
任何网络都能山寨!新型黑盒对抗攻击可模拟未知网络进行攻击 | CVPR 2021

来源:AI科技评论 本文约3500字,建议阅读9分钟
本文解读对抗攻击与元学习联姻的两篇典型的论文。
SimulatorAttack论文链接:
https://arxiv.org/abs/2009.00960
SimulatorAttack代码链接:
https://github.com/machanic/SimulatorAttack
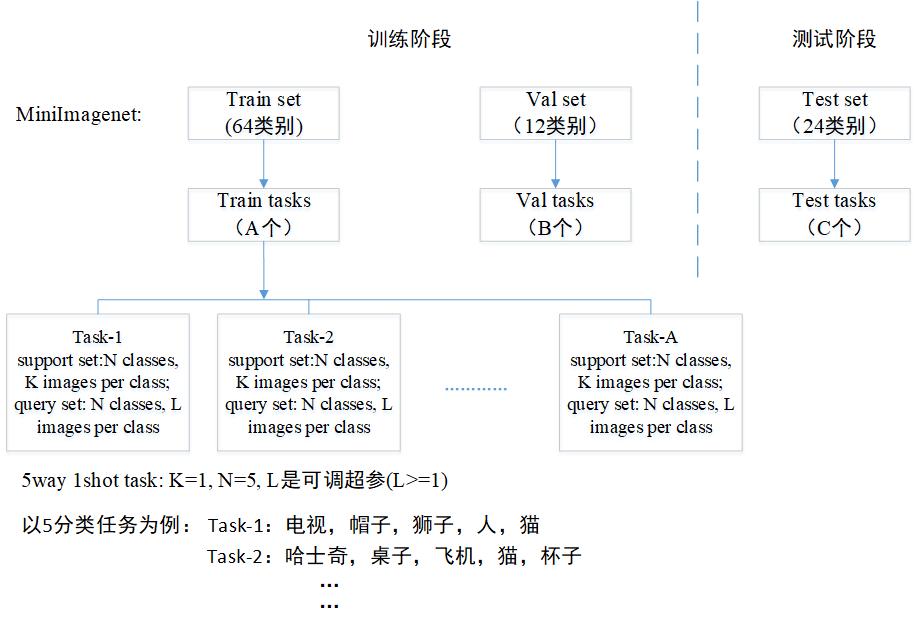
图1 一个典型的元学习将数据切分成task训练,而每个task包含的5个分类不同,1-shot是指每个分类只有一个样本。
 。而外部更新利用作为网络参数,输入query set的数据,计算一个对
。而外部更新利用作为网络参数,输入query set的数据,计算一个对 ,而外部更新利用作为网络参数去计算loss,这个loss最后用来计算元梯度来外部更新。
,而外部更新利用作为网络参数去计算loss,这个loss最后用来计算元梯度来外部更新。3.1 模拟器的训练
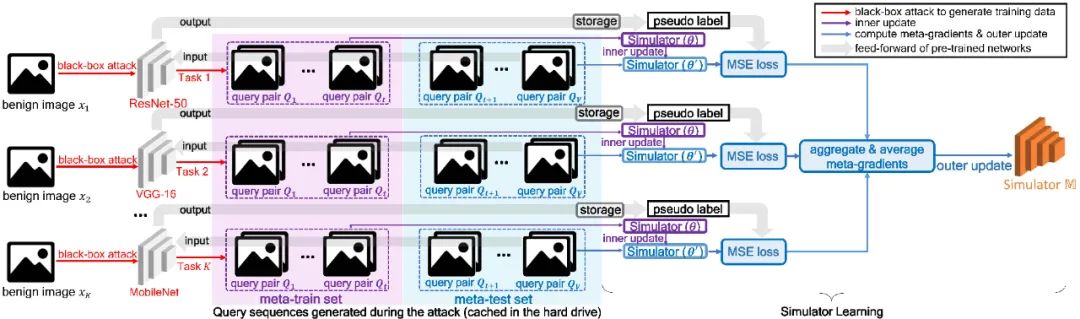 。然后,损失函数值
。然后,损失函数值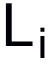 通过输入第i个task的meta-test set到网络而得到。之后,元梯度(meta-gradient)
通过输入第i个task的meta-test set到网络而得到。之后,元梯度(meta-gradient) 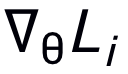 对
对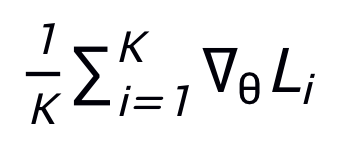 来更新模拟器(外部更新),由此模拟器可以学到泛化的模拟任意网络的能力。
来更新模拟器(外部更新),由此模拟器可以学到泛化的模拟任意网络的能力。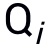 的两个query
的两个query 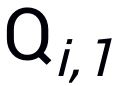 和
和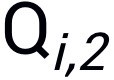 (由于Bandits攻击使用有限差分法去估计梯度,因此每次迭代生成一个query pair)。模拟器和随机选择的分类网络的logits输出分别记为
(由于Bandits攻击使用有限差分法去估计梯度,因此每次迭代生成一个query pair)。模拟器和随机选择的分类网络的logits输出分别记为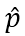 和
和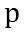 。如下MSE损失函数将使得模拟器的输出和伪标签趋近于一致。
。如下MSE损失函数将使得模拟器的输出和伪标签趋近于一致。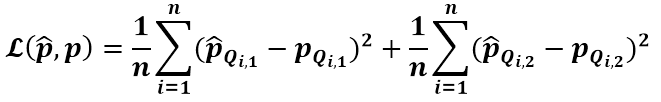
3.2 模拟器攻击
 收集这些输入和输出。在warm-up之后的迭代中,每隔m次迭代才使用一次目标模型,其余迭代一律输入使用模拟器来输出。因此目标模型和模拟器的使用是轮流交替进行的,这种方法一方面保证了大部分查询压力被转移到模拟器中,另一方面保证了模拟器每隔m次迭代就得到机会fine-tune一次,这保证了后期的迭代中模拟器能“跟得上不断演化的query的节奏,及时与目标模型保持一致”。
收集这些输入和输出。在warm-up之后的迭代中,每隔m次迭代才使用一次目标模型,其余迭代一律输入使用模拟器来输出。因此目标模型和模拟器的使用是轮流交替进行的,这种方法一方面保证了大部分查询压力被转移到模拟器中,另一方面保证了模拟器每隔m次迭代就得到机会fine-tune一次,这保证了后期的迭代中模拟器能“跟得上不断演化的query的节奏,及时与目标模型保持一致”。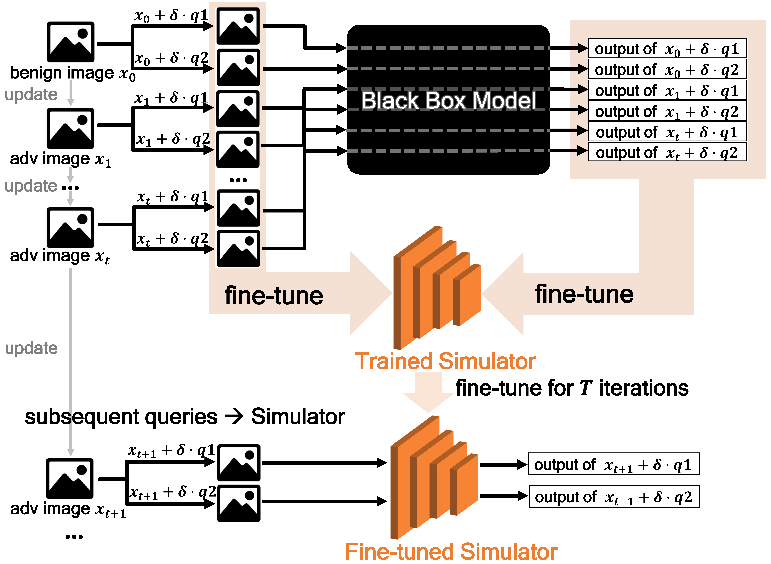
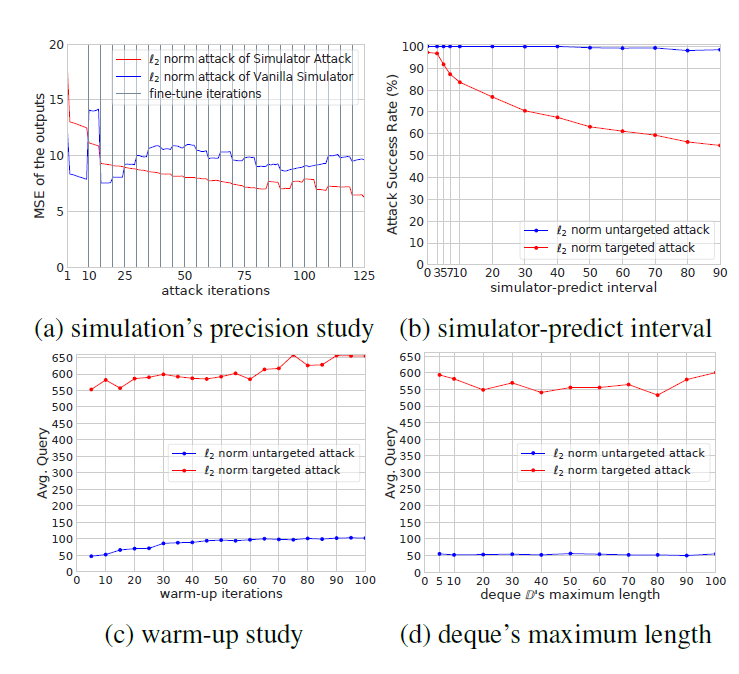
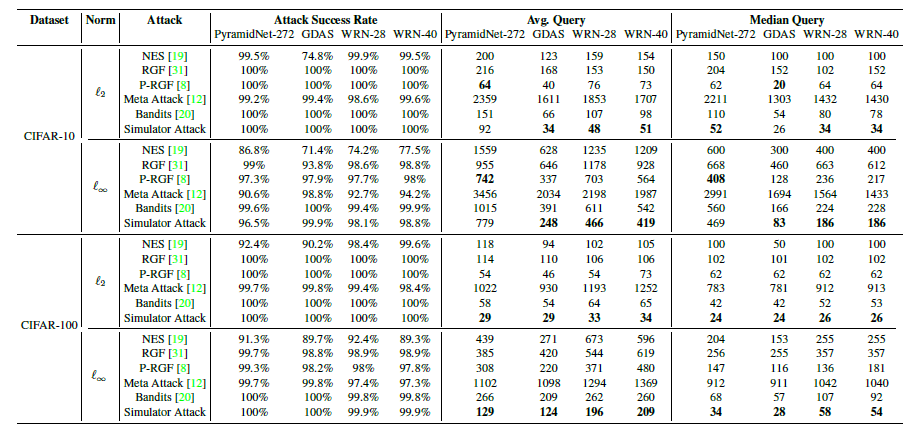
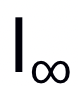 范数下的untargeted attack攻击TinyImageNet的实验结果
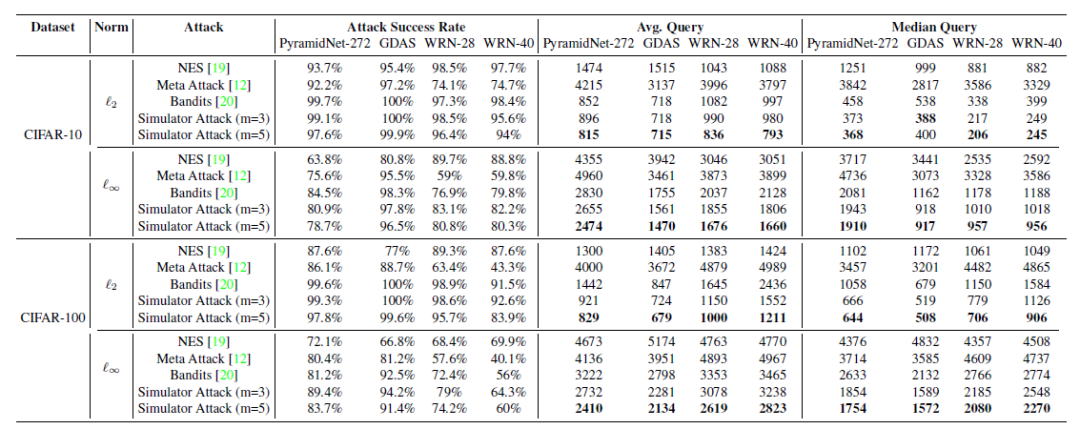
范数下的untargeted attack攻击TinyImageNet的实验结果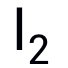 范数下的targeted attack攻击TinyImageNet的实验结果
范数下的targeted attack攻击TinyImageNet的实验结果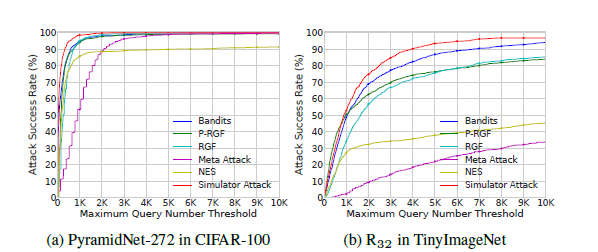
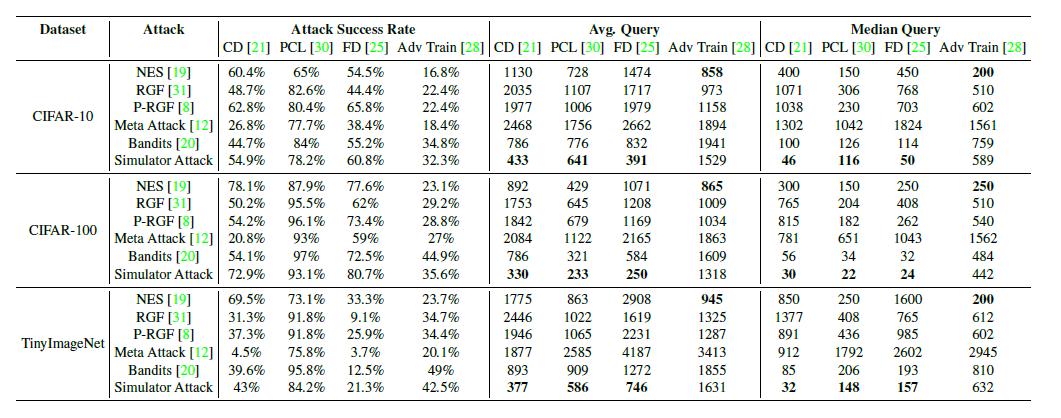 范数攻击防御模型的结果,所有防御模型皆选择ResNet-50 backbone
范数攻击防御模型的结果,所有防御模型皆选择ResNet-50 backbone评论