
使用 jvm-profiler 分析 spark 内存使用
背景
在生产环境中,为了提高任务提交的响应速度,我们研发了类似 Spark Jobserver 的服务,各种类型的 spark 任务复用已经启动的 Spark Application,避免了 sparkContext 初始化冷启动的过程。
可复用Spark服务的内存是固定的,因此又开放了用户自定义 Executor 内存的权限,用户为了避免自己的任务因内存不足而失败,往往会把内存设置的很大,从而带来了内存滥用的问题。
jvm-profiler
一般来说监控 spark 内存有2种方式
通过 Spark ListenerBus 获取 Executor 内部的内存使用情况 ,现在能获取的相关信息还比较少,在 https://github.com/apache/spark/pull/21221 合进来后就能采集到executor 内存各个逻辑分区的使用情况。
通过 Spark Metrics 将 JVM 信息发送到指定的 sink,用户也可以自定义 Sink 比如发送到 kafka/Redis。
Uber 最近开源了 jvm-profiler,采集分布式JVM应用信息,可以用于 debug CPU/mem/io 或者方法调用的时间等。比如调整Spark JVM 内存大小,监控 HDFS Namenode RPC 延时,分析数据血缘关系。
应用于 Spark 比较简单
每5S采集一次JVM信息,发送到 kafka profiler_CpuAndMemory topic
hdfs dfs -put jvm-profiler-0.0.9.jar hdfs://hdfs_url/lib/jvm-profiler-0.0.9.jar--conf spark.jars=hdfs://hdfs_url/lib/jvm-profiler-0.0.9.jar--conf spark.executor.extraJavaOptions=-javaagent:jvm-profiler-0.0.9.jar=reporter=com.uber.profiling.reporters.KafkaOutputReporter,metricInterval=5000,brokerList=brokerhost:9092,topicPrefix=profiler_
消费后存入HDFS用于分析。
分析
hive 表结构

对用户自定义内存的任务进行分析
用户自定义内存调度任务,75%的任务内存使用率低于80%,可以进行优化。
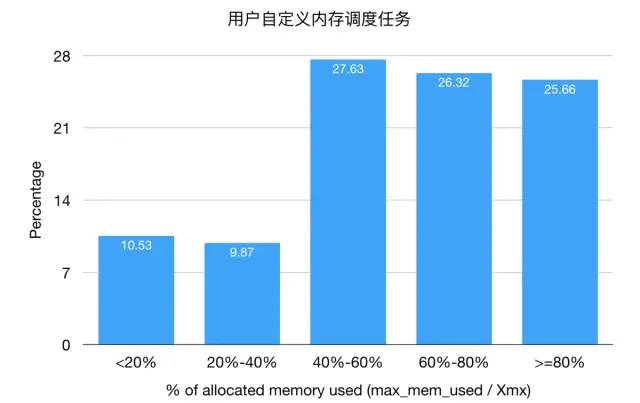
用户自定义内存调度任务
用户自定义内存开发任务,45%的任务内存使用率低于20%,用户存在不良使用习惯。
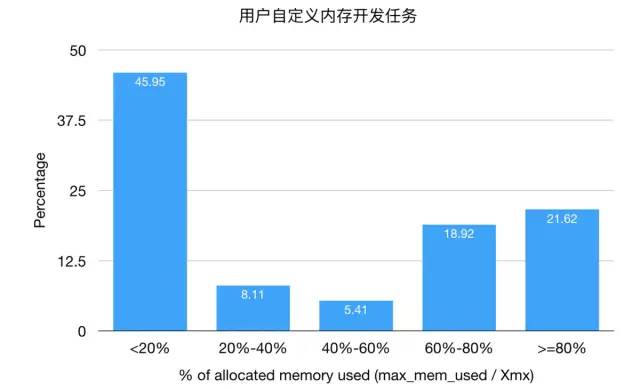
用户自定义内存开发任务
总结
通过采集 jvm 的最大使用值和设定值,可以解决下述问题。
内存滥用
监控应用内存使用趋势,防止数据增长导致内存不足
Spark Executor 默认内存设置不合理
根据应用的使用预计内存减少情况
executor 默认内存减少10%,平均每个任务能释放 60G 内存
自定义内存调度任务利用率提高到 70%,平均每个任务能释放 450G 内存
自定义内存开发任务利用率提高到 70%,平均每个任务能释放 550G 内存
参考
JVM Profiler: An Open Source Tool for Tracing Distributed JVM Applications at Scale
https://www.jianshu.com/p/09e2ccacfc26