
SpringBoot 实现 MySQL 读写分离技术

阅读本文大概需要 6 分钟。
来自:cnblogs.com/wyq178/p/13352707.html
前言
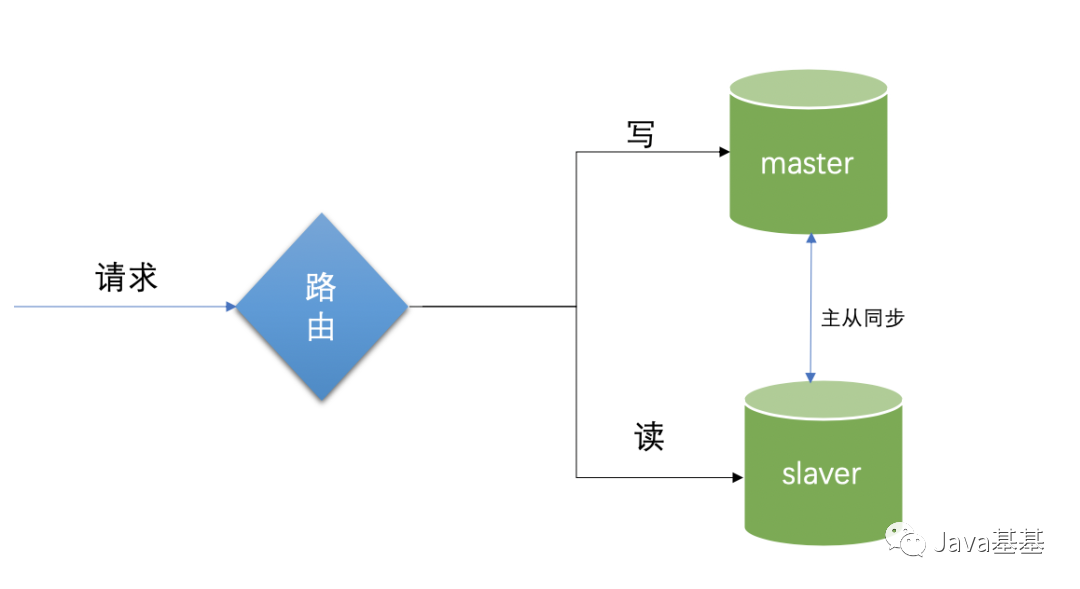
一: 主从数据源的配置
/**
* 主从配置
*
* @author wyq
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}
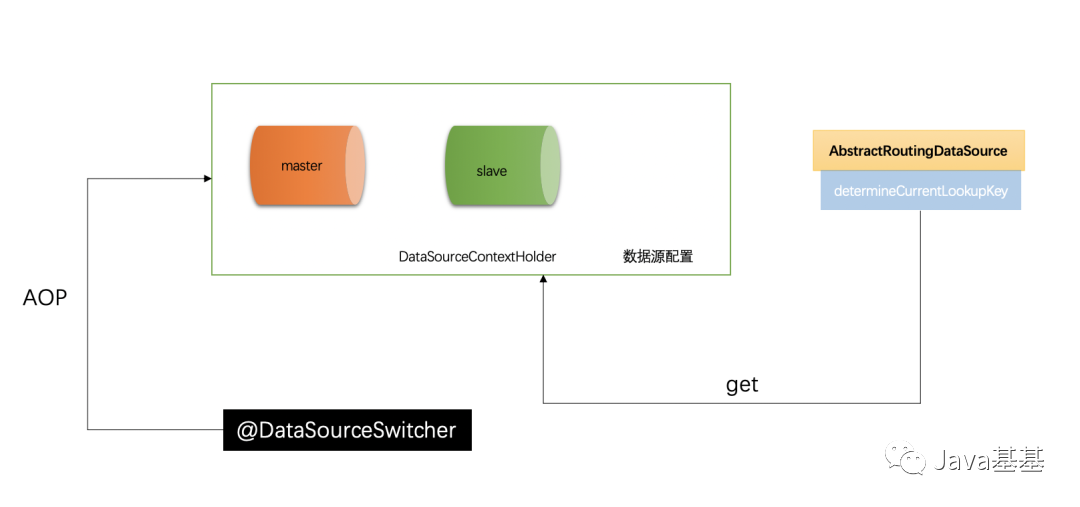
二: 数据源路由的配置
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}
三:数据源上下文环境
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}
四:切换注解和 Aop 配置
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}
五:用法以及测试
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}
六:总结
推荐阅读:
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 