
2W 字图解 Redis,面试必过必杀技!!
(给架构师修行之路加星标,提升数据技能)
来源:业余草
http://dwz.date/dTu5
今天,“我”不自量力的面试了某大厂的 开发岗位,迎面走来一位风尘仆仆的中年男子,手里拿着屏幕还亮着的 Mac。他冲着我礼貌的笑了笑,然后说了句“不好意思,让你久等了”,然后示意我坐下,说:“我们开始吧,看了你的简历,觉得你对 Redis 应该掌握的不错,我们今天就来讨论下 Redis……”。我想:“来就来,兵来将挡水来土掩”。
Redis 是什么
面试官:你先来说下 Redis 是什么吧!
我:(这不就是总结下 Redis 的定义和特点嘛)Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能键值对(key-value)的内存数据库,可以用作数据库、缓存、消息中间件等。
它是一种 NoSQL(not-only sql,泛指非关系型数据库)的数据库。
我顿了一下,接着说,Redis 作为一个内存数据库:
性能优秀,数据在内存中,读写速度非常快,支持并发 10W QPS。
单进程单线程,是线程安全的,采用 IO 多路复用机制。
丰富的数据类型,支持字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
支持数据持久化。
可以将内存中数据保存在磁盘中,重启时加载。
主从复制,哨兵,高可用。
可以用作分布式锁。
可以作为消息中间件使用,支持发布订阅。
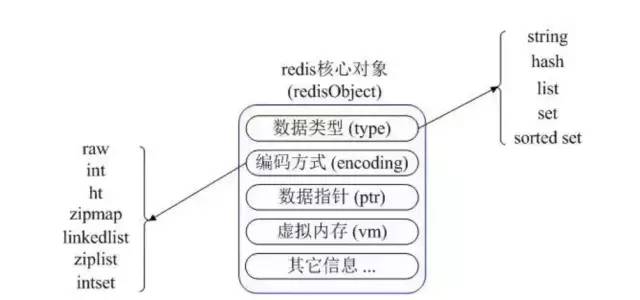
五种数据类型
说着,我拿着笔给面试官画了一张图:
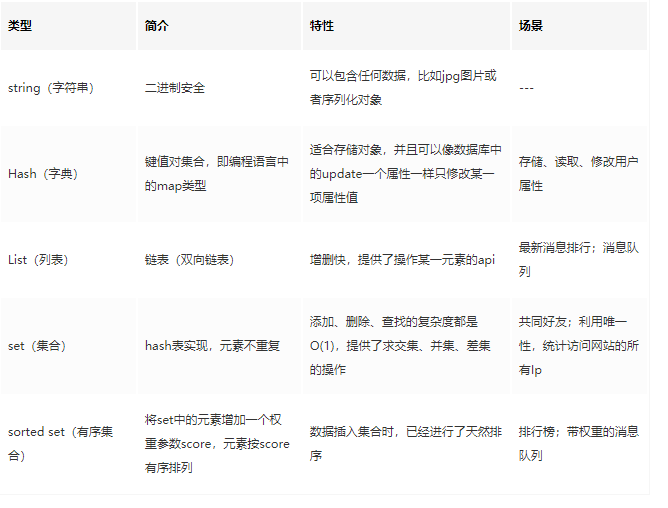
数据类型应用场景总结:
Redis 缓存
直接通过 RedisTemplate 来使用,使用 Spring Cache 集成 Redis pom.xml 中加入以下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.sessiongroupId>
<artifactId>spring-session-data-redisartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
配置文件 application.yml 的配置:
server:
port: 8082
servlet:
session:
timeout: 30ms
spring:
cache:
type: redis
redis:
host: 127.0.0.1
port: 6379
password:
# redis默认情况下有16个分片,这里配置具体使用的分片,默认为0
database: 0
lettuce:
pool:
# 连接池最大连接数(使用负数表示没有限制),默认8
max-active: 100
创建实体类 User.java:
public class User implements Serializable{
private static final long serialVersionUID = 662692455422902539L;
private Integer id;
private String name;
private Integer age;
public User() {
}
public User(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
RedisTemplate 的使用方式
添加配置类 RedisCacheConfig.java:
@Configuration
@AutoConfigureAfter(RedisAutoConfiguration.class)
public class RedisCacheConfig {
@Bean
public RedisTemplate redisCacheTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate template = new RedisTemplate<>();
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setConnectionFactory(connectionFactory);
return template;
}
}
测试类:
@RestController
@RequestMapping("/user")
public class UserController {
public static Logger logger = LogManager.getLogger(UserController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisCacheTemplate;
@RequestMapping("/test")
public void test() {
redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25));
User user = (User) redisCacheTemplate.opsForValue().get("userkey");
logger.info("当前获取对象:{}", user.toString());
}
然后在浏览器访问,观察后台日志 http://localhost:8082/user/test

使用 Spring Cache 集成 Redis
public interface UserService {
User save(User user);
void delete(int id);
User get(Integer id);
}
接口实现类 UserServiceImpl.java:
@Service
public class UserServiceImpl implements UserService{
public static Logger logger = LogManager.getLogger(UserServiceImpl.class);
private static Map userMap = new HashMap<>();
static {
userMap.put(1, new User(1, "肖战", 25));
userMap.put(2, new User(2, "王一博", 26));
userMap.put(3, new User(3, "杨紫", 24));
}
@CachePut(value ="user", key = "#user.id")
@Override
public User save(User user) {
userMap.put(user.getId(), user);
logger.info("进入save方法,当前存储对象:{}", user.toString());
return user;
}
@CacheEvict(value="user", key = "#id")
@Override
public void delete(int id) {
userMap.remove(id);
logger.info("进入delete方法,删除成功");
}
@Cacheable(value = "user", key = "#id")
@Override
public User get(Integer id) {
logger.info("进入get方法,当前获取对象:{}", userMap.get(id)==null?null:userMap.get(id).toString());
return userMap.get(id);
}
}
@Cachable
@CachePut
@CacheEvict
测试类:UserController
@RestController
@RequestMapping("/user")
public class UserController {
public static Logger logger = LogManager.getLogger(UserController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisCacheTemplate;
@Autowired
private UserService userService;
@RequestMapping("/test")
public void test() {
redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25));
User user = (User) redisCacheTemplate.opsForValue().get("userkey");
logger.info("当前获取对象:{}", user.toString());
}
@RequestMapping("/add")
public void add() {
User user = userService.save(new User(4, "李现", 30));
logger.info("添加的用户信息:{}",user.toString());
}
@RequestMapping("/delete")
public void delete() {
userService.delete(4);
}
@RequestMapping("/get/{id}")
public void get(@PathVariable("id") String idStr) throws Exception{
if (StringUtils.isBlank(idStr)) {
throw new Exception("id为空");
}
Integer id = Integer.parseInt(idStr);
User user = userService.get(id);
logger.info("获取的用户信息:{}",user.toString());
}
}
用缓存要注意,启动类要加上一个注解开启缓存:
@SpringBootApplication(exclude=DataSourceAutoConfiguration.class)
@EnableCaching
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
①先调用添加接口:http://localhost:8082/user/add

②再调用查询接口,查询 id=4 的用户信息:

可以看出,这里已经从缓存中获取数据了,因为上一步 add 方法已经把 id=4 的用户数据放入了 Redis 缓存 3、调用删除方法,删除 id=4 的用户信息,同时清除缓存:

④再次调用查询接口,查询 id=4 的用户信息:

缓存注解
Key:缓存的 Key,可以为空,如果指定要按照 SPEL 表达式编写,如果不指定,则按照方法的所有参数进行组合。
Value:缓存的名称,必须指定至少一个(如 @Cacheable (value='user')或者 @Cacheable(value={'user1','user2'}))
Condition:缓存的条件,可以为空,使用 SPEL 编写,返回 true 或者 false,只有为 true 才进行缓存。
Key:同上。
Value:同上。
Condition:同上。
allEntries:是否清空所有缓存内容,缺省为 false,如果指定为 true,则方法调用后将立即清空所有缓存。
beforeInvocation:是否在方法执行前就清空,缺省为 false,如果指定为 true,则在方法还没有执行的时候就清空缓存。缺省情况下,如果方法执行抛出异常,则不会清空缓存。
缓存问题
我:处理缓存雪崩简单,在批量往 Redis 存数据的时候,把每个 Key 的失效时间都加个随机值就好了,这样可以保证数据不会再同一时间大面积失效。
setRedis(key, value, time+Math.random()*10000);
缓存击穿的话,设置热点数据永不过期,或者加上互斥锁就搞定了。作为暖男,代码给你准备好了,拿走不谢。
public static String getData(String key) throws InterruptedException {
//从Redis查询数据
String result = getDataByKV(key);
//参数校验
if (StringUtils.isBlank(result)) {
try {
//获得锁
if (reenLock.tryLock()) {
//去数据库查询
result = getDataByDB(key);
//校验
if (StringUtils.isNotBlank(result)) {
//插进缓存
setDataToKV(key, result);
}
} else {
//睡一会再拿
Thread.sleep(100L);
result = getData(key);
}
} finally {
//释放锁
reenLock.unlock();
}
}
return result;
}
Redis 为何这么快
Redis 完全基于内存,绝大部分请求是纯粹的内存操作,非常迅速,数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度是 O(1)。
数据结构简单,对数据操作也简单。
采用单线程,避免了不必要的上下文切换和竞争条件,不存在多线程导致的 CPU 切换,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。
使用多路复用 IO 模型,非阻塞 IO。
Redis 和 Memcached 的区别
存储方式上:Memcache 会把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。Redis 有部分数据存在硬盘上,这样能保证数据的持久性。
数据支持类型上:Memcache 对数据类型的支持简单,只支持简单的 key-value,,而 Redis 支持五种数据类型。
使用底层模型不同:它们之间底层实现方式以及与客户端之间通信的应用协议不一样。Redis 直接自己构建了 VM 机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
Value 的大小:Redis 可以达到 1GB,而 Memcache 只有 1MB。
淘汰策略
我:Redis 有六种淘汰策略,如下图:

持久化
RDB:快照形式是直接把内存中的数据保存到一个 dump 的文件中,定时保存,保存策略。
AOF:把所有的对 Redis 的服务器进行修改的命令都存到一个文件里,命令的集合。Redis 默认是快照 RDB 的持久化方式。
我:(说就一起说下吧)使用 AOF 做持久化,每一个写命令都通过 write 函数追加到 appendonly.aof 中,配置方式如下:
appendfsync yes
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
主从复制
从节点执行 slaveof[masterIP][masterPort],保存主节点信息。
从节点中的定时任务发现主节点信息,建立和主节点的 Socket 连接。
从节点发送 Ping 信号,主节点返回 Pong,两边能互相通信。
连接建立后,主节点将所有数据发送给从节点(数据同步)。
主节点把当前的数据同步给从节点后,便完成了复制的建立过程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性。
runId:每个 Redis 节点启动都会生成唯一的 uuid,每次 Redis 重启后,runId 都会发生变化。
offset:主节点和从节点都各自维护自己的主从复制偏移量 offset,当主节点有写入命令时,offset=offset+命令的字节长度。
从节点在收到主节点发送的命令后,也会增加自己的 offset,并把自己的 offset 发送给主节点。
这样,主节点同时保存自己的 offset 和从节点的 offset,通过对比 offset 来判断主从节点数据是否一致。
repl_backlog_size:保存在主节点上的一个固定长度的先进先出队列,默认大小是 1MB。
主节点发送数据给从节点过程中,主节点还会进行一些写操作,这时候的数据存储在复制缓冲区中。
从节点同步主节点数据完成后,主节点将缓冲区的数据继续发送给从节点,用于部分复制。
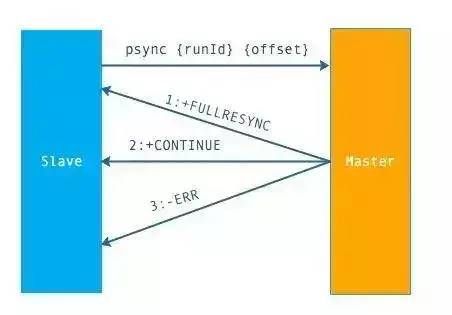
FULLRESYNC:第一次连接,进行全量复制
CONTINUE:进行部分复制
ERR:不支持 psync 命令,进行全量复制
我:可以!
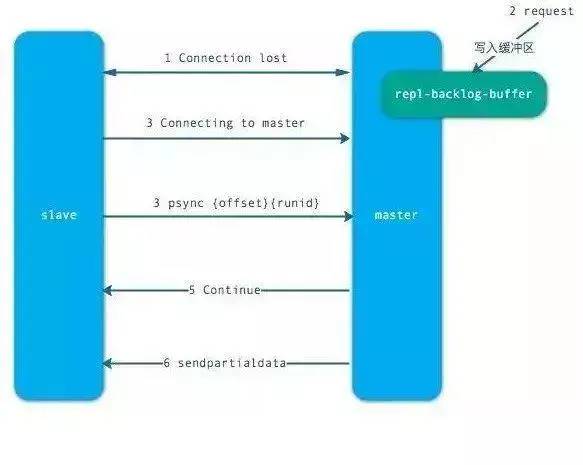
从节点发送 psync ? -1 命令(因为第一次发送,不知道主节点的 runId,所以为?,因为是第一次复制,所以 offset=-1)。
主节点发现从节点是第一次复制,返回 FULLRESYNC {runId} {offset},runId 是主节点的 runId,offset 是主节点目前的 offset。
从节点接收主节点信息后,保存到 info 中。
主节点在发送 FULLRESYNC 后,启动 bgsave 命令,生成 RDB 文件(数据持久化)。
主节点发送 RDB 文件给从节点。到从节点加载数据完成这段期间主节点的写命令放入缓冲区。
从节点清理自己的数据库数据。
从节点加载 RDB 文件,将数据保存到自己的数据库中。如果从节点开启了 AOF,从节点会异步重写 AOF 文件。
哨兵
一旦主节点宕机,从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。
主节点的写能力受到单机的限制。
主节点的存储能力受到单机的限制。
原生复制的弊端在早期的版本中也会比较突出,比如:Redis 复制中断后,从节点会发起 psync。
此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时,可能会造成毫秒或秒级的卡顿。
面试官:那么问题又来了。那你说下哨兵有哪些功能?
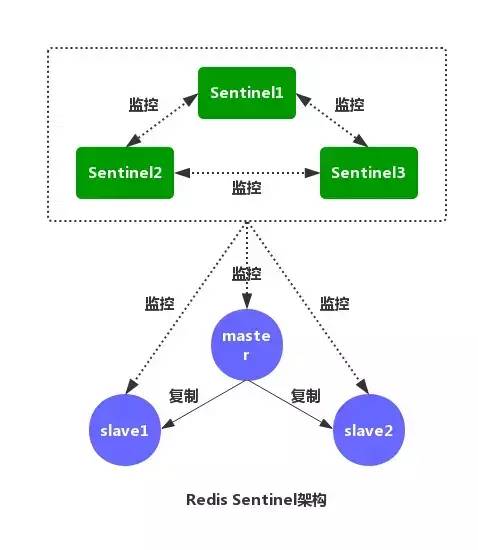
监控:不断检查主服务器和从服务器是否正常运行。
通知:当被监控的某个 Redis 服务器出现问题,Sentinel 通过 API 脚本向管理员或者其他应用程序发出通知。
自动故障转移:当主节点不能正常工作时,Sentinel 会开始一次自动的故障转移操作,它会将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并且将其他的从节点指向新的主节点,这样人工干预就可以免了。
配置提供者:在 Redis Sentinel 模式下,客户端应用在初始化时连接的是 Sentinel 节点集合,从中获取主节点的信息。
我:话不多说,直接上图:
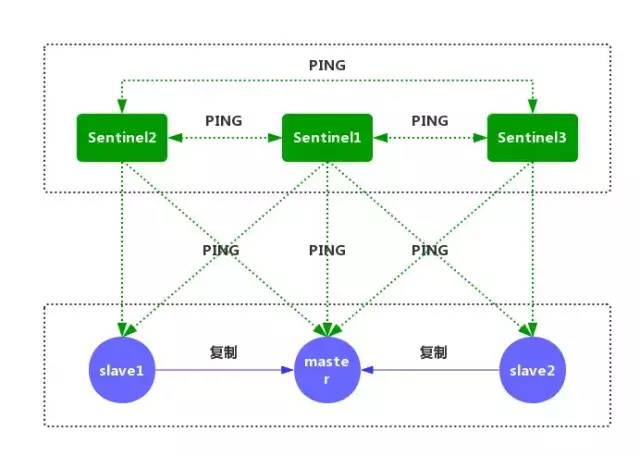
①每个 Sentinel 节点都需要定期执行以下任务:每个 Sentinel 以每秒一次的频率,向它所知的主服务器、从服务器以及其他的 Sentinel 实例发送一个 PING 命令。(如上图)
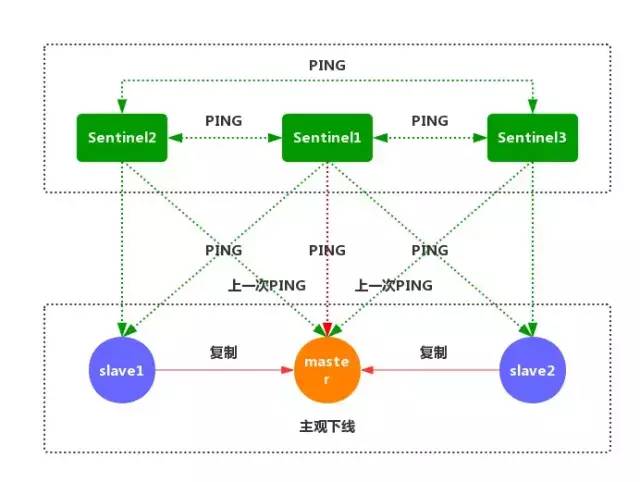
②如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 所指定的值,那么这个实例会被 Sentinel 标记为主观下线。(如上图)
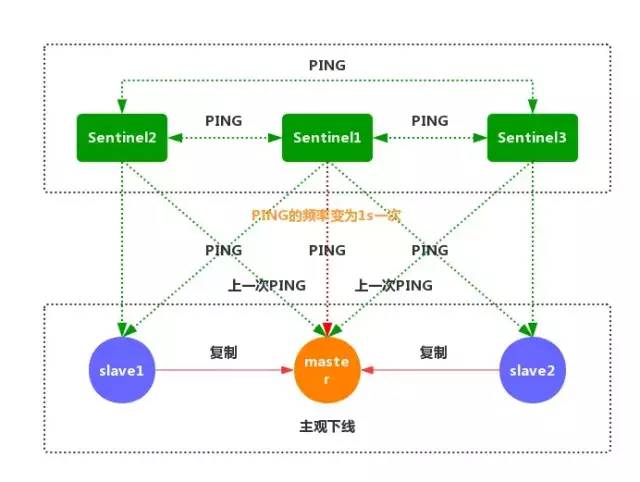
③如果一个主服务器被标记为主观下线,那么正在监视这个服务器的所有 Sentinel 节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态。
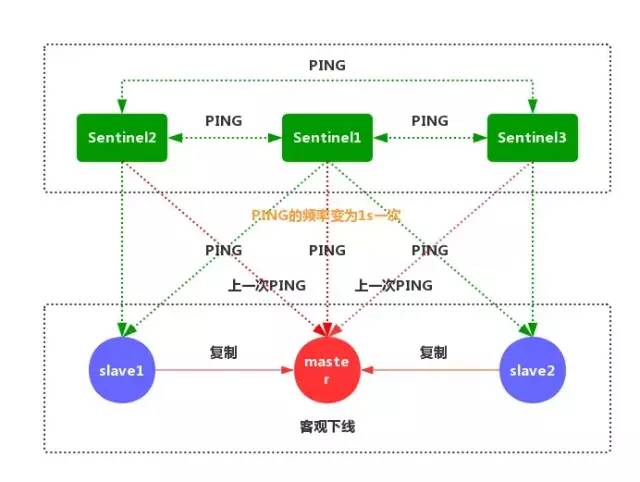
④如果一个主服务器被标记为主观下线,并且有足够数量的 Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。
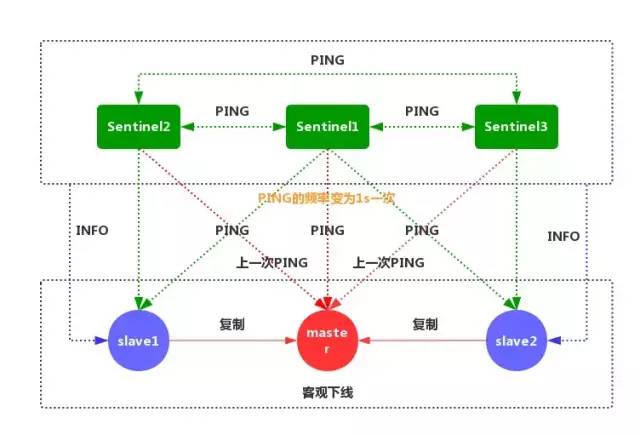
当一个主服务器被标记为客观下线时,Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率,会从 10 秒一次改为每秒一次。
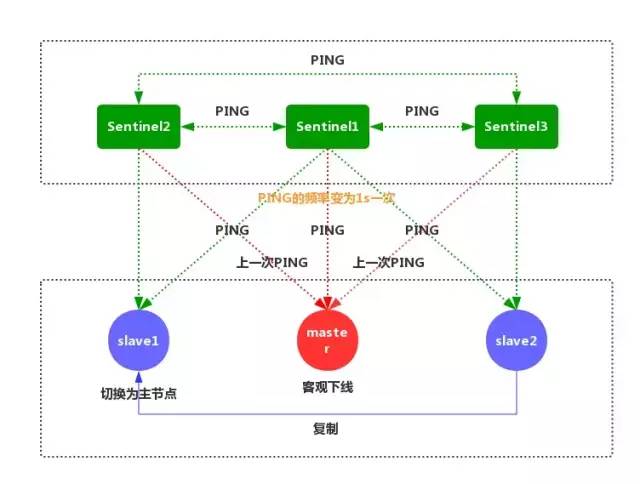
⑥Sentinel 和其他 Sentinel 协商客观下线的主节点的状态,如果处于 SDOWN 状态,则投票自动选出新的主节点,将剩余从节点指向新的主节点进行数据复制。

总结
- EOF -

为什么祖传代码会被称为“屎山”?

程序员才能理解的22张内涵图!!