知道PG本身是一款非常好的开源软件,也有着比较好的TP和AP能力。当用户在使用PG时业务不断扩大,数据量超过单机limit的时候,那么腾讯云数据库能够提供什么解决方案呢?
传统的方法是多加几台机器,分库分表,把一张逻辑表分为很多物理表,这个好处也是非常明显的,比如说插入性能会比较高,点查也很快。当然问题也很多。业务本身需要实现非常复杂的分布式逻辑,比方说分布式事务, 数据库跨表查询等。对用户更友好的解决方案是数据库本身提供分布式架构, 比方说share-nothing MPP,提供存储和计算的水平扩展能力。把复杂的分布式逻辑留给数据库解决,业务逻辑简单。
TDSQL PG版架构,可以从三个角度来看,首先是GTM事务管理器,它是负责分布式架构下全局事务管理,以及全局的对象管理。同时事务管理器是通过一主多从来保证它的可靠性、可用性。架构图中右侧上层是Coordinator(协调节点CN),它主要提供业务访问入口。协调节点中每个节点之间是对等的,也就是说业务访问这三个节点里面的任何一个,它得到的结果都会是相同的。图中下层是我们的数据节点(Datanode)。数据节点是我们实际存储数据的地方。每个数据节点会存储一份本地的数据分片还有本地元数据。Datanode同时提供了计算功能,例如本地数据的计算以MPP架构下数据重分布的计算,e.g. join, aggregation。我们这个架构下也有相应管控,比如说指标监测、运维管理、告警、安全审计、数据治理等等。
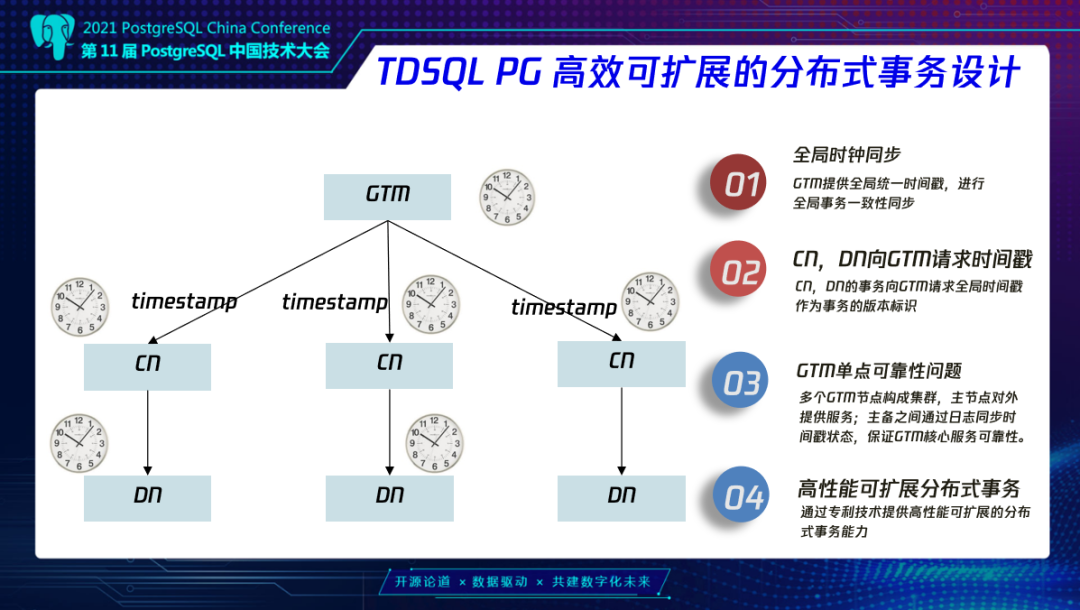
分布式事务系统里的一个核心设计难题就是如何高性能,低成本的保障事务的一致性。针对这个问题,我们TDSQL PG版也发明了一套基于Global TimeStamp (全局时间戳)的MVCC可见性判断协议来提供高性能可扩展的分布式事务能力。这种协议下 GTM 只需要去分配全局的 GTS,CN,DN节点上的事务会向GTM请求GTS来作为事务的版本标识。这样就可以把提交协议从 GTM 的单点瓶颈下放到每一个节点上,减轻压力。同时多个GTM节点构成集群,主节点对外提供服务,主备之间通过日志同步时间戳状态, 保障了GTM服务的高可靠性。
TDSQL PG版经过十余年研发,在2019年11月7号进行开源,开源代号TBase,欧洲航空航天局曾利用TDSQL开源版进行航行探索项目,数据量高达300多TB,是一个比较成功的案例。在2019年开源以后这中间进行过多次版本升级。在2021年7月开源了新版本,提高了性能以及管理方面。2022年1月1号再次升级全新版本,在分区能力方面以及易用性方面都有重磅升级。
接下来要介绍的是我们的分析型产品TDSQL-A,TDSQL-A是基于TDSQL PG版架构上全面优化来打造关于分析性能AP方面的数据库。TDSQL-A定位是希望能够提供海量数据实时分析,所谓海量数据是指10PB以上秒级分析查询功能,同时TDSQL-A也100%兼容PG,也高度兼容Oracle,兼容性在特定场景下达到98%。

下面大概介绍一下TDSQL-A的核心技术。首先它是行列混存,在过去十年间有很多商业级数据库为分析场景研发推出列存引擎。每个列单独存储,可以达到比较高的压缩比。分析型的查询通常只涉及到一个数据库的某些列,不需要查询一个行的所有列。我们TDSQL-A给列式数据提供多级压缩,比如说透明级、轻量级。我们还根据数据本身的类型选择和定制压缩技术。
同时我们也有着非常高效的向量执行引擎,以及多种并行策略:节点间的并行MPP, 进程间的并行SMP,以及指令型的并行SIMD。最后不得不提一下的是我们独特的分布式延迟物化能力。延迟物化是一种常用的数据库常优化技术。但是分布式分布式延迟物化技术目前在我们是业界第一个提出和实现。我们的优化器是基于代价的, 它会根据具体查询来决定,比如说什么时候要延迟物化什么时候要提前物化。我们的分布式延迟优化的能力,能够减少不必要的网络开销。
介绍完了我们的单机云数据库TencentDB for PG, 我们的share-nothing MPP架构下的分布式数据库(TDSQL PG版和TDSQL-A)。接下来我们来聊一聊云原生数据库。首先为什么有云原生数据库的需求呢?在无共享的MPP架构下,计算和存储是紧耦合的。那么当业务有瓶颈的时候,不管是计算瓶颈还是存储瓶颈都需要加资源,而且两者的瓶颈的时间点通常不一样,那么这样必然浪费 资源而且不容易扩展。针对这些痛点,AWS Aurora在2017年提出了计算存储分离的数据库架构。这个架构也是云原生数据库的基石。云原生的本质就是资源池化,降本增效。用户可以按需弹性灵活地扩展 计算或者存储。如果有需求需要增加存储就在共享存储里增加,如果计算节点方面有瓶颈就可以增加计算节点。比如说这个架构下面通常一主多从,主RW提供读写能力,从RO提供读的能力。
Aurora在提出存算分离时也提出了一个观点,就是日志即数据库log is thedatabase。Log is the database的核心思想是主备是基于同一份数据。在这个思想之上当我们写数据的时候,只需要把日志写到共享存储里就可以了。为什么呢?因为共享存储上面它完全可以通过存放日志来实现存储节点上面修改,存储层以Page为单位来维护数据。因为不需要跨网络写数据本身到共享存储上面,所以极大优化了写的性能。在读的性能上面也有优化,每个RO节点它可以在很多情况下从主节点上面接收日志重放来满足读的请求,在少的情况下还需要从共享存储上去读数据。
基于存算分离,日志即数据库的设计思想,我们在去年11月份商业化了云原生数据库TDSQL-C PG版。TDSQL-C由腾讯完全自研,融合了传统数据库、云计算、新硬件技术的优势。高可用、高可靠、高性能以及极致弹性,能够达到秒级备份和回答。
下面来讲一下云原生数据库PG架构,左边这个图大概可以分为两个部分,上面是计算层,下面是存储层。计算层大概分为三个部分,首先是CynosPG,CynosPG是基于PG研发的计算引擎,它提供通常计算引擎的功能,查询处理器、事务管理、缓存实现等等。因为计算层并不存储数据,而且我们只是把日志存储在存储上面,所以也就省去了不必要的,比如说Full page write、脏页刷盘。计算层中间一层是用户态文件系统Cynos File System,它主要是提供了分布式文件管理。最下面一层是Cynos Store Agent,它提供了计算存储之间的读写交互,以及主备之间日志流的同步。
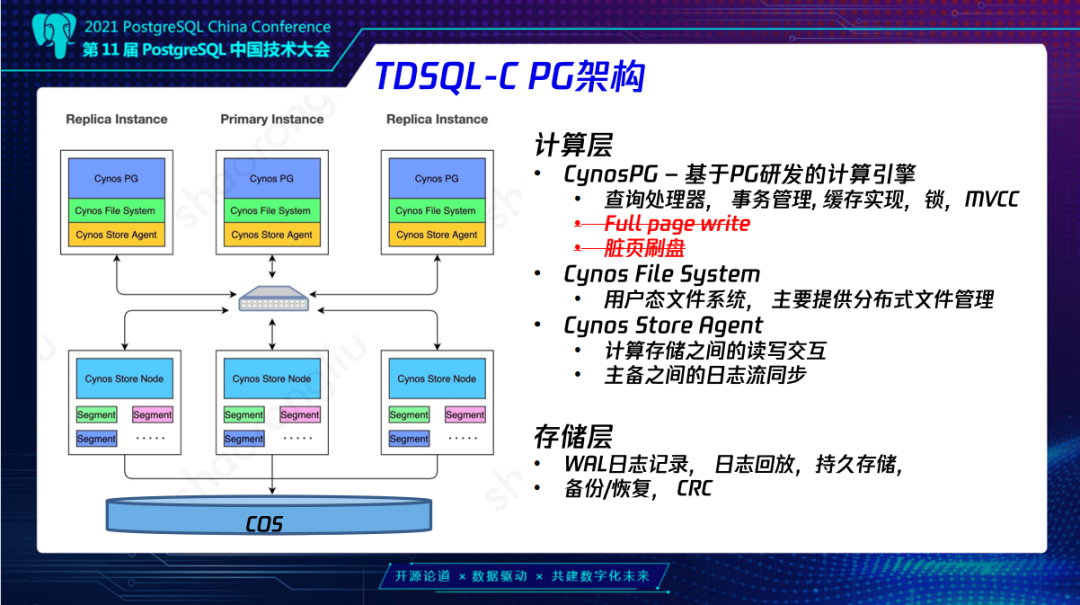
在存储层方面首先需要记录日志,需要回放日志,同时也提供了CRC日志校验以及备份/恢复等。同时数据也会定时地冷备到COS上来保证高可靠性。
分布式存储方面的架构,首先大家可以看到有很多StoreNode,我们简称SN,StoreNode提供的是数据服务,StoreNode维度可以看到不同的pool。每个pool对应了一个数据库实例,每个pool下面又同时划分为不同的segment,每个segment基于Raft多数派提交保证多副本。
以segment维度来存储数据它其实有很多优点,第一个是弹性,我们有专门的监控系统监测存储方面的是否情况,当存储节点的使用没有达到一定阈值时,就会从空闲StoreNode加一个到共享存储池里面,同时可以从segment进行搬迁,这样做的好处是它并不会影响到主segment的读写请求。另外以segment可以实行并行搬迁。多个segment同时并发的搬迁,提高效率。
最后关于我们TDSQL-C PG版方面,计算节点方面也是高可用的弹性,比如说当业务需求需要增加或减少计算节点时,同样也可以很快拉起一个新的计算节点,而且这个计算节点基本上是无状态。同时这个计算节点可以自由地添加,根据业务诉求可以添加不同规格来弹性地实现弹出链路业务需求。
未来机遇与展望
最后分享一下未来我们会在PG生态方面有什么样的规划,首先我们生态是要不停地跟进社区发展,同时我们也会持续开源我们的TBase的新功能。第二个是关于Oracle兼容性、应用性方面,我们现在在这四款PG产品方面都高度兼容,当然离目标100%兼容还有一定距离,所以我们肯定需要持续发展进行深耕。
第二个角度,架构方面我们现已有云原生的数据库,下一步更希望能够把HTAP搬到云原生上面,同时实现Serverless以及Multi-master,能够高效地实现数据共享,保证安全性。
第三个角度是从怎么充分利用我们新硬件,来实现软硬协同提高性能。最后可能就是智能化,可以理解为怎么能够,比如说智能调优是一方面,腾讯云方面有DBBrain(智能管家),再一个就是AI in DB,怎么实现in-database machine learning和analytics。
最后我想引用一下之前看到的一篇文章,CMU 数据库教授Andy Palvo写的关于2021年数据库的review,提到的一句话是"PostgreSQL has become the first choice in new applications."。 PG已经成为新应用的首选。我们现在属于数据库黄金时代,所以我们会一起共同努力,谢谢大家!
﹀
﹀
﹀

又拿奖了!腾讯云原生数据库TDSQL-C斩获2021PostgreSQL中国最佳数据库产品奖

一文详解TDSQL PG版Oracle兼容性实践

云原生数据库TDSQL-C PostgreSQL版内核解密
↓↓点击阅读原文,了解更多优惠