
异步结果通知实现——基于Redis实现,我这操作很可以
前段时间,我在内存中实现了一个简单异步通知框架。但由于没有持久化功能,应用重启就会导致数据丢失,且不支持分布式和集群。今天这篇笔记,引入了 Redis 来解决这些问题,以下是几点理由:
数据结构丰富,支持 List、Sorted Set 等
具有持久化功能,消息的可靠性能得到保证
高可用性,支持单机、主从、集群部署
项目中已使用,接入成本更低
基于 Redis 实现延时队列也有几种方法,展开详细讲讲。
基于键事件通知实现
Redis 2.8.0 版本以后就具有了 键事件通知(注,还有个键空间通知,注意区别),基于 Pub/Sub 发布订阅实现,详见 官网。而我们正好可以利用这个特性,实现异步通知的延迟功能,数据流转如下:

大概逻辑:当首次通知、或通知失败时,设置(重新设置)在 Redis 对应的 Key 的过期时间,Redis 会监听过期事件,发生事件时通知订阅者,订阅者接收到事件,做逻辑处理。下面看具体的实现。
首先,修改 Redis 端配置打开功能。由于该功能会消耗一些 CPU 性能,所以在配置文件中是 默认关闭 的。Ex表示打开 键过期事件通知,每当有过期键被删除时发送,订阅者能收到 接收到被执行事件的键的名字
notify-keyspace-events Ex其次,想要在 SpringBoot 中,订阅到 Redis 的事件,也需要两个步骤:
1、继承
org.springframework.data.redis.listener.adapter.MessageListenerAdapter 类,创建自己的监听器
@Componentpublic class OrderExpireEventListener extends MessageListenerAdapter {@Overridepublic void onMessage(Message message, byte[] pattern) {byte[] body = message.getBody();String msg = redisWrapper.getRedisTemplate().getStringSerializer().deserialize(body);// do something...// 假如通知失败,需要重新计算下次通知时间,设置 Redis// 至于数据类型,String 即可}}
2、将创建的监听器,注册(委托设计模式)给
RedisMessageListenerContainer
@Beanpublic RedisMessageListenerContainer container(RedisConnectionFactory factory,OrderExpireEventListener adapter) {RedisMessageListenerContainer container = new RedisMessageListenerContainer();container.setConnectionFactory(factory);container.addMessageListener(adapter, new PatternTopic("__keyevent@0__:expired"));return container;}
这里有个点需要注意下,那就是 Redis 的键设计。
代码中的 __keyevent@0__:expired 频道匹配意味着,编号为 0 的库中所有键过期时间都会被订阅到。而这个 Redis 可能不单单只有这个业务在使用,有可能存在其他的业务也在使用。总不可能来个任意的键都会需要去做过期处理。最好是有个通用的设计规则,对 Key 的含义分割。比如:产品固定前缀:业务:业务属性:业务唯一标识
app1:trans:notice:1615283234代表:系统名为 app1 的 在交易模块 的 订单号为 1615283234 的通知业务的消息。当监听器解析 Key 失败时则说明是其他的键过期,不做处理。一旦解析成功,则对消息进行路由分发。
键搞定了,值就看业务情况而定。如果是通知的话,必须带上当前是第几次通知,根据这个再加上策略才能算出下次通知时间(该键的过期时间)。
一般简单的方法都存在多少的缺陷,这种方式也不例外。引用 Redis 官网的一段话:
Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost
意思是说:Redis 目前发布订阅基于 发送即忘 策略,且没有 ACK 机制,意味着客户端重启掉线期间,消息会丢失。加上 Pub/Sub 消息 没有持久化机制,假如当订阅客户端由于网络原因没收到,想再次重试,这是没法实现的。
假如此时我还想跟内存队列那样子能够 对消息的延迟时间进行自动排序,该如何实现呢?除此之外,Pub/Sub 是广播机制,假如存在多个订阅者,那么就会 同时收到键过期的消息,此时又该如何处理 消息竞争 问题?
基于 Sorted Set 实现
这时候我们要引入 Redis 的 Sorted Set 数据结构。关于这个数据结构简单来说是 支持排序的 Set,靠的是与之关联的浮点值,称为 score 来实现的。值得注意的是,这个排序并不是放进去的时候排,是拿出来的时候(联想到 性能 问题,后面有讲)。这里引用一段官网的话:
Moreover, elements in a sorted sets are taken in order (so they are not ordered on request, order is a peculiarity of the data structure used to represent sorted sets).
所以我们只需要将消息延迟执行的时间戳作为分数值,就能解决上文所说的排序问题,当然由于该结构是 Redis 的基本功能,自然也支持持久化,也就是解决了消息丢失问题。
大概设计如下:
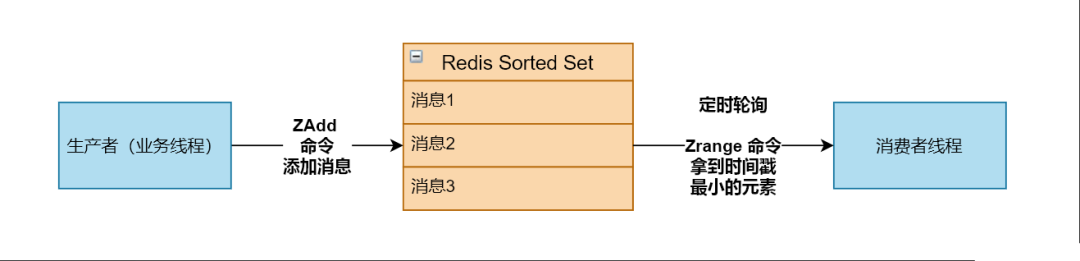
首先看看,消费者线程该如何实现(SpringBoot 环境下)
@Slf4j@Componentpublic class ConsumerTask {@AutowiredRedisTemplate<String, Object> redisTemplate;// Sorted Set 队列键private static String KEY = "TEST:ZSET";@Scheduled(cron = "0/1 * * * * ?")public void run() {try {this.doRun();} catch (Exception e) {log.error("消费异常", e);}}private void doRun() {// zrange 分数从小到大 zrevrange 分数从大到小// 拿出最新的待处理消息Set<ZSetOperations.TypedTuple<Object>> tuples =redisTemplate.opsForZSet().rangeWithScores(KEY, 0, 0);if (CollectionUtils.isEmpty(tuples)) {log.info("队列无数据");return ;}ZSetOperations.TypedTuple<Object> typedTuple = tuples.iterator().next();if (typedTuple == null) {log.info("队列无数据");return ;}Double score = typedTuple.getScore();Object value = typedTuple.getValue();if (System.currentTimeMillis() < score) {log.info("未到执行时间...");return ;}Long zrem = redisTemplate.opsForZSet().remove(KEY, value);if (Long.compare(1L, zrem) == 0) {log.info("删除数据成功,开始处理,数据:{}", value.toString());// do someting...// 假如通知失败,需要重新计算通知时间(score 值)并在 Redis 设置(ZADD)该消息}else {log.info("被其他的消费端抢占,不处理...");}}}
跟之前的 推模式 相比,这次采用的是 拉模式,尽管在多个消费端可能同时拿到同一个消息,不过这里通过 Long zrem = redisTemplate.opsForZSet().remove(KEY, value) 这方法,利用了 rem 命令的原子性 解决了竞争问题,也就是说只会有一个客户端删除成功。
仔细观察的话,可以看到我们拿到的时间戳是 Long 类型的,但是 Spring 提供的 Sorted Set 操作 api 参数是 Double 类型
org.springframework.data.redis.core.ZSetOperations#add(K, V, double)org.springframework.data.redis.core.ZSetOperations#rangeByScore(K, double, double)
那会不会有精确丢失问题?所以输出看下最大最小值
System.out.println(Long.MAX_VALUE); // 2 的 64 次方-1,19 个数位System.out.println(Long.MIN_VALUE); // 负的 2 的 64 次方System.out.println(Double.MAX_VALUE); // 2 的 1024 次方 -1,308 个数位System.out.println(Double.MIN_VALUE); // 2 的 -1074次方
可以看到 Double 最大值远远大于 Long 类型,加上时间戳不会有负数,所以可以放心转换。
在这里不演示生产者代码,过于简单,就是调用 zadd 命令而已。这里也需要注意,如果是异步通知场景 zadd 的值必须带上这是第几次通知,就如前面的方案一样。
到此为止,第一种方案存在的问题在第二种方案全部解决了。下面看一种网上的比较多的实现方式。
基于 Sorted Set、List 实现
跟上一种相比多了一个 List 数据结构。先来看下加入 List 之后的整个设计图
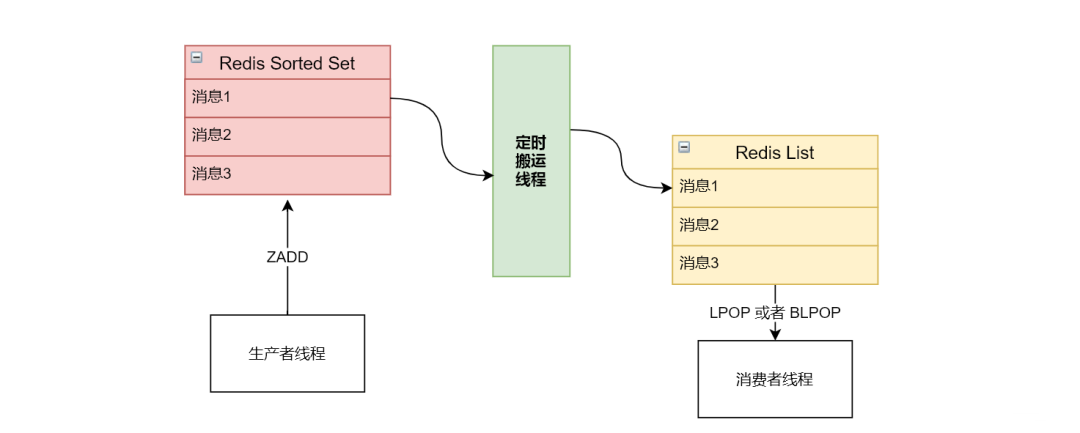
不得不说刚开始看见这种方案时,是存在疑惑的。因为上面的 Sorted Set 已经实现了功能,为什么要引入 List 数据结构增加系统的复杂度?唯一能看到的好处就是 List 数据结构提供了 阻塞 操作?经过与同事讨论后,得出下面几点结论:
客户端拉取消息 控制并发的步骤减少。当使用 List 时,只需要调用一个命令就可以解决消息竞争问题,而使用 Sorted Set 则需要使用 zrange 和 zrem 两条命令来实现,相比之下,多交互一次网络,且实现更复杂。
客户端拉取消息的方式增多,同时,队列提供 阻塞式 访问,同样也 减少 了客户端由于无限循环造成的 CPU 浪费。
队列 pop 操作比 zrange 操作对 Redis 来说性能开销更小,在这种频繁拉取的情况下更加合适。
这里需要注意的一点是,搬运操作有多个命令一起完成,如下伪代码
// 1、从 Sorted Set 中拿出 score 值在 前五秒 到 目前(包含现在)的所有元素Date now = new Date();Date fiveSecondBefore = DateUtils.addSeconds(now, -5);Set<Object> objects = redisTemplate.opsForZSet().rangeByScore("Sorted Set:Key", fiveSecondBefore.getTime(), now.getTime());if (CollectionUtils.isEmpty(objects)) {return ;}// 2、将这些元素从 Sorted Set 中删除Long removeResult = redisTemplate.opsForZSet().remove("Sorted Set:Key", objects);if (Long.compare(removeResult, objects.size()) != 0) {return ;}// 3、将这些元素放进 ListLong result = redisTemplate.opsForList().leftPushAll("List:Key", objects);
rangeByScore、remove、leftPushAll 这几个操作不具有原子性,可能在中途发生异常、宕机等情况,导致在搬运过程中丢失或重复搬运。
好在 Redis 提供了执行 lua 脚本功能,会保证同一脚本以原子性(atomic) 的方式执行,所以我们只需要原子性操作的多个步骤整合在自定义 lua 脚本中即可,如下:
local list_key = KEYS[1];local sorted_set_key = KEYS[2];local now = ARGV[1];local sorted_set_size = redis.call('ZCARD', sorted_set_key)if (tonumber(sorted_set_size) <= 0) thenreturnendlocal members = redis.call('ZRANGEBYSCORE', sorted_set_key, 0, tonumber(now));if (next(members) == nil) thenreturnendfor key,value in ipairs(members)dolocal zscore = redis.call('ZSCORE',sorted_set_key,value);if (tonumber(now) < tonumber(zscore)) thenreturn zscore;endredis.call('ZREM', sorted_set_key, value);redis.call('RPUSH', list_key, value);endlocal topmember = redis.call('ZRANGE', sorted_set_key, 0, 0);local nextvalue = next(topmember);if (nextvalue == nil) thenreturnendfor k,v in ipairs(topmember)doreturn redis.call('ZSCORE', sorted_set_key, v);end
下面是 SpringBoot 定时调用该 lua 脚本进行搬运的示例代码:
@Scheduled(cron = "0/1 * * * * ?")public void run4() {ClassPathResource resource = new ClassPathResource("sorted_set_to_list.lua");String luaScript = FileUtils.readFileToString(resource.getFile());DefaultRedisScript<String> redisScript = new DefaultRedisScript<>(luaScript, String.class);//List<String> keys = Lists.newArrayList("TEST:LIST", "TEST:ZSET");String now = String.valueOf(System.currentTimeMillis());// 注意这里的序列化器,需要换成 StringSerializer// 替换的默认的 Jackson2JsonRedisSerializerString executeResult = redisTemplate.execute(redisScript, redisTemplate.getStringSerializer(),redisTemplate.getStringSerializer(), keys, now);log.info("lua 脚本执行结果:{}", executeResult);}
最后再来看看消费者该如何实现
@Component@Slf4jpublic class ListConsumer implements ApplicationListener<ContextRefreshedEvent> {@Overridepublic void onApplicationEvent(ContextRefreshedEvent event) {Executors.newSingleThreadExecutor().submit(new PopEventRunner());}private static class PopEventRunner implements Runnable {@Overridepublic void run() {RedisTemplate<String, Object> redisTemplate = (RedisTemplate<String, Object>) SpringUtil.getBean3("redisTemplate");while (true) {try {Object leftPop = redisTemplate.opsForList().leftPop("TEST:LIST", Integer.MAX_VALUE, TimeUnit.SECONDS);if (leftPop == null) {continue ;}// do something...// 当通知失败时,重新计算通知时间并设置(ZADD)Redis} catch (Exception e) {log.error("监听异常", e);sleep(5); // 发生异常睡五秒}}}}}
监听容器的刷新事件,创建监听单线程,无限循环阻塞监听队列。相对于前一种实现方案,该方案确实更加的贴合。但仍有优化的余地,比如:
搬运线程的时机,目前频率为 1 秒,所以极端情况会有 1 秒时间的延迟。且在 Sorted Set 为空情况下,对 CPU 是一种浪费。
小结
相对前一篇内存实现,Redis 这种方式更加的可靠,且在允许一点时间的误差和牺牲一点消息可靠性下,不失为一种 性价比高 的选择。假如当前景就是不允许有这些损失,那还有什么解决方案吗?到时候我们再来讲终极杀招,使用 RabbitMQ 来实现。

腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)
面试:史上最全多线程面试题 !
最新阿里内推Java后端面试题
JVM难学?那是因为你没认真看完这篇文章

关注作者微信公众号 —《JAVA烂猪皮》
了解更多java后端架构知识以及最新面试宝典

看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力
作者:午饭吃什么
链接:https://juejin.cn/post/6938779316847116325
来源:掘金