
Google最新最权威的未来人工智能技术之一:人脸领域
长按扫描维码关注
计算机视觉研究院专栏
作者:Edison_G

接下来,先看一小段我做的比较简单的人脸检测识别Demo!开始进入今天我们正式的主题!
关注并星标
从此不迷路

♥

近年来由于深度学习爆炸式的发展,已经带动了整个行业的发展。身为人工智能的一份子,为该技术骄傲自豪。在丰富的应用场景,人脸识别市场潜力巨大。应用场景逐渐增多,布局人脸识别的生态从而也更丰富。从消费电子领域,到汽车电子、安防、互联网支付、金融等领 域逐步引入指纹识别,随着消费者用户习惯的养成,未来市场渗透快速攀升。
亚马逊、谷歌、IBM 和微软现在使用着什么?
亚马逊:深度神经网络 谷歌:卷积神经网络 IBM:深度学习算法 微软:人脸算法
定价
亚马逊、谷歌和微软都有类似的定价模式,这意味着随着使用量的增加,每次检测的价格会下降。然而,对于 IBM,在你的免费层使用量用完之后,你就要为每次调用 API 支付相同的价格。Microsoft 为你提供了最好的免费协议,允许你每月免费处理 30000 张图片。如果你需要检测更多,则需要使用他们的标准协议,是从第一张图片开始付费的。
价格比较
话虽如此,让我们计算三种不同配置类型的成本。
条件 A:小型初创公司/企业可每月处理 1000 张图片
条件 B:拥有大量图像的数字供应商,每月可处理 100,000 幅图像
条件 C:数据中心每月处理 10,000,000 张图像。
集成供应商的 API
获取 SDK 非常容易。使用 Composer 更容易。然而,我确实注意到一些可以改进的东西,以便开发者的生活变得更轻松。

我从亚马逊的识别 API 开始。浏览他们的文档后,我真的开始觉得有点失落。我不仅没找到一些基本的例子(或者无法找到它们?),但我也有一种感觉,我必须点击几次,才能找到我想要的东西。有一次,我甚至放弃了,只是通过直接检查他们的 SDK 源代码来获得信息。
另一方面,这可能只发生在我身上?让我知道亚马逊的识别对你来说是容易(还是困难)整合的吧!
注意:当 Google 和 IBM 返回边界框坐标时,Amazon 会返回坐标作为整体图像宽度/高度的比率。我不知道为什么,但这没什么大不了的。你可以编写一个辅助函数来从比率中获取坐标,就像我一样。
接下来是谷歌。与亚马逊相比,他们确实提供了一些例子,这对我帮助很大!或者也许我已经处于投资不同 SDK的心态了。
不管情况如何,集成 SDK 感觉要简单得多,而且我可以花费更少的点击次数来检索我想要的信息。
如前所述,IBM(还没有?)为 PHP 提供一个 SDK。然而,通过提供的 cURL 示例,我很快就建立了一个自定义客户端。如果已经能提供一个 cURL 例子,那么你使用它也错不了什么了。
看着微软的 PHP 代码示例(使用 Pear 的 HTTP _ request2 包),我最终为微软的 Face API 编写了自己的客户端。
整体市场成长迅速; 手机市场正在启动; 汽车、安防市场潜在增量。
即使考虑降价因素,市场空间仍很大。人脸识别,汽车及安防提供潜在的增量空间。汽车电子是下一个金矿,电动汽车 与无人驾驶技术带动下,汽车电子化率提速明显。2000年时平均每辆汽车使用芯 片数量仅有十几个,2016年平均每辆车需要600个芯片,未来汽车电子化率进一 步提升。博世、大陆、英伟达、克莱斯勒在2017年CES均展示了车内人脸识别应用,人脸识别未来有望大规模进入汽车电子领域。全球每年汽车销售8000万辆,考虑到汽车所需要的滤光片的数量、尺寸;组立件结构等因素,且在整车成本占比更小,价格敏感性低,ASP应比手机高,以50%渗透率算,未来空间容量约5亿。安防领域贡献人脸识别另一个增量市场。保守估计,安防用摄像头销量未来能够达到4000万台,以50%渗透率计算,未来市场空间约1亿。
通过上面的分析可以清晰的知道,未来人脸领域是一个发展空间巨大的技术,其中基本的技术路线如下图所示:
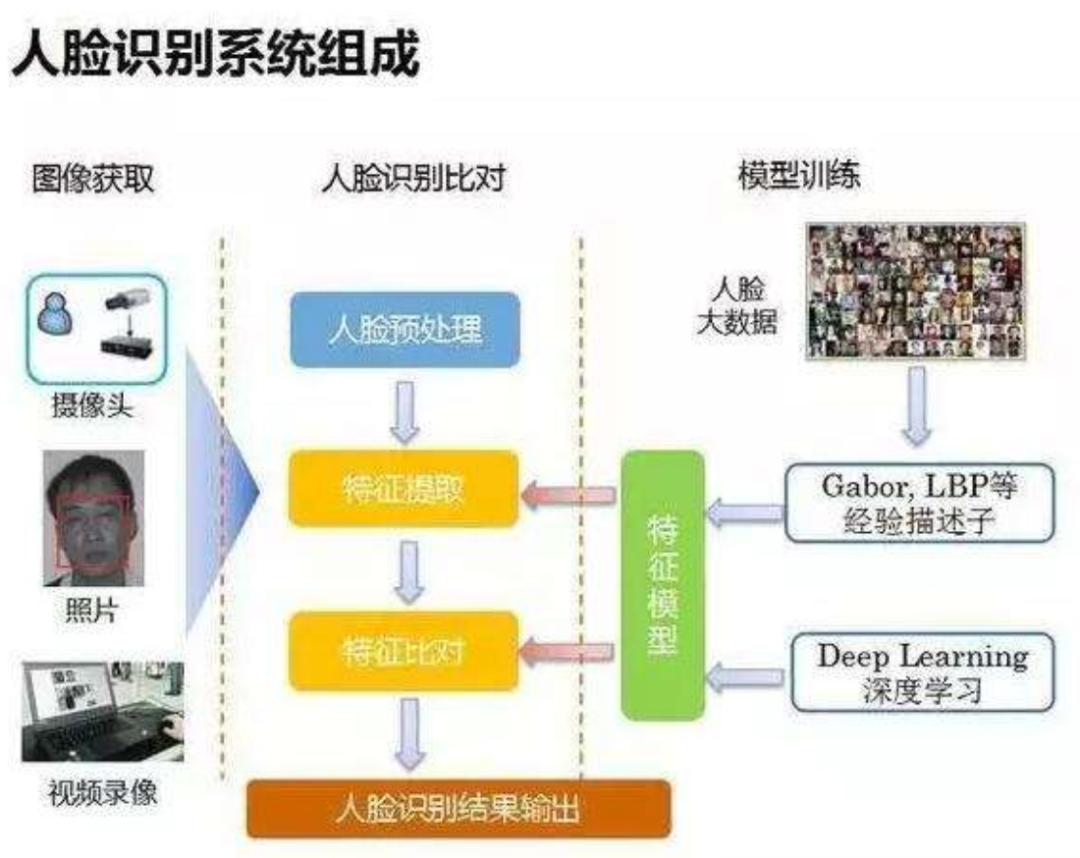
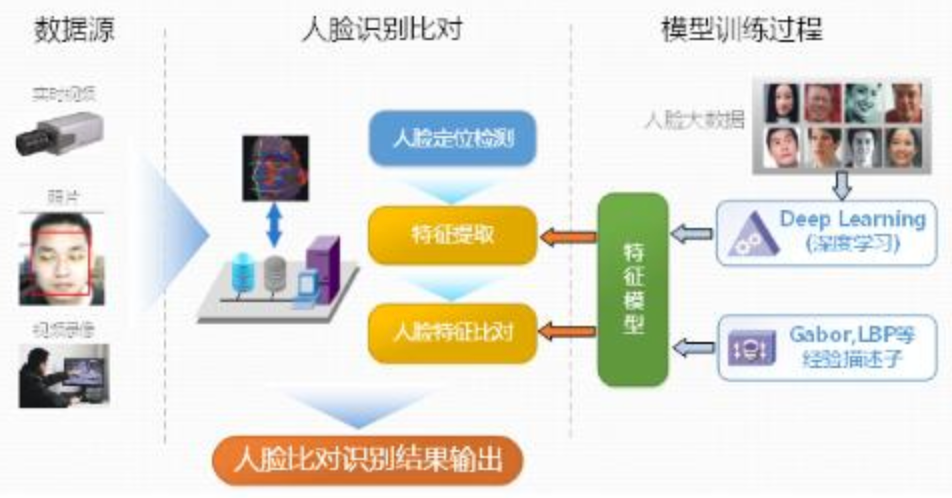
所以今天来和大家聊聊人脸检测与识别中的一些技术,简单为大家介绍和展示,希望可以给有兴趣的您带来一丝丝帮助,给未知的您带来浓厚的兴趣!今天主要内容有:人脸检测,人脸配准,人脸属性识别等技术。
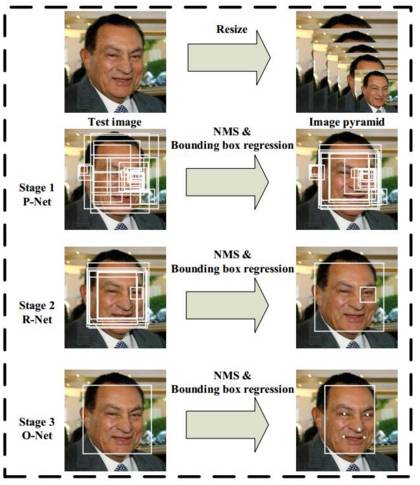
“人脸检测(Face Detection)”是检测出图像中人脸所在位置的一项技术。其中,人脸检测算法的输入是一张图片,输出是人脸边界框坐标。一般情况下,输出的人脸坐标框为一个正朝上的正方形,但也有一些人脸检测技术输出的是正朝上的矩形,或者是带旋转方向的矩形。
常见的人脸检测算法基本是一个“扫描”加“判别”的过程,即算法在图像范围内扫描,再逐个判定候选区域是否是人脸的过程。因此人脸检测算法的计算速度会跟图像尺寸、图像内容相关。
人脸检测的结果
![]() 人脸配准
人脸配准
“人脸配准(Face Alignment)”是定位出人脸上五官关键点坐标的一项技术。人脸配准算法的输入是“一张人脸图片”+“人脸边界框坐标”,输出五官关键点的坐标。五官关键点的数量是预先设定好的一个固定数值,可以根据不同的语义来定义(常见的有5点、68点、90点等等)。其实,我一般的做法是在精确检测人了后,进行裁剪将最后的结果作为人脸配准的输入。
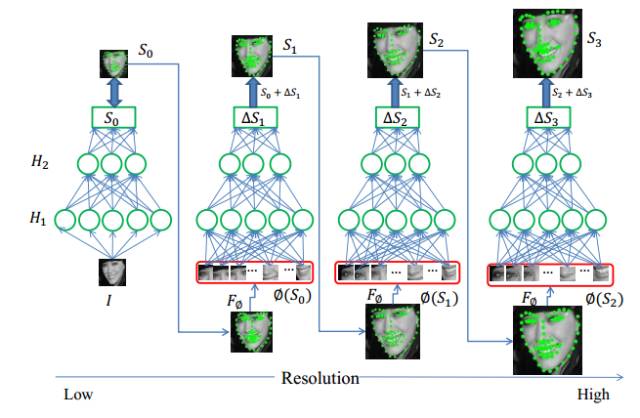

各种流行框架模型
关键点配准结果
![]() 人脸比对
人脸比对



/End.

我们开创“计算机视觉协会”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。
长按扫描维码关注我们