
神器 JMH & Arthas 性能监控
简单介绍两款Java测试和性能监控神器
最近的工作日并不算太平,各种大大小小的case和解case,发现已经有好久好久没有静下心来专心写点东西了。不过倒还是坚持利用业余时间学习了不少微课上的东西,发现大佬们总结的东西还是不一样,相比于大学时的那些枯燥的课本,大佬们总结出来的内容更活,更加容易理解。自己后面也会把大佬们的东西好好消化吸收,变成自己的东西用文字性的东西表达出来。
今天想总结的东西是最近工作中使用到的测试工具JMH以及Java运行时监控工具Arthas。他们在我的实际工作中也算是帮了大忙。所以在这里抛砖引玉一下这些工具的使用方法。同时也加深一下自己对这些工具的熟悉程度。对这两个工具,我都会首先简单介绍一下这些工具的大致使用场景,然后会使用一个在工作中真正遇到的性能问题排查为例详细讲解这两个工具的实际用法。话不多说,直奔主题。
问题描述
为了能够让我后面的实例能够贯穿这两个工具的使用,我首先简单描述下我们在开发中遇到的实际的性能问题。然后再引出这两个性能工具的实际使用,看我们如何使用这两个工具成功定位到性能瓶颈的。
问题如下:为了能够支持丢失率,我们将原先log4j2 的Async+自定义Appender的方式进行了修正,把异步的逻辑放到了自己改版后的Appender中。但我们发现修改后日志性能要比之前Async+自定义Appender的方式下降不少。这里由于隐私原因我并没有用实际公司中的实例,这里我用了一种其他同样能够体现问题的方式。我们暂时先不给出具体的配置文件,先给出性能测试代码和结果
代码
package com.bryantchang.appendertest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class AppenderTest {
private static final String LOGGER_NAME_DEFAULT = "defaultLogger";
private static final String LOGGER_NAME_INCLUDE = "includeLocationLogger";
private static final Logger LOGGER = LoggerFactory.getLogger(LOGGER_NAME_INCLUDE);
public static final long BATCH = 10000;
public static void main(String[] args) throws InterruptedException {
while(true) {
long start, end;
start = System.currentTimeMillis();
for (int i = 0; i < BATCH; i++) {
LOGGER.info("msg is {}", i);
}
end = System.currentTimeMillis();
System.out.println("duration of " + LOGGER_NAME_INCLUDE + " is " + (end - start) + "ms");
Thread.sleep(1000);
}
}
}
代码逻辑及其简单,就是调用logger.info每次打印10000条日志,然后记录耗时。两者的对比如下

对比结果
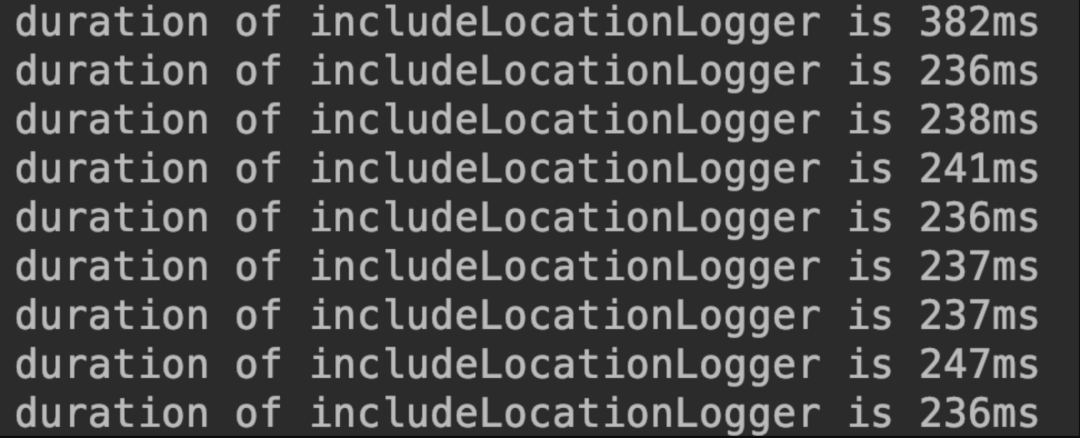
从这两张图片中我们能够看到同样的逻辑,两个程序的耗时差距相差了数十倍,但看图片,貌似仅仅是logger的名称不一样。对上面的实验结果进行分析,我们可能会有两个疑问
上面的代码测试是否标准,规范
如果真的是性能问题,那么这两个代码到底在哪个方法上有了这么大的差距导致了最终的性能差异
下面这两个工具就分别来回答这两个问题
JMH简介
第一个问题就是,测试的方法是否标准。我们在编写代码时用的是死循环+前后“掐秒表”的方式。假如我们要再加个多线程的测试,我们还需要搞一个线程池,除了代码本身的逻辑还要关心测试的逻辑。我们会想,有没有一款工具能够将我们从测试逻辑中彻底解放出来,只需要关心我们需要测试的代码逻辑。JMH就是这样一款Java的测试框架。下面是JMH的官方定义
JMH 是一个面向 Java 语言或者其他 Java 虚拟机语言的性能基准测试框架
这里面我们需要注意的是,JMH所测试的方法约简单越好,依赖越少越好,最适合的场景就是,测试两个集合put,get性能,例如ArrayList与LinkedList的对比等,这里我们需要测试的是批量打一批日志所需要的时间,也基本符合使用JMH的测试场景。下面是测试代码,bench框架代码以及主函数。
待测试方法
public class LogBenchMarkWorker {
private LogBenchMarkWorker() {}
private static class LogBenchMarkWorkerInstance {
private static final LogBenchMarkWorker instance = new LogBenchMarkWorker();
}
public static LogBenchMarkWorker getInstance() {
return LogBenchMarkWorkerInstance.instance;
}
private static final String LOGGER_DEFAULT_NAME = "defaultLogger";
private static final String LOGGER_INCLUDE_LOCATION = "includeLocationLogger";
private static final Logger LOGGER = LoggerFactory.getLogger(LOGGER_DEFAULT_NAME);
private static long BATCH_SIZE = 10000;
public void logBatch() {
for (int i = 0; i < BATCH_SIZE; i++) {
LOGGER.info("msg is {}", i);
}
}
}
可以看到待测试方法非常简单,就是单批次一次性打印10000条日志的操作,所以并没有需要额外说明的部分。下面我们再来看benchmark部分。
public class LogBenchMarkMain {
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(1)
public void testLog1() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(4)
public void testLog4() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(8)
public void testLog8() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(16)
public void testLog16() {
LogBenchMarkWorker.getInstance().logBatch();
}
在这段代码中,我们就会发现有了一些JMH中特有的东西,我下面进行简要介绍。
Benchmark注解:标识在某个具体方法上,表示这个方法将是一个被测试的最小方法,在JMH中成为一个OPS
BenmarkMode:测试类型,JMH提供了几种不同的Mode
Throughput:整体吞吐量
AverageTime:调用的平均时间,每次OPS执行的时间
SampleTime:取样,给出不同比例的ops时间,例如99%的ops时间,99.99%的ops时间
fork:fork的次数,如果设置为2,JMH会fork出两个进程来测试
Threads:很容易理解,这个参数表示这个方法同时被多少个线程执行
在上面的代码中,我定义了4个待测试的方法,方法的Fork,BenchmarkMode均为测试单次OPS的平均时间,但4个方法的线程数不同。
除了这几个参数,还有几个参数,我会在main函数里面来讲,main代码如下所示
public class Main {
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(LogBenchMarkMain.class.getSimpleName())
.warmupIterations(5)
.measurementIterations(5)
.output("logs/BenchmarkCommon.log")
.build();
new Runner(options).run();
}
}
我们可以看到,在main函数中,我们就是要设置JMH的基础配置,这里面的几个配置参数含义如下:
include:benchmark所在类的名字,可以使用正则表达
warmupIteration:预热的迭代次数,这里为什么要预热的原因是由于JIT的存在,随着代码的运行,会动态对代码的运行进行优化。因此在测试过程中需要先预热几轮,让代码运行稳定后再实际进行测试
measurementIterations:实际测试轮次
output:测试报告输出位置
我分别用两种logger运行一下测试,查看性能测试报告对比
使用普通logger
LogBenchMarkMain.testLog1 avgt 5 0.006 ± 0.001 s/op
LogBenchMarkMain.testLog16 avgt 5 0.062 ± 0.026 s/op
LogBenchMarkMain.testLog4 avgt 5 0.006 ± 0.002 s/op
LogBenchMarkMain.testLog8 avgt 5 0.040 ± 0.004 s/op
使用了INCLUDE_LOCATION的logger
LogBenchMarkMain.testLog1 avgt 5 0.379 ± 0.007 s/op
LogBenchMarkMain.testLog16 avgt 5 1.784 ± 0.670 s/op
LogBenchMarkMain.testLog4 avgt 5 0.378 ± 0.003 s/op
LogBenchMarkMain.testLog8 avgt 5 0.776 ± 0.070 s/op
这里我们看到,性能差距立现。使用INCLUDE_LOCATION的性能要明显低于使用普通logger的性能。这是我们一定很好奇,并且问一句“到底慢在哪”!!
Arthas 我的代码在运行时到底做了什么
Arthas是阿里开源的一款java调试神器,与greys类似,不过有着比greys更加强大的功能,例如,可以直接绘制java方法调用的火焰图等。这两个工具的原理都是使用了Java强大的字节码技术。毕竟我也不是JVM大佬,所以具体的实现细节没法展开,我们要做的就是站在巨人的肩膀上,接受并用熟练的使用好这些好用的性能监控工具。
实际操作
talk is cheap, show me your code,既然是工具,我们直接进行实际操作。我们在本机运行我们一开始的程序,然后讲解arthas的使用方法。
我们首先通过jps找到程序的进程号,然后直接通过arthas给到的as.sh对我们运行的程序进行字节码增强,然后启动arthas,命令如下
./as.sh pid
这个就是arthas的启动界面了,我们使用help命令查看工具所支持的功能
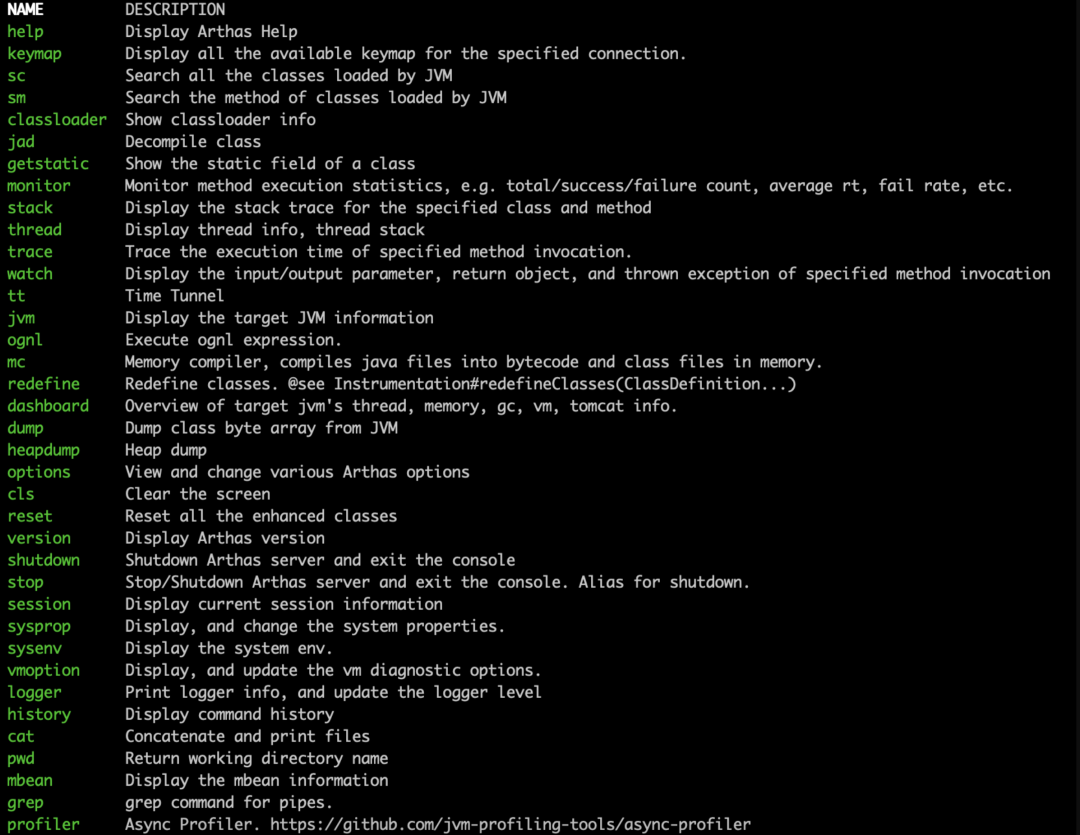
可以看到,arthas支持查看当前jvm的状态,查看当前的线程状态,监控某些方法的调用时间,trace,profile生成火焰图等,功能一应俱全
我们这里也只将几个比较常用的命令,其他的命令如果大家感兴趣可以详见官网arthas官网。这篇文章主要介绍下面几个功能
反编译代码
监控某个方法的调用
查看某个方法的调用和返回值
trace某个方法
监控方法调用
这个主要的命令为monitor,根据官网的介绍,常用的使用方法为
monitor -c duration className methodName
其中duration代表每隔几秒展示一次统计结果,即单次的统计周期,className就是类的全限定名,methodname就是方法的名字,这里面我们查看的方法是Logger类的info方法,我们分别对使用两种不同logger的info方法。这里面的类是org.slf4j.Logger,方法时info,我们的监控语句为
monitor -c 5 org.slf4j.Logger info
监控结果如下
使用普通appender
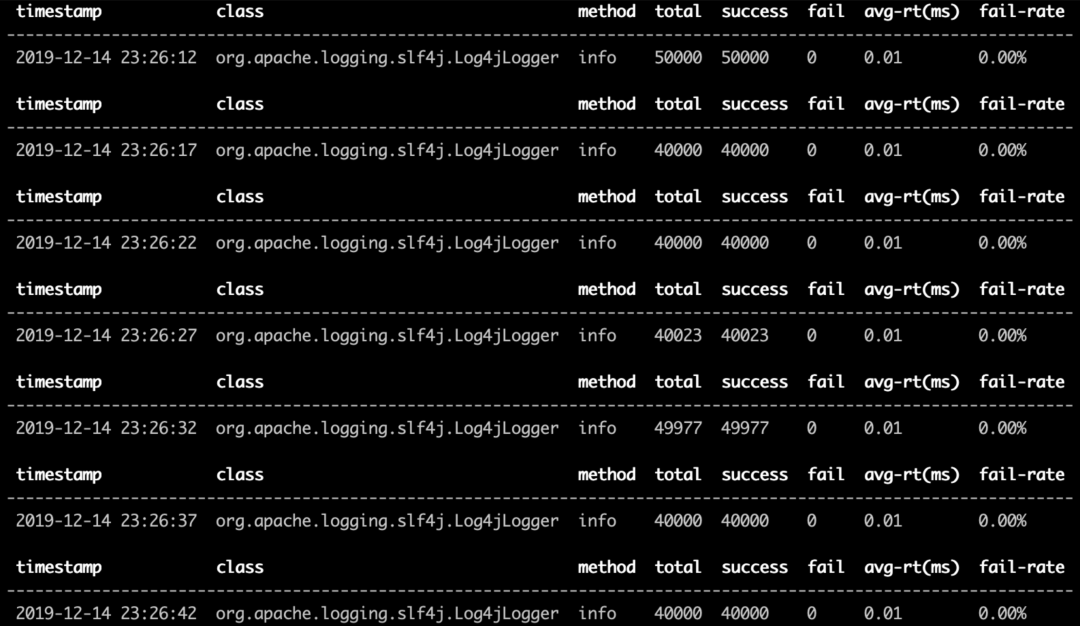
使用include appender
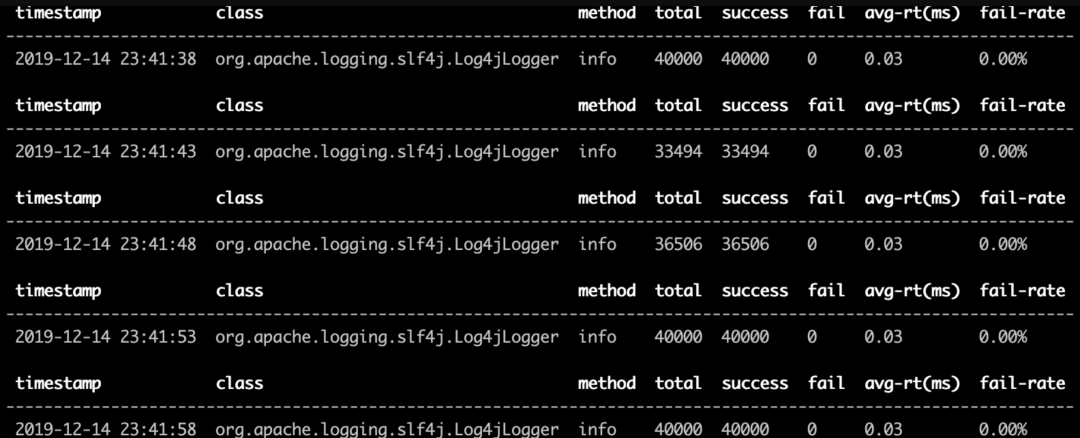
我们可以看到,使用include appeder的打印日志方法要比普通的appender高出了3倍,这就不禁让我们有了疑问,究竟这两个方法各个步骤耗时如何呢。下面我们就介绍第二条命令,trace方法。
trace命令 & jad命令
这两个程序的log4j2配置文件如下
<configuration status="warn" monitorInterval="30">
<appenders>
<Console name="console" target="SYSTEM_OUT">
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss.SSS}] [%-5p] %l - %m%n"/>
Console>
<Async name="AsyncDefault" blocking="false" includeLocation="false">
<AppenderRef ref="fileAppender"/>
Async>
<Async name="AsyncIncludeLocation" blocking="false" includeLocation="true">
<AppenderRef ref="fileAppender"/>
Async>
<File name="fileAppender" fileName="log/test.log" append="false">
<PatternLayout pattern="[%d{HH:mm:ss.SSS}] [%-5p] %l - %m%n"/>
File>
<File name="ERROR" fileName="logs/error.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{yyyy.MM.dd 'at' HH:mm:ss z}] [%-5p] %l - %m%n"/>
File>
<RollingFile name="rollingFile" fileName="logs/app.log"
filePattern="logs/$${date:yyyy-MM}/web-%d{yyyy-MM-dd}.log.gz">
<PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss}] [%-5p] %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
Policies>
<DefaultRolloverStrategy>
<Delete basePath="logs" maxDepth="2">
<IfFileName glob="*/*.log.gz" />
<IfLastModified age="7d" />
Delete>
DefaultRolloverStrategy>
RollingFile>
appenders>
<loggers>
<logger name="defaultLogger" additivity="false">
<appender-ref ref="AsyncDefault">appender-ref>
logger>
<logger name="includeLocationLogger" additivity="false">
<appender-ref ref="AsyncIncludeLocation">appender-ref>
logger>
<root level="INFO">
root>
loggers>
configuration>
我们都是用了一个AsyncAppender套用了一个FileAppender。查看fileAppender,发现二者相同完全没区别,只有asyncAppender中的一个选项有区别,这就是includeLocation,一个是false,另一个是true。至于这个参数的含义,我们暂时不讨论,我们现在知道问题可能出在AsyncAppender里面,但是我们该如何验证呢。trace命令就有了大用场。
trace命令的基本用法与monitor类似,其中主要的一个参数是-n则是代表trace多少次的意思
trace -n trace_times className methodName
我在之前Log4j2的相关博客里面讲到过,任何一个appender,最核心的方法就是他的append方法。所以我们分别trace两个程序的append方法。
trace -n 5 org.apache.logging.log4j.core.appender.AsyncAppender append
trace结果如下
使用普通appender
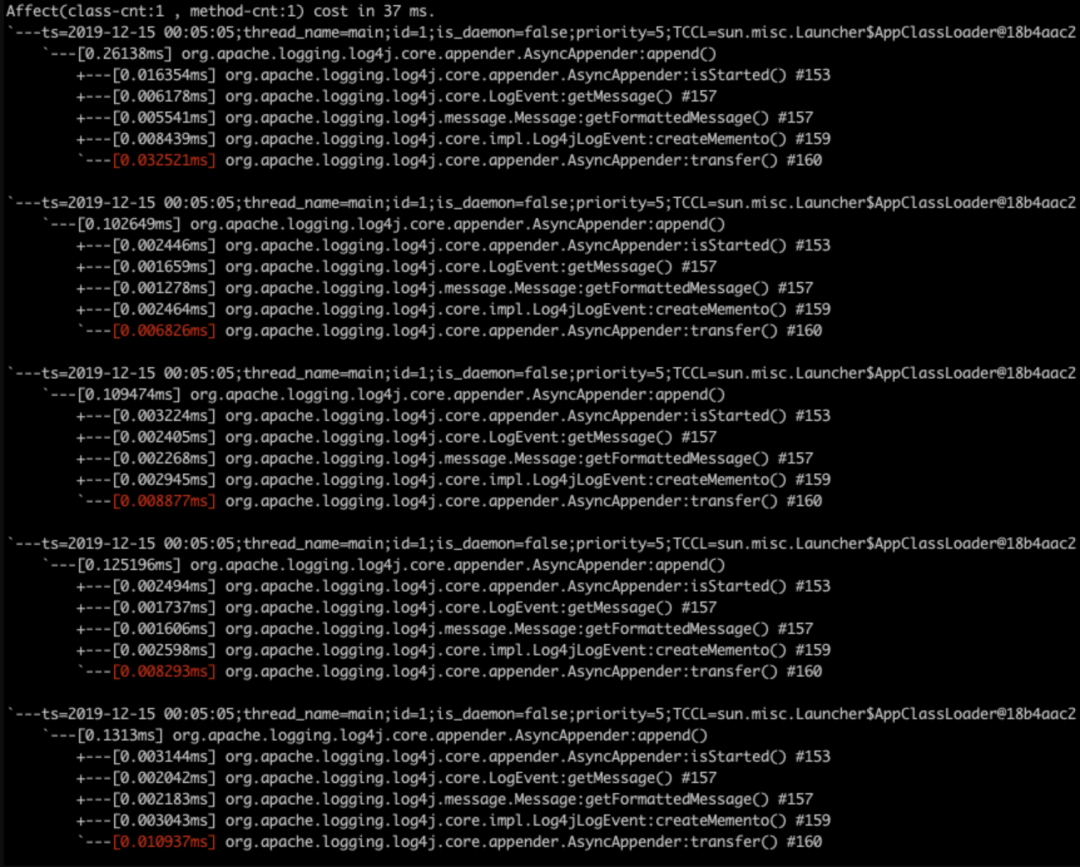
使用include appender
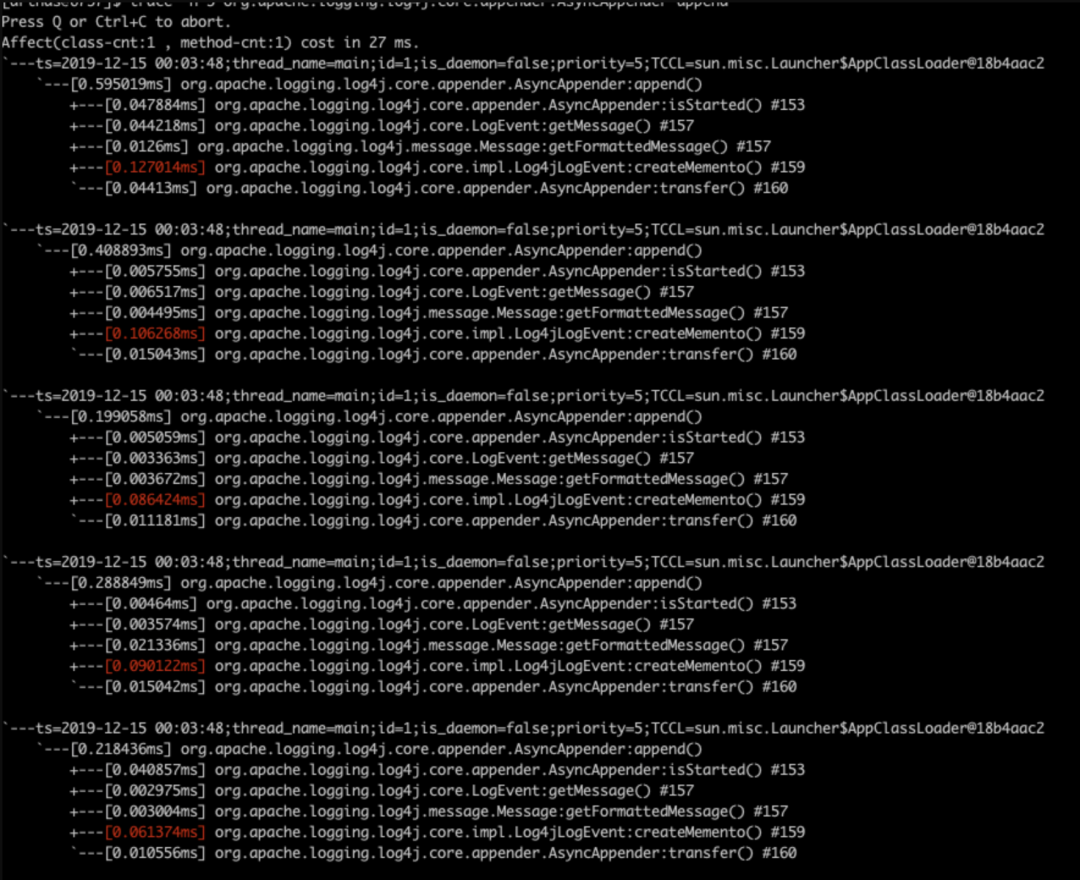
我们立刻可以发现,两个trace的热点方法不一样,在使用include的appender中,耗时最长的方法时org.apache.logging.log4j.core.impl.Log4jLogEvent类中的createMemento方法,那么怎么才能知道这个方法到底做了啥呢,那就请出我们下一个常用命令jad,这个命令能够反编译出对应方法的代码。这里我们jad一下上面说的那个createMemento方法,命令很简单
jad org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento
结果如下

我们发现,这个方法中有个includeLocation参数,这个和我们的看到的两个appender的唯一不同的配置相吻合,我们此时应该有这个猜想,会不会就是这个参数导致的呢?为了验证这个猜想,我们引出下一个命令,watch
watch命令
watch命令能够观察到某个特定方法的入参,返回值等信息,我们使用这个命令查看一下这个createMemento方法的入参,如果两个程序的入参不同,那基本可以断定是这个原因引起命令如下
watch org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento "params" -x 2 -n 5 -b -f
这里面的参数含义如下
-x 参数展开层次
-n 执行次数
-b 查看方法调用前状态
-f 方法调用后
其中的param代表查看方法的调用参数列表,还有其他的监控项详见官网官网
最终watch结果如下
使用普通logger
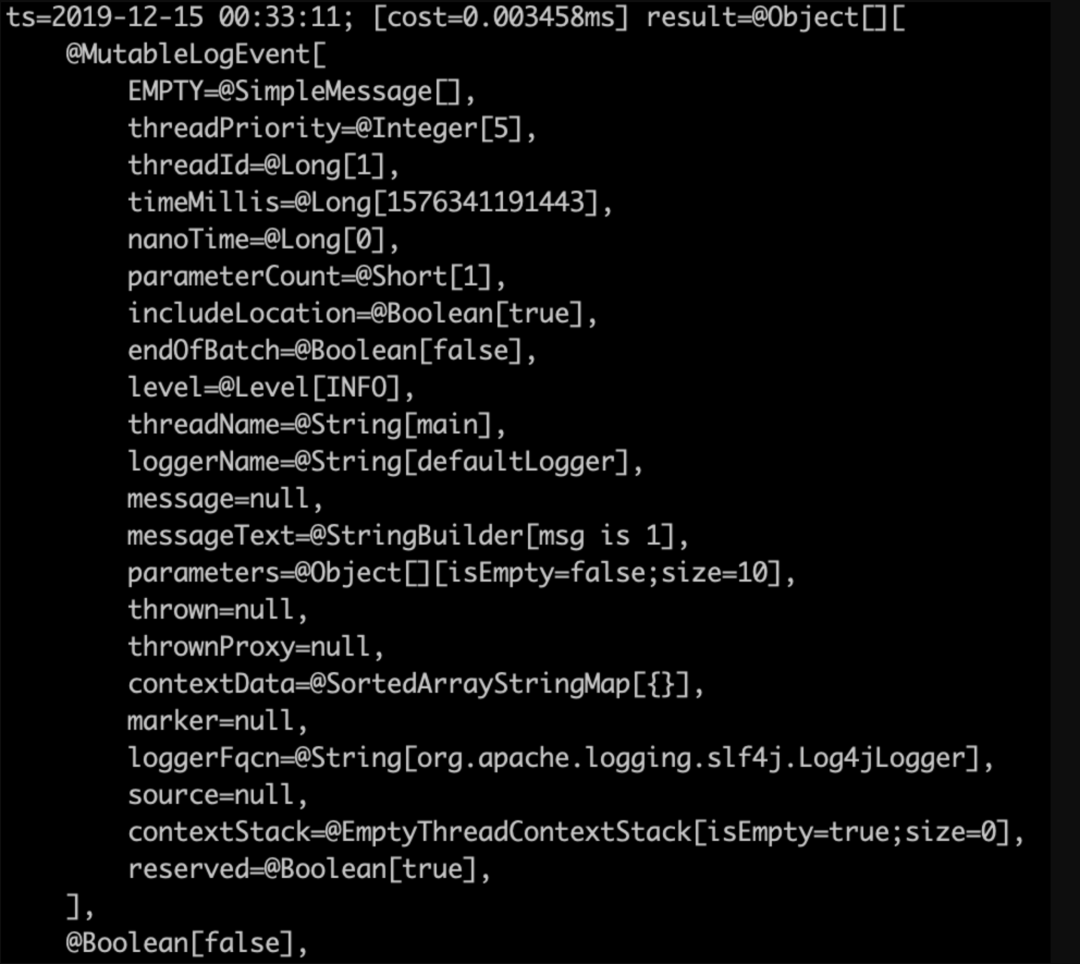
使用include
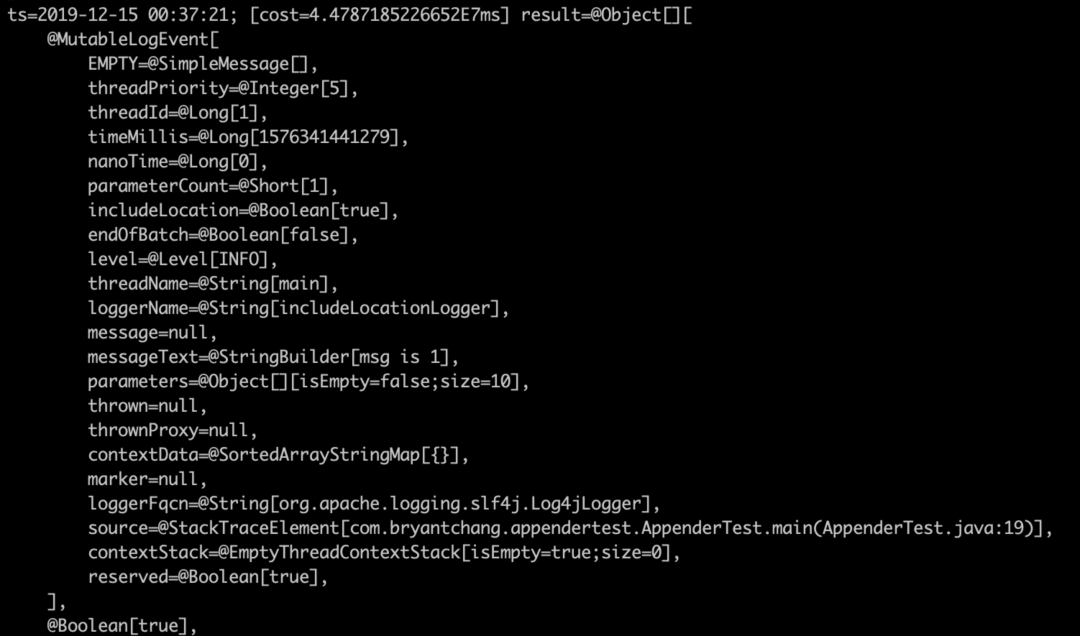
果不其然,这两个参数果然是一个true一个false,我们简单看下这个参数是如何传进来的,我们jad一下AsyncAppender的append方法
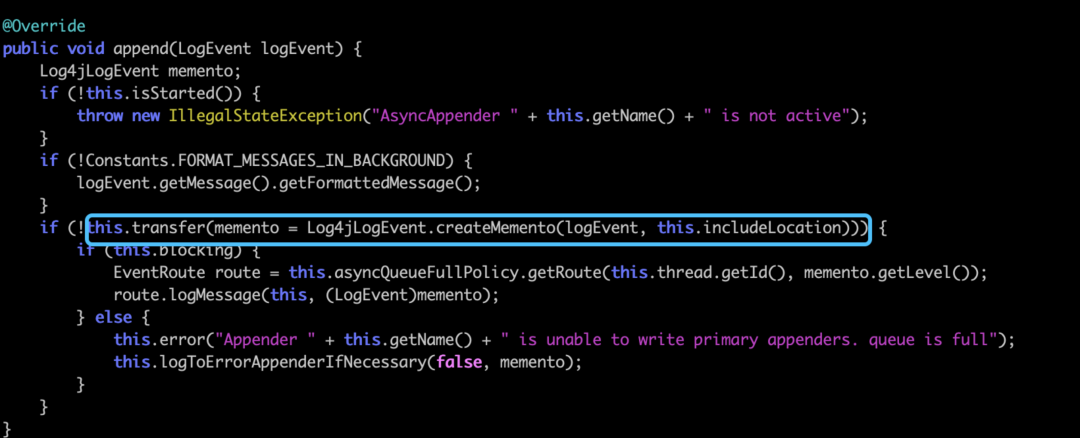
我们发现这个includeLocation正是appender的一个属性,也就是我们xml中配置的那个属性。查看官网的相关分析,我们看到这个参数会使log的性能下降5–10倍

不过为了一探究竟,我还是静态跟了一下这段代码
这个includeLocation会在event的createMemento中被用到,在序列化生成对象时会创建一个LogEventProxy,代码如下
public LogEventProxy(final LogEvent event, final boolean includeLocation) {
this.loggerFQCN = event.getLoggerFqcn();
this.marker = event.getMarker();
this.level = event.getLevel();
this.loggerName = event.getLoggerName();
final Message msg = event.getMessage();
this.message = msg instanceof ReusableMessage
? memento((ReusableMessage) msg)
: msg;
this.timeMillis = event.getTimeMillis();
this.thrown = event.getThrown();
this.thrownProxy = event.getThrownProxy();
this.contextData = memento(event.getContextData());
this.contextStack = event.getContextStack();
this.source = includeLocation ? event.getSource() : null;
this.threadId = event.getThreadId();
this.threadName = event.getThreadName();
this.threadPriority = event.getThreadPriority();
this.isLocationRequired = includeLocation;
this.isEndOfBatch = event.isEndOfBatch();
this.nanoTime = event.getNanoTime();
}
如果includeLocation为true,那么就会调用getSource函数,跟进去查看,代码如下
public StackTraceElement getSource() {
if (source != null) {
return source;
}
if (loggerFqcn == null || !includeLocation) {
return null;
}
source = Log4jLogEvent.calcLocation(loggerFqcn);
return source;
}
public static StackTraceElement calcLocation(final String fqcnOfLogger) {
if (fqcnOfLogger == null) {
return null;
}
// LOG4J2-1029 new Throwable().getStackTrace is faster than Thread.currentThread().getStackTrace().
final StackTraceElement[] stackTrace = new Throwable().getStackTrace();
StackTraceElement last = null;
for (int i = stackTrace.length - 1; i > 0; i--) {
final String className = stackTrace[i].getClassName();
if (fqcnOfLogger.equals(className)) {
return last;
}
last = stackTrace[i];
}
return null;
}
我们看到他会从整个的调用栈中去寻找调用这个方法的代码行,其性能可想而知。我们用arthas监控一下,验证一下。
首先我们trace crateMemento方法
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento

发现热点方法时org.apache.logging.log4j.core.impl.Log4jLogEvent的serialize(),继续trace下去
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent serialize

看到热点是org.apache.logging.log4j.core.impl.Log4jLogEvent:LogEventProxy的构造方法,继续trace
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent$LogEventProxy
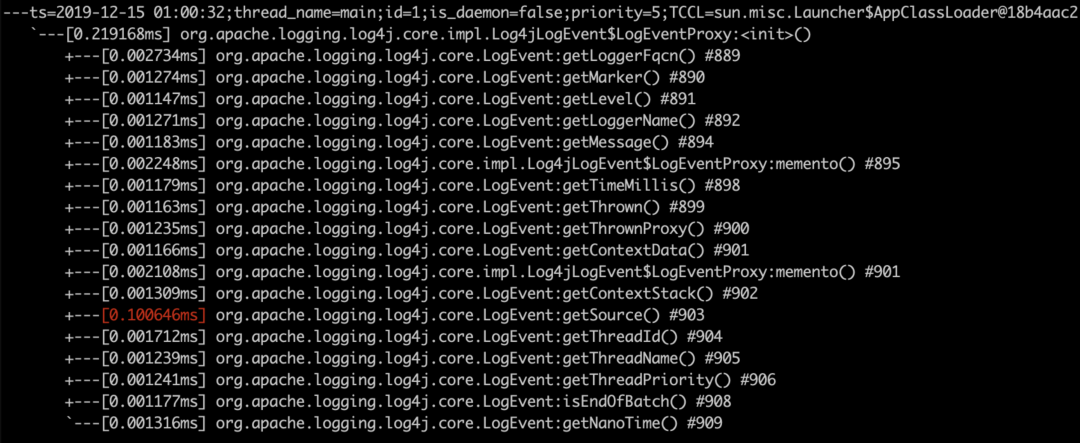
发现是getSource方法,继续
trace -n 5 trace -n 5 org.apache.logging.log4j.core.LogEvent getSource

热点终于定位到了,是org.apache.logging.log4j.core.impl.Log4jLogEvent的calcLocation函数,和我们静态跟踪的代码一样。
至此我们通过结合JMH和arthas共同定位出了一个线上的性能问题。不过我介绍的只是冰山一角,更多常用的命令还希望大家通过官网自己了解和实践,有了几次亲身实践之后,这个工具也就玩熟了。
转自:https://bryantchang.github.io/2019/12/08/java-profile-tools/