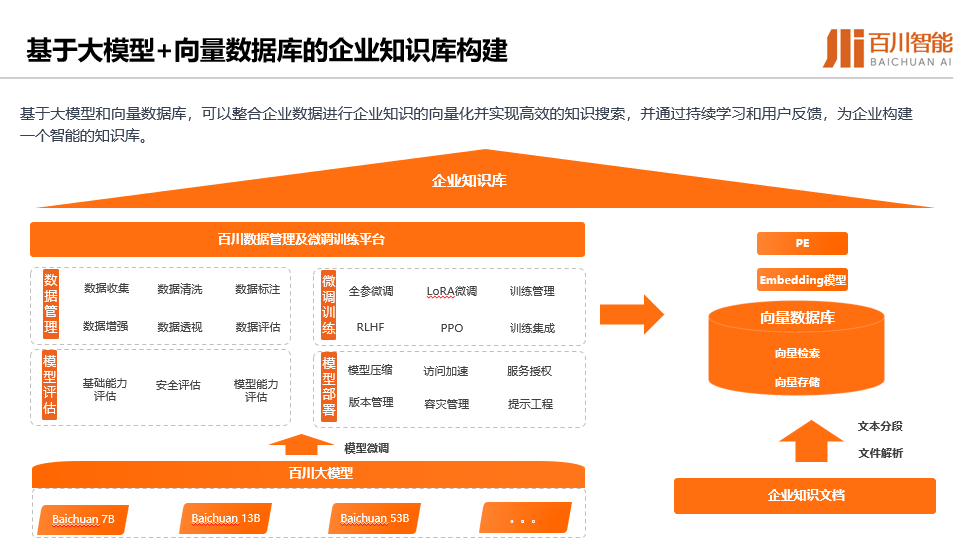
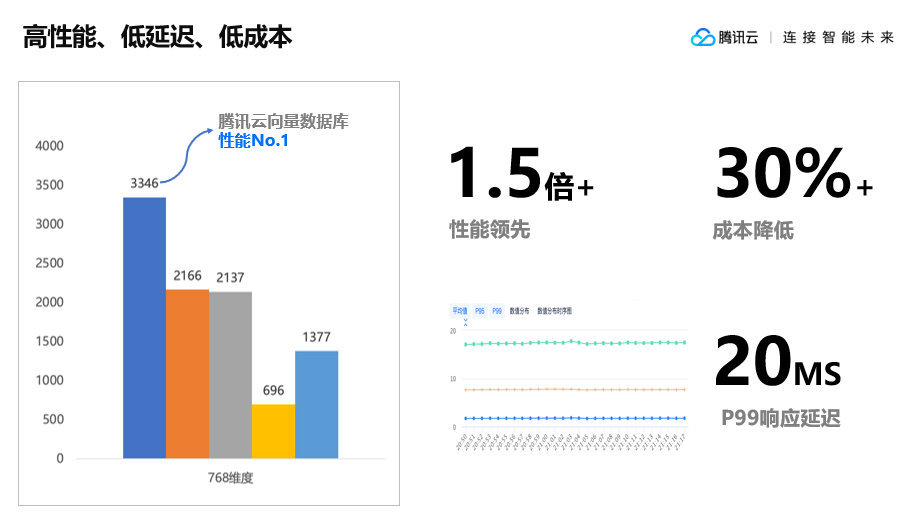
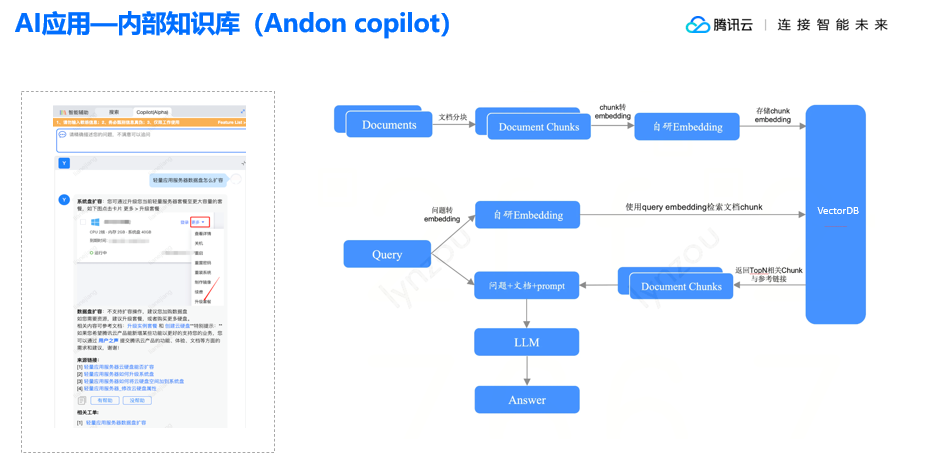
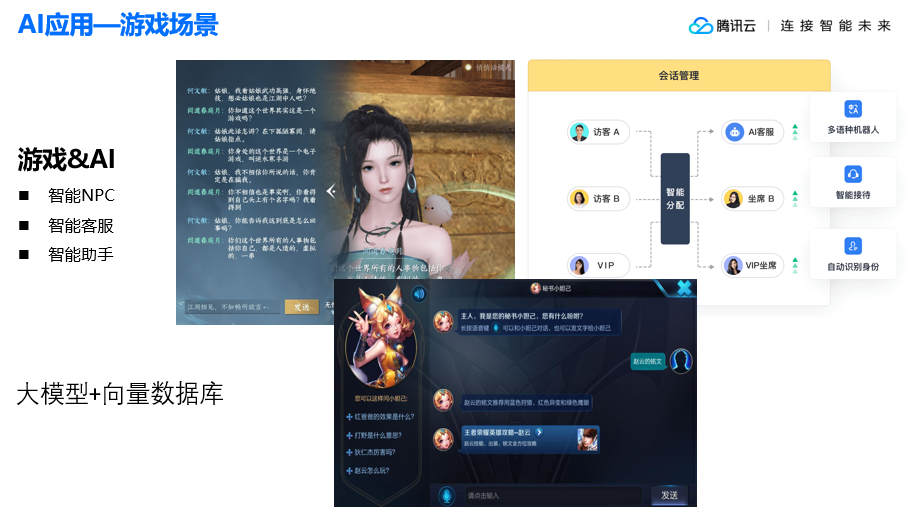
降低用户使用门槛,向量数据库与大模型联合开发产生“飞轮效应”腾讯云数据库关注共 7582字,需浏览 16分钟 ·2023-10-28 18:26 都说大模型带火了向量数据库,有人还把向量数据库称之为是大模型背后的“军火商”。的确,用好大模型,离不开向量数据库。在大数据中寻找有用信息,必须通过向量数据库来解决高维数据复杂的关系和模式,这也是数据库领域常说的“专库专用”。 但好用的向量数据库,不只是在AGI( Artificial General Intelligence )光环下“坐享红利”,而是以用户为中心,推动应用和新商业模式的快速落地,这应该是腾讯云向量数据库(Tencent Cloud VectorDB)和百川大模型走得越来越近的根本原因,两家企业通过联合产品开发,实现了“双向奔赴“。 10月15日,由百川智能举办的“AGI For Better”AI黑客马拉松大赛在上海圆满落幕。本次活动旨在鼓励开发者在 AGI应用场景的探索,深入挖掘大模型技术在医疗健康和游戏娱乐领域的前沿应用潜力。 大赛吸引了来自全国各地共100多支优秀开发者团队报名,通过前期线上遴选,最终有42支队伍进入到线下决赛环节。来自互联网企业、高校、游戏公司、投资机构的十多名重磅嘉宾出任评委,除了与选手交流互动,评审团还将为参赛的优质项目提供相关资源,包括协作、孵化、投资等。这意味着本次活动的意义并不仅仅是比赛,同时旨在进一步帮助优秀团队与行业专家、投资人、游戏公司、互联网企业建立联系。 比赛规则是,参赛团队需要在48小时内完成项目开发。参赛选手们需要充分发挥队伍的创意及追求极致的极客精神,利用Baichuan大模型让创意转化为可落地应用。期间,腾讯云向量数据库(Tencent Cloud VectorDB)成为本次大赛关注的焦点,开发者借助这一重要的AI技术基座的支撑,获得了更快、更精准和更可靠的结果,为人工智能创新和应用落地带来了强大的推动力。 在Demo Day评审环节,42支战队火力全开各显所能。与来自百川智能、顶级高校、知名投资机构等组成的评委团展开探讨,评审团从团队现场表现、解决方案创新及应用等多个角度进行了精彩点评,现场交流互动气氛高涨。 向量检索进入大规模应用新阶段 ChatGPT的快速崛起,让人类掀起了通用人工智(AGI)能热潮。相比之前狭义的人工智能时代,通用人工智能不再只专注于特定应用程序,或者完成特定的任务,而是基于机器思考、理解、学习和应用智能来解决更复杂层面的问题,就像人类一样,能够基于心智理论框架,来识别其他智能系统的情绪和思维的一系列过程。 通用人工智能时代的来临,可以说是百年不遇的新机遇。不管是学术界,还是业内顶尖的企业家,都把2023年看成是生成式AI与大模型爆发的元年。我们可以看到,从去年下半年到现在,铺天盖地的大语言模型在国内外诞生,很多人都在研究如何把大模型引入产业,实现商业化落地。 只是,大模型如火如荼的背后,为什么还需要一个向量数据库?腾讯云数据库产品经理陈薏竹给出的答案是,交互和新检索需求是最大推动力! 大语言模型是一种新的应用形态,不管我们用它来写作,或者进行智能问答,还是生成代码,本质上都是基于自然语言的提问式、对话式交互形态。在这种新的生产力和新的交互形态下,必须由新的检索方式来支撑,以向量的方式处理大量文档、图像、视频等非结构化数据,而这种基于向量的检索和处理能力,就是向量数据库的核心技术。 需要明确的一点是,向量检索并不是一项新技术,而是很早就已经在互联网场景使用,比如:推荐和广告搜索、人脸和指纹识别场景,都一直在使用向量检索技术。 向量检索技术最早可以追溯到2016年,Google发布了第一个开源的深度学习框架TensorFlow,到目前为止依然是主流的深度学习框架之一,极大地降低了神经网络模型构建成本,进一步推动了AI和整个向量检索技术领域的发展。2017年,Facebook开源了向量检索引擎Faiss,后续很多向量数据库产品也都有基于此搭建自己的数据库管理服务。 值得一提的是,腾讯在2019年也紧跟时代前沿,推出了向量检索引擎Olama,并在集团内部大规模应用,包括社交、推荐、搜索和广告、游戏等40多个业务基于Olama支撑运营。 向量数据库“王者归来” 腾讯云向量数据库(Tencent Cloud VectorDB)就是基于Olama内核进行自主研发的产品,向量检索请求次数可高达1600亿次/天,能支持更丰富、精准的检索,包括可以基于相似度去做相似性的查询,能根据一些用户自定义的标量字段进行过滤,去做混合检索,完全可满足各个业务场景对向量数据库检索能力的需求。 作为大模型重要外部知识库,腾讯云向量数据库(Tencent Cloud VectorDB)具备三大特性:高性能、低成本和低延迟。其性能可以达到同类产品的1.5倍以上;P99响应延迟整体能够维持在20毫秒以内;成本能降低30%;底层是分布式可扩展的架构,单实例最高可以支持百万级别的QPS,能支持10亿级别的向量规模。 在数据库存储检索服务能力之上,腾讯云向量数据库(Tencent Cloud VectorDB)还提供了一站式检索能力,把知识库构建过程中的文本分割、Embedding算法这些能力囊括到向量数据库,进一步帮助企业降低向量数据库接入成本,提高整体接入效率。 而为了减少用户的测试和运维接入成本,腾讯云向量数据库(Tencent Cloud VectorDB)还提供了可视化的数据管理工具。通过数据管理平台,用户可以直接在线可视化地执行一些互表操作,包括快速体验的测试数据,还可以在这个平台中执行一些常用的数据插入、相似性检索等等常,实现用户操作的在线执行,并且能够可视化地得到整体执行的效果,方便业务快速通过平台去做一些测试和运维工作。 众所周知,大模型开发非常耗费算力,在算法方面非常耗时。为了进一步降低用户在算力、算法工程方面的投入,腾讯云向量数据库(Tencent Cloud VectorDB)还提供了多文本Embedding功能。对于用户而言,有了该功能,可以自动化、没有感知地完成从原始文本到向量的转换,即直接用文本进行写入和检索,大幅简化了向量数据库的操作流程。 问题是,面对处于AGI高光时刻的向量数据库,用户具体是如何使用的呢?目前,业界有一种主流的使用方式,就是用向量数据库构建和存储外部知识库。 在大模型构建过程中,需要企业具备非常强大的处理和整合能力,但在实时数据和私域数据上会存在一些缺失,因为结果由训练的工艺数据的训练集取值确定。如果我们能够通过一种方式,帮助大模型补充私域信息,或者是引入基于外部信息的实时数据,企业就能够快速构建起满足企业和个人需要的定制化专属问答助手。 螺旋上升过程中的“双引擎动力” 换言之,当向量数据库和大模型相互协作,就可以获得1+1>2的效果。以企业知识库构建为例,当企业构建完知识库以后,可以把向量数据库和大模型结合起来进行知识库检索。 一般来说,原始知识信息的存储格式通常是以PDF、Word这种本地文件的形式进行存储,内容都是整段的长文本格式。所以,第一步就需要把这些本地文件转化为AI模型和向量数据库,去处理和计算向量数据。 如果直接提取一些向量,表征能力各个方面都非常有限,因为原始文本中的信息量非常大,所以第一步需要对长文本进行分割,分成一段一段的短文本段,拿到这些表征能力更强的短文本段之后,就可以通过一些特定的Embedding模型生成这些文本对应的向量表示。 生成向量表示,可以简单理解为某个高维空间中的一个点,如果在这个高维空间通过一些相似性的距离计算,发现两个点的距离更加相近,其实也就代表这两个向量表示的原始文本在语义信息各个方面也会更加相似。当我们拿到短文本段和对应的向量表示之后,就可以把这些数据存储到向量数据库里面,构建出企业所需要的一个外部知识库。 向量数据库和大模型结合,构建外部知识库,有两个典型案例: 1、Andon Co-pilot。 这是腾讯的一个服务管理平台,里面会有一个智能问答的模块,主要功能其实就是帮助一线售前和售后的同学快速检索一些产品能力,从而拿到这些信息更好地服务支持客户。 Andon系统用就是通过向量数据库构建各个产品的知识库,在此过程中会把产品的一些原始知识文档进行分割向量化,存储到向量数据库里面,作为补充信息交给大模型进行整合,最终输出符合要求的答案。 2、游戏场景的应用。 以百川智能游戏场景的智能问答为例,企业基于大模型和腾讯云向量数据库(Tencent Cloud VectorDB)搭建了王者荣耀的游戏知识库,其中包括一些基本介绍、英雄的出场介绍、固定答案的问题等等,也同时放了一些能够扰乱答案的错误结论。如果直接问大模型,王者荣耀最美的英雄是谁,大模型就会回答这个问题没有一个固定的答案,因为美的定义因人而异,每个人对美的感受是独特的。 基于大模型和向量数据库的能力可以达到的效果非常明显。句句属实,不用担心大模型会对玩家瞎说,因为只要知识库里的知识真实正确,大模型一定会按照知识库里的知识进行问答,极大地降低大模型的问题,真正做到有迹可循。 至此,向量数据库所扮演的角色,相当于是大模型的“第二大脑”,能够提升大模型在一些特定领域、特定知识上的回答效果,助力更多企业全面拥抱AGI时代。 ﹀ ﹀ ﹀ -- 更多精彩 -- 首家!腾讯云向量数据库完成中国信通院向量数据库产品测试 ↓↓点击阅读原文,了解更多优惠 浏览 252点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Milvus向量数据库Milvus向量数据库能够帮助用户轻松应对海量非结构化数据(图片/视频/语音/文本)检索。单节点Milvus可以在秒内完成十亿级的向量搜索(请参考:在线教程),分布式架构亦能满足用户的水平扩展需求。MLanceDBServerless 向量数据库LanceDB 是一个用于向量搜索的开源数据库,采用持久存储构建,极大地简化了嵌入的检索、过滤和管理Milvus向量数据库Milvus向量数据库0基于LLM大模型的向量数据库企业级应用实践架构之美0LanceDBServerless 向量数据库LanceDB是一个用于向量搜索的开源数据库,采用持久存储构建,极大地简化了嵌入的检索、过滤和管理。LanceDB的主要特性包括:生产规模的向量搜索,无需管理服务器。存储、查询和过滤向量、元数据和多模DB-GPT数据库大语言模型DB-GPT数据库大语言模型0DB-GPT数据库大语言模型DB-GPT是一个开源的以数据库为基础的GPT实验项目,使用本地化的GPT大模型与数据和环境进行交互,无数据泄露风险,100%私密,100%安全。DB-GPT为所有以数据库为基础的场景,构建了一套完整大模型显卡门槛,被打下来了!Jack Cui0ONNX 模型分析与使用机器学习与生成对抗网络0入门门槛最低的数据库数据森麟0点赞 评论 收藏 分享 手机扫一扫分享分享 举报





 下载APP
下载APP