
本地缓存天花板— caffeine了解下?
前言
最近,我们在重构公司的一个项目(我好像已经说了好多次了,这个项目周期确实比较长),由于一个应用场景并发量特别高,目前设计的并发量为10万,虽然有用redis作为数据库来存储数据,性能上应该问题不大,但是为了更大性能保证系统性能,我们又在系统中加入了本地化缓存,关于本地缓存,目前的组件比较多,除了MemoryCache之外,guava也有本地缓存解决方案,但是我们用的是caffeine,关于这个组件我大概查了下(之前还真没听说过,有点孤陋寡闻了),发现它的性能确实强,性能是guava本地缓存的好几倍,今天我们就来一次caffeine破冰。
caffeine
是什么
caffeine是一款高性能的本地缓存组件,关于它的定义,官方描述如下:
Caffeine is a high performance, near optimal caching library.
简单翻一下就是:Caffeine是一款高性能、最优缓存库。
定义很是简洁,同时文档中也说明了caffeine是受Google guava启发的本地缓存(青出于蓝而胜于蓝),在Cafeine的改进设计中借鉴了 Guava 缓存和 ConcurrentLinkedHashMap
项目地址
https://github.com/ben-manes/caffeine
如何用
下面我们结合官方文档看下,如何在我们的项目中使用Caffeine。首先我们需要在项目中增加Caffeine的依赖,这里以maven为例,其他管理工具可以参考官方文档:
<dependency>
<groupId>com.github.ben-manes.caffeinegroupId>
<artifactId>caffeineartifactId>
<version>3.0.5version>
dependency>
Caffeine提供了四种缓存添加策略:
- 手动加载
- 自动加载
- 手动异步加载
- 自动异步加载
值得表扬的是,官方文档提供了中文支持,对不习惯看英文文档的小伙伴简直就是福音,中文文档地址如下:
https://github.com/ben-manes/caffeine/wiki/Population-zh-CN
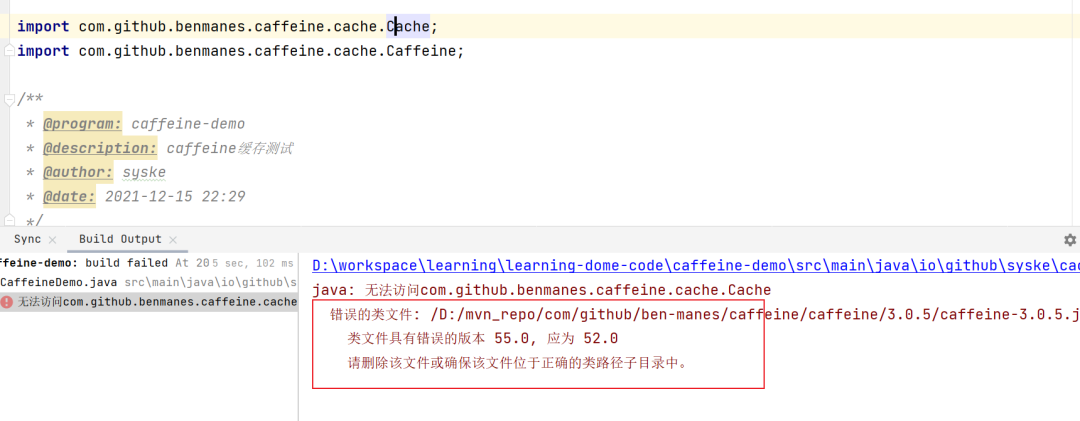
这里需要注意的是,Caffeine的版本需要和JDK对应,比如最新版本(3.0.5)对应的jdk为11,如果jdk版本太低,会报如下错误:
手动加载
手动加载其实就是通过官方提供的api,比如get、put、invalidate等接口,手动操作缓存,关于这块的详细描述,官方文档也给出了详细说明,所以我就直接引用了:
Cache接口提供了显式搜索查找、更新和移除缓存元素的能力。缓存元素可以通过调用
cache.put(key, value)方法被加入到缓存当中。如果缓存中指定的key已经存在对应的缓存元素的话,那么先前的缓存的元素将会被直接覆盖掉。因此,通过cache.get(key, k -> value)的方式将要缓存的元素通过原子计算的方式 插入到缓存中,以避免和其他写入进行竞争。值得注意的是,当缓存的元素无法生成或者在生成的过程中抛出异常而导致生成元素失败,cache.get也许会返回null。当然,也可以使用Cache.asMap()所暴露出来的ConcurrentMap的方法对缓存进行操作。
下面是手动加载的示例,我是在官方示例的基础上做了小调整:
Cache cache =
Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(10_000).build();
String key = "hello_caffeine";
// 查找一个缓存元素, 没有查找到的时候返回null
Object object = cache.getIfPresent(key);
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回null
object = cache.get(key, k -> createObject(key));
// 添加或者更新一个缓存元素
cache.put(key, object);
// 移除一个缓存元素
cache.invalidate(key);
System.out.println(cache);
}
private static Object createObject(String key) {
return "hello caffeine 2021";
}
自动加载
自动加载,顾名思义就是查不到数据时,系统会自动帮我们生成元素的缓存,只是这里构建的是LoadingCache,同时需要指定元素缓存的构造方法(也就是获取对象的方式,比如查库获取)
// 自动加载
LoadingCache cache2 = Caffeine.newBuilder().maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES).build(CaffeineDemo::createObject);
String key2 = "hello2";
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回null
Object value = cache2.get(key2);
System.out.println(value);
List keys = new ArrayList<>();
keys.add("hello1");
keys.add("hello2");
// 批量查找缓存,如果缓存不存在则生成缓存元素
Map objectMap = cache2.getAll(keys);
System.out.println(objectMap);
private static Object createObject(String key) {
return "hello caffeine 2021";
}
手动异步加载
手动异步加载和手动加载类似,唯一的区别是这里的缓存加载是异步的。AsyncCache提供了在 Executor上生成缓存元素并返回 CompletableFuture的能力,synchronous()方法给 Cache提供了阻塞直到异步缓存生成完毕的能力。
AsyncCache默认的线程池实现是 ForkJoinPool.commonPool(),当然你也可以通过覆盖并实现 Caffeine.executor(Executor)方法来自定义你的线程池选择。
// 手动异步加载
AsyncCache cache3 = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.buildAsync();
// 查找一个缓存元素, 没有查找到的时候返回null
CompletableFuture 自动异步加载
自动异步加载和自动加载对应,只是这里的加载是异步的,和手动异步加载一样,当然因为是自动加载,所以需要我们指定缓存加载方法。默认情况下,采用的线程池也是ForkJoinPool.commonPool(),另外自动异步加载也支持自定义线程池类型。
// 自动异步加载
AsyncLoadingCache cache4 = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
// 你可以选择: 去异步的封装一段同步操作来生成缓存元素
.buildAsync(key3 -> createObject(key3));
// 你也可以选择: 构建一个异步缓存元素操作并返回一个future
// .buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
// 查找缓存元素,如果其不存在,将会异步进行生成
CompletableFuture 关于缓存的添加我们暂时就说这么多,下面我们看下Caffeine缓存的属性参数。
属性参数
- 缓存数量
通过maximumSize指定缓存的最大存储数量,在缓存达到该限制会移除最近没有用过,或者使用频次较低的缓存,当然在达到缓存的临界点时,可能会出现暂时超出限制的情况。如果该值被设置为0,则缓存在加载后后会立即失效(类似于禁用)
- 写入过期时间
在构建Caffeine实例的时候,我们需要通过expireAfterWrite方法指定缓存的过期时间,指定具体时间的同时还需要指定时间的单位。
- 访问后过期时间
通过expireAfterAccess设置访问后过期时间。
- 创建后过期时间
通过expireAfter设置创建后过期时间。
- 写入后刷新时间
通过refreshAfterWrite设置多久之后刷新缓存。
更多属性,各位小伙伴可以参考官方文档和源码。
结语
但从官方文档来看,这块缓存组件的性能还是非常棒的:
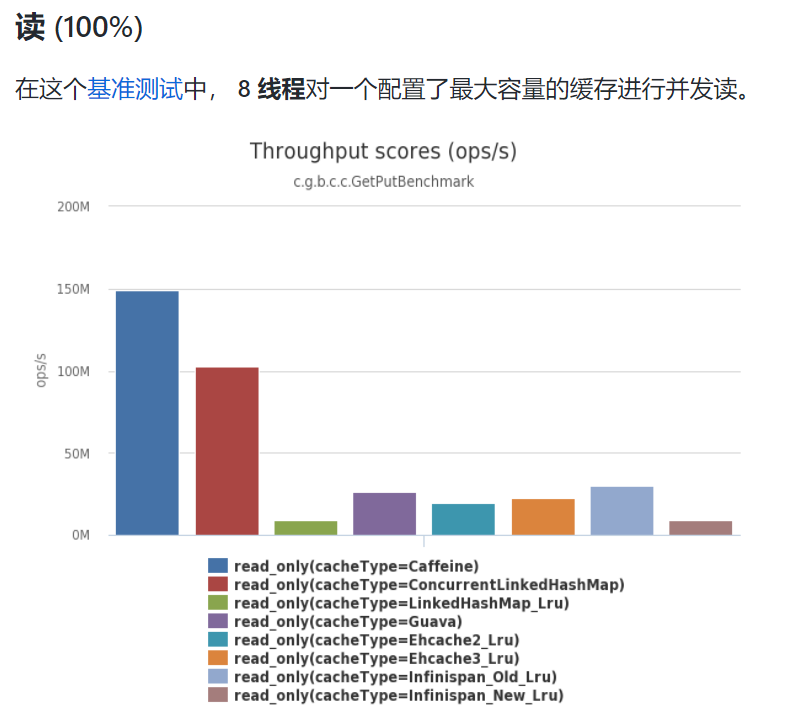
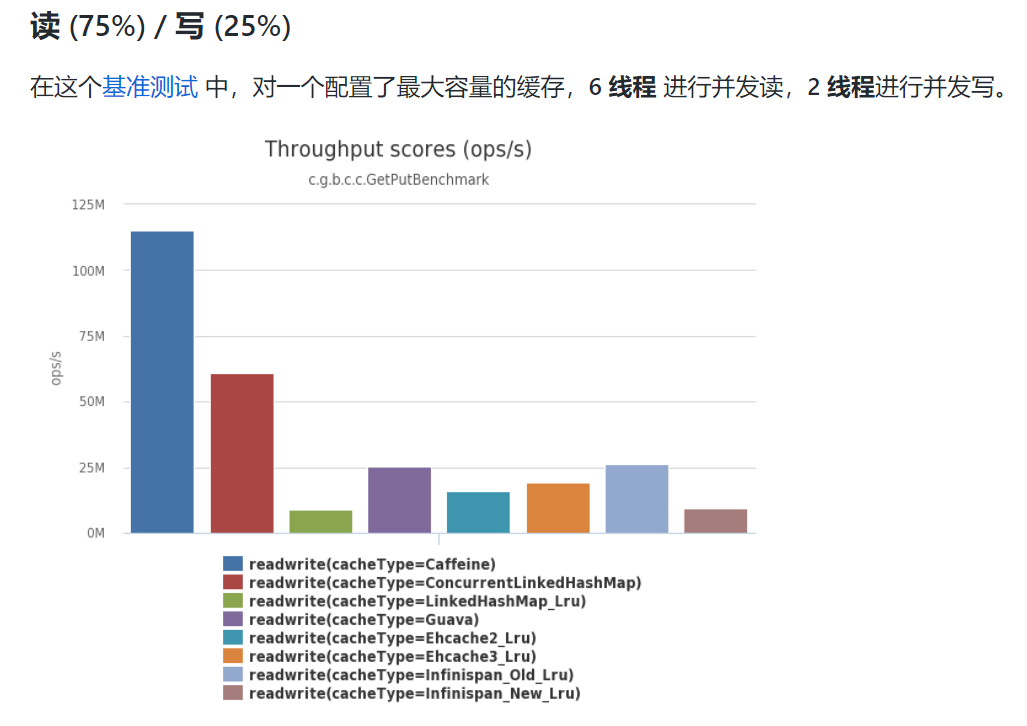
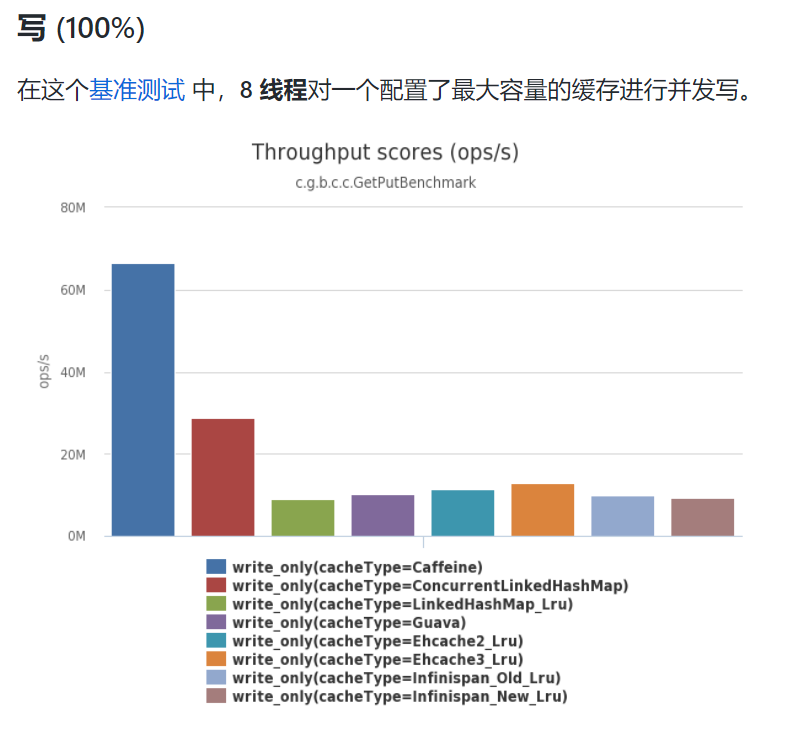
当然一款工具是否好用,往往是需要经得起实践检验的,而不仅仅简单的测试,所以Caffeine是否好用,还得我们自己亲自实测。
最后,由于内容篇幅和时间的限制,我们这里只能做一个简单的分享,更多详细内容还需要各位小伙伴自己探索,毕竟实践出真知。好了,各位小伙伴,晚安吧!
- END -