
Milvus 解析 | 前所未有的 Milvus 源码架构解析

✏️ 编者按:
Deep Dive 是由 Milvus 社区发起的代码解析系列直播,针对开源数据库 Milvus 整体架构开放式解读,与社区交流与分享 Milvus 最核心的设计理念。通过本期分享,你可以了解到云原生数据库背后的设计理念,理解 Milvus 相关组件与依赖,了解 Milvus 多种应用场景。
栾小凡,Zilliz 合伙人、工程总监,LF AI & Data 基金会技术咨询委员成员。他先后任职于 Oracle 美国总部、软件定义存储创业公司 Hedvig 、阿里云数据库团队,曾负责阿里云开源 HBase 和自研 NoSQL 数据库 Lindorm 的研发工作。栾小凡拥有康奈尔大学计算机工程硕士学位。
我们为什么需要 Milvus ?为什么它被称为下一代人工智能基础设施? Milvus 2.0 的设计理念 Milvus 2.0 的概览与模块划分 Milvus 代码阅读注意事项
我们为什么需要 Milvus?
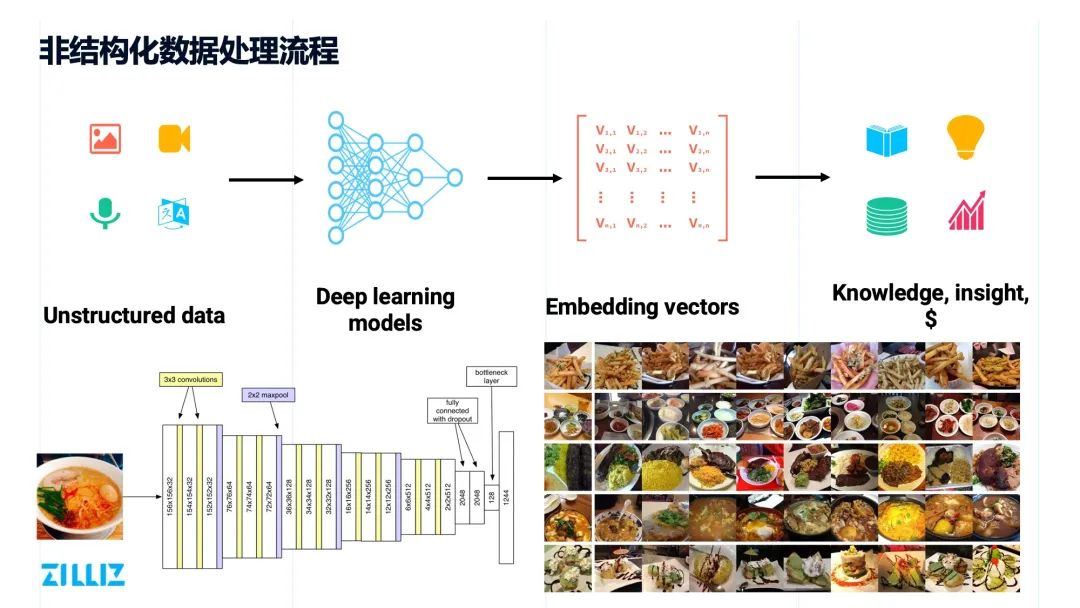
非结构化数据处理流程
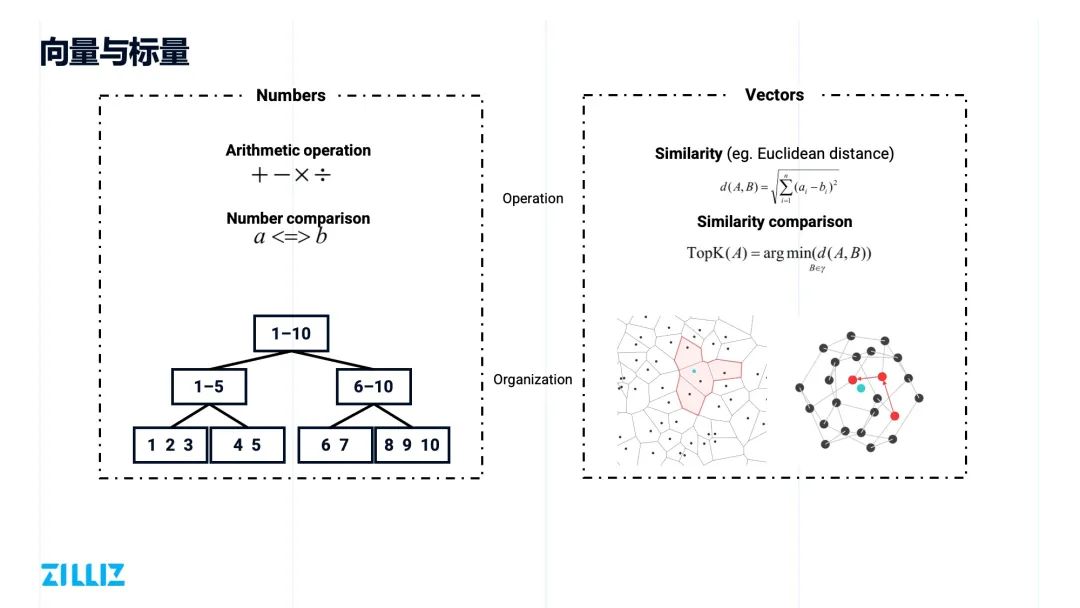
向量与标量
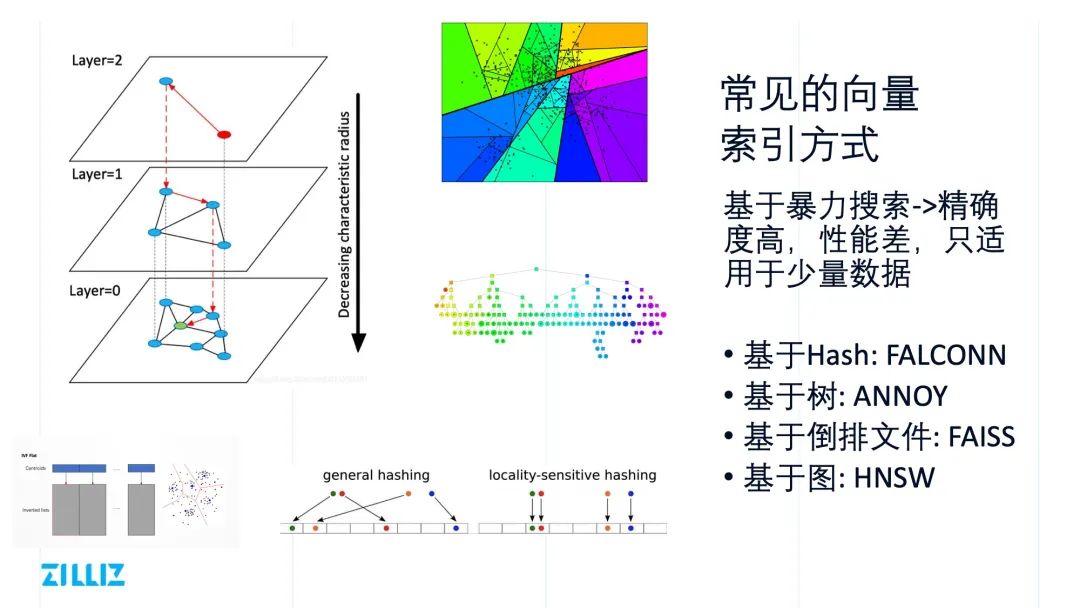
常见的向量索引方式
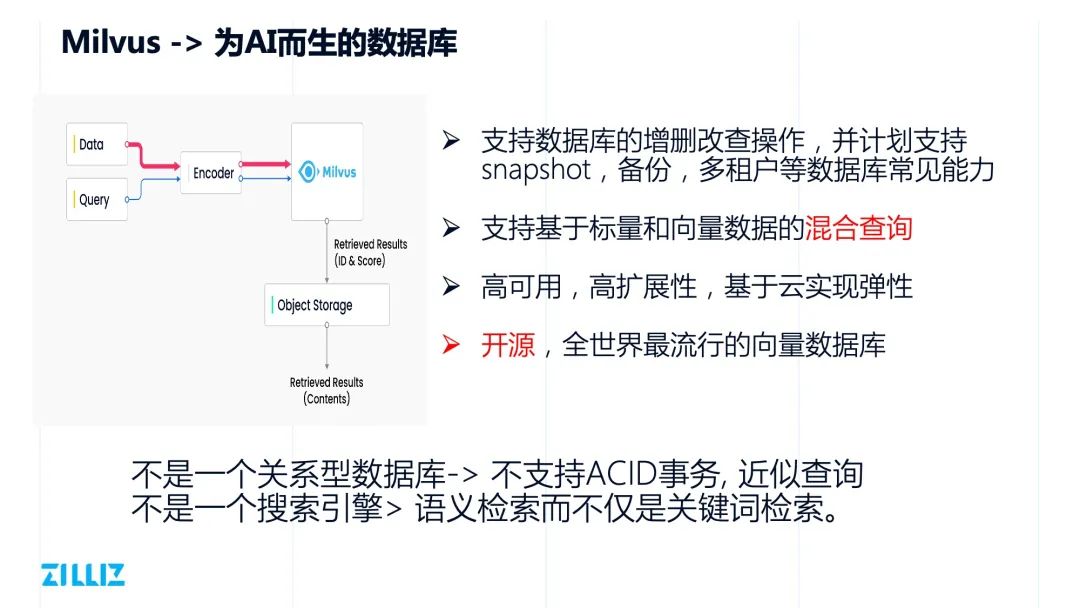
Milvus:为 AI 而生的数据库
2.0 Tradeoffs

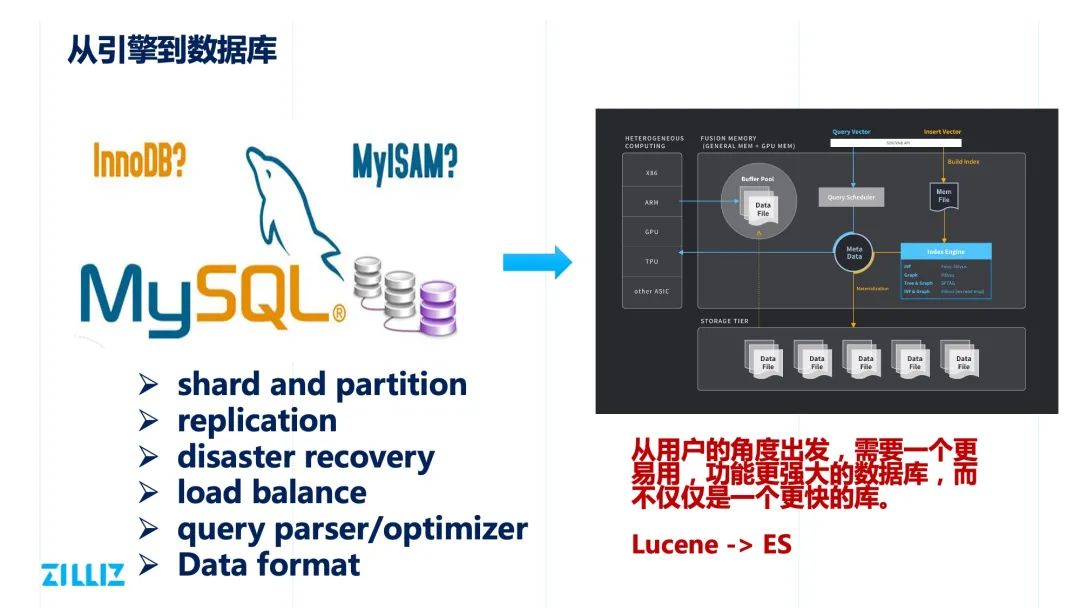
从引擎到数据库
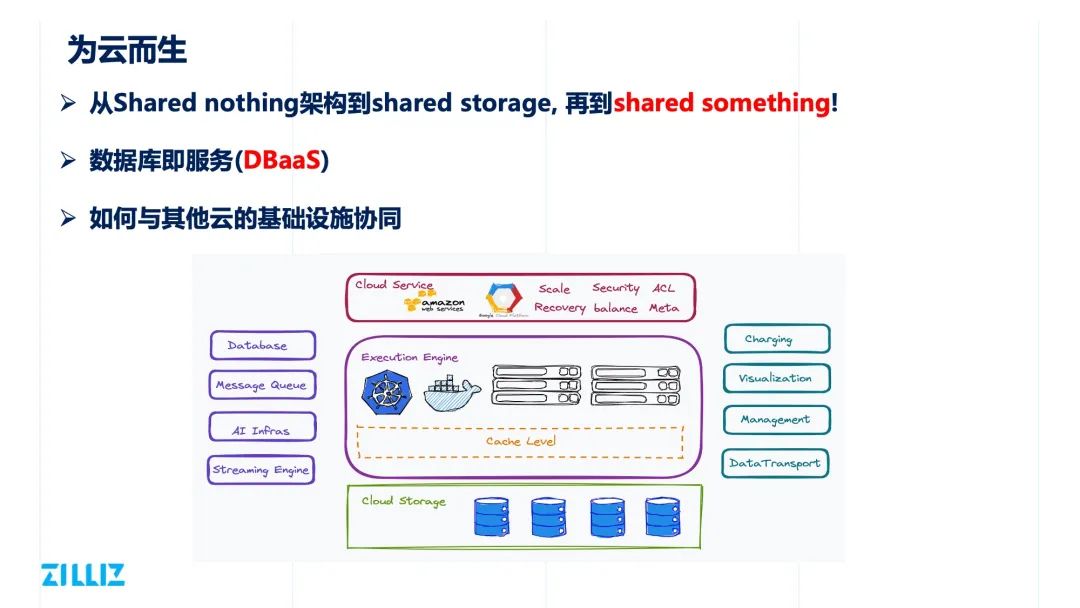
为云而生
Milvus 2.0 的设计理念
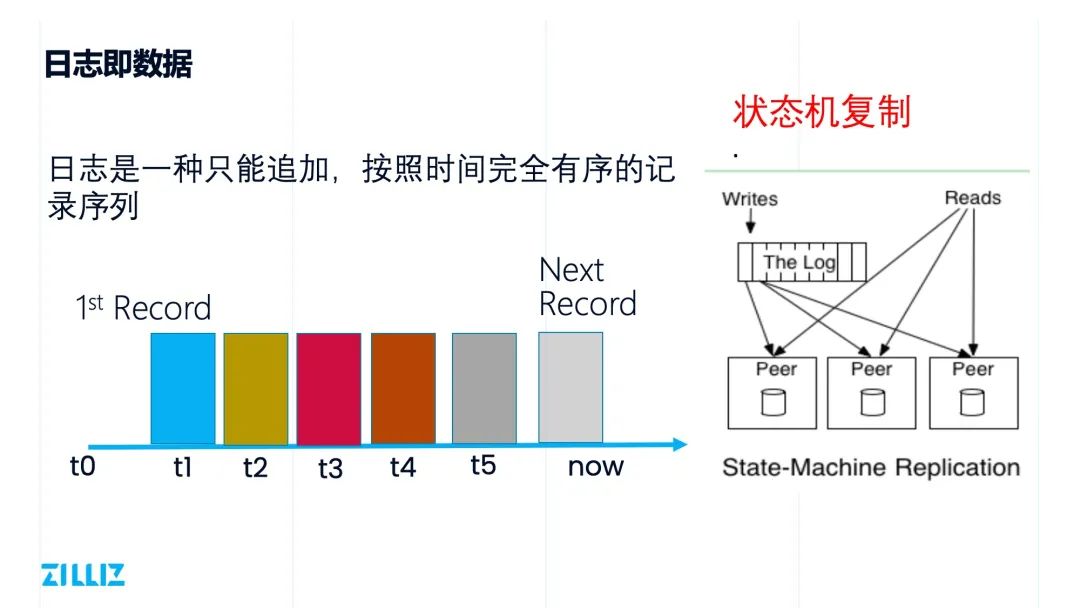
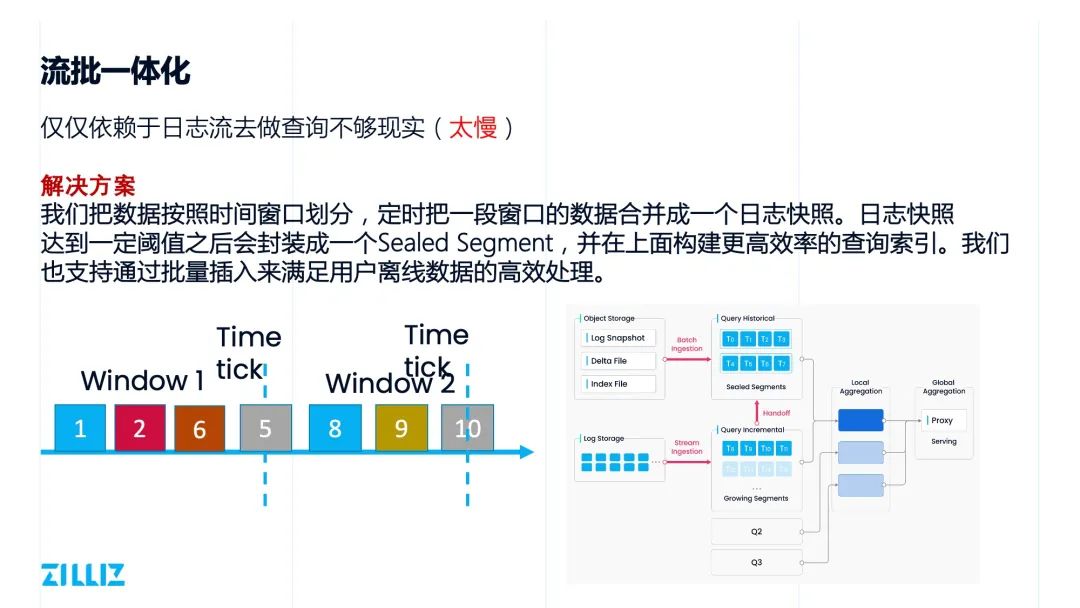
日志即数据
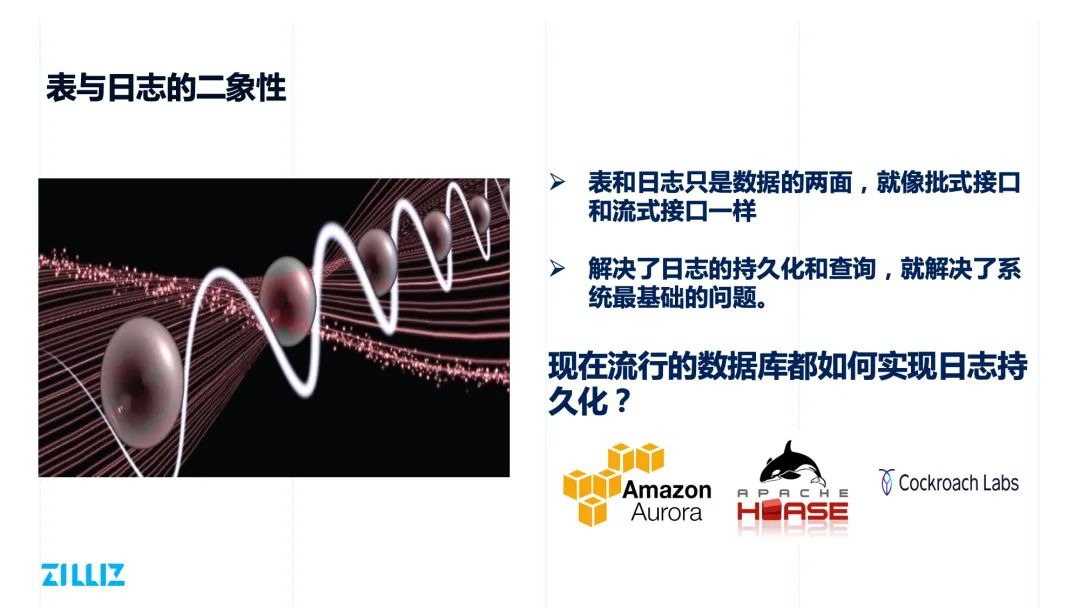
表与日志的二象性
日志持久化
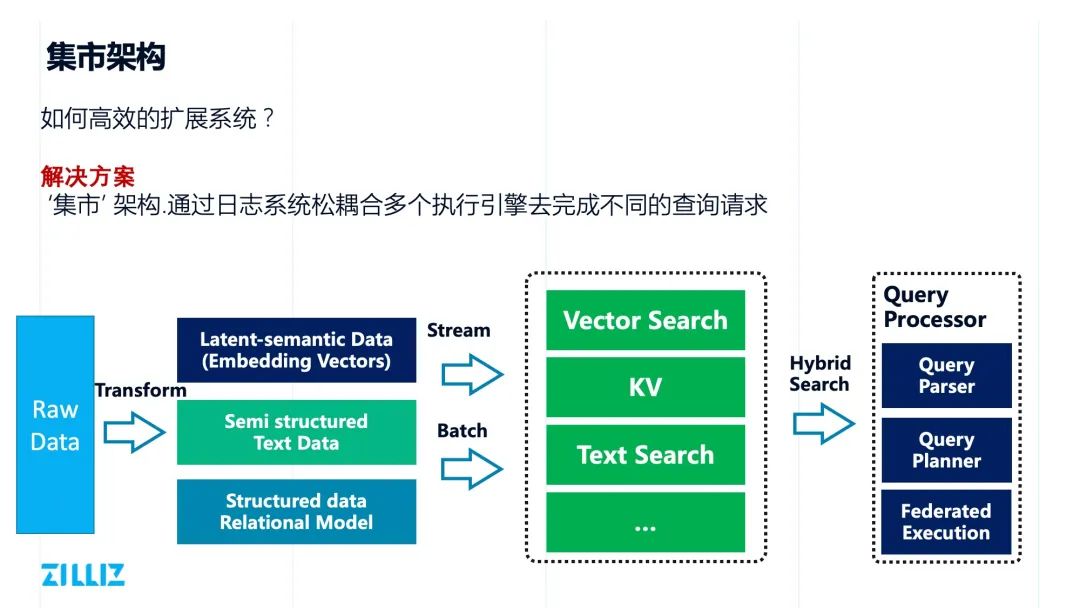
集市架构

Milvus 2.0 概览与模块划分
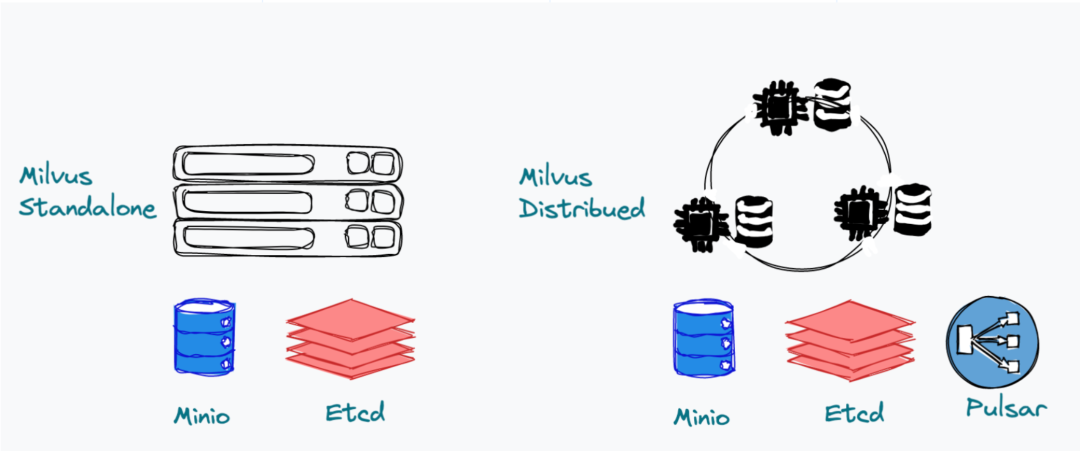
Milvus 单机与分布式
Milvus 的角色
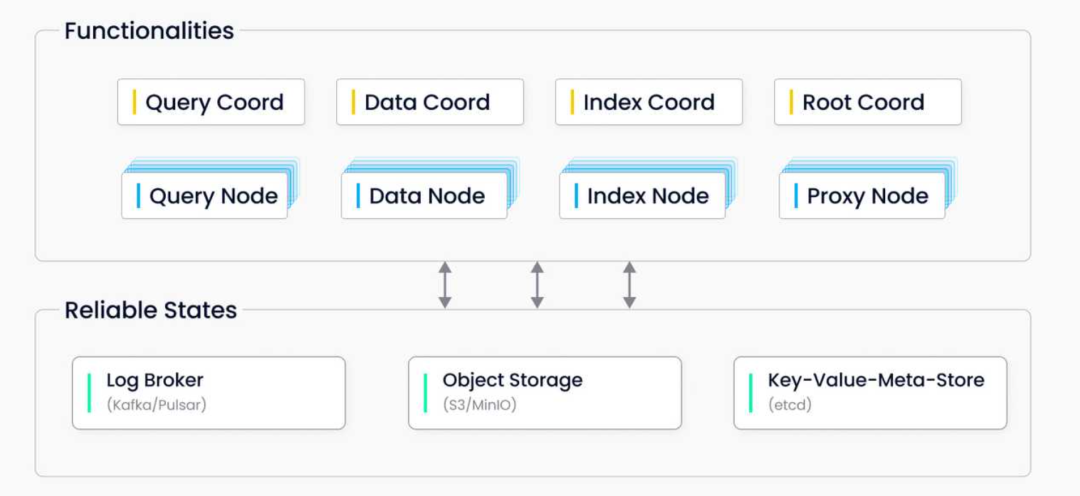
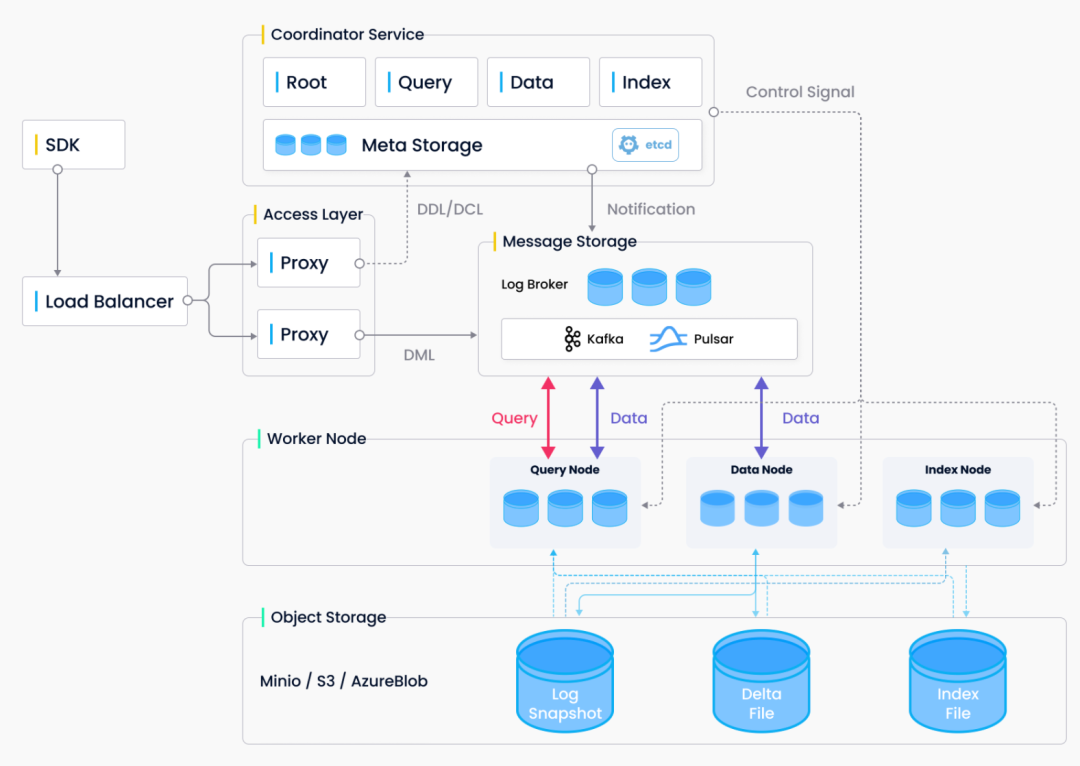
Milvus 架构概览
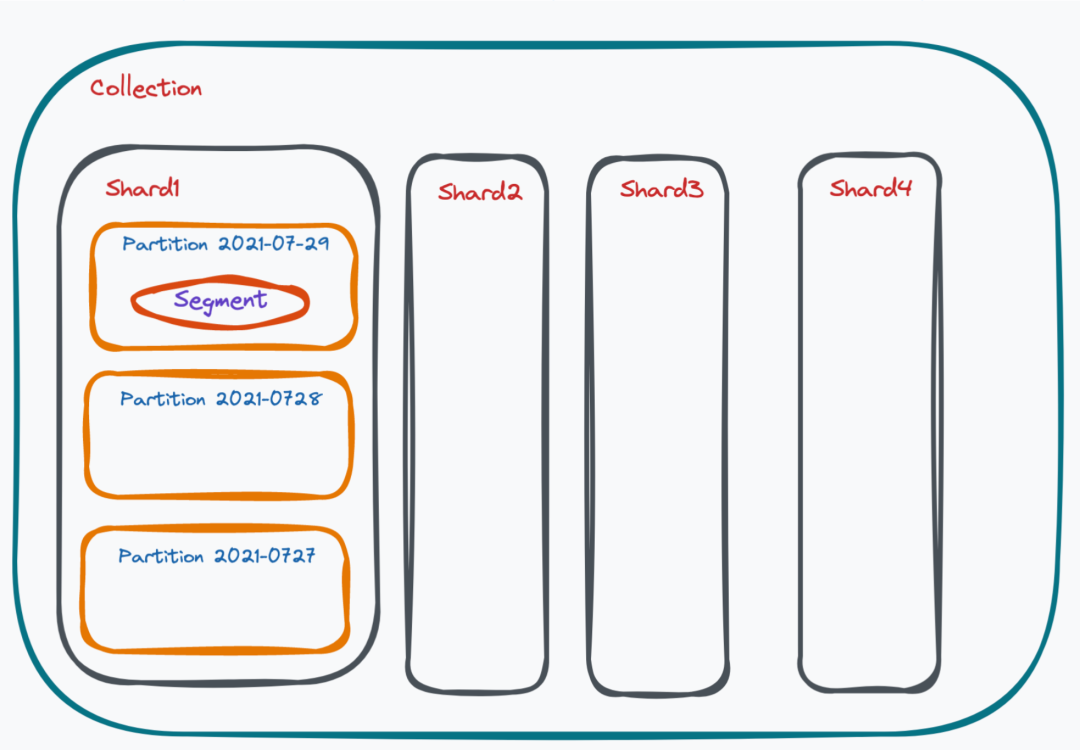
Milvus 的数据模型
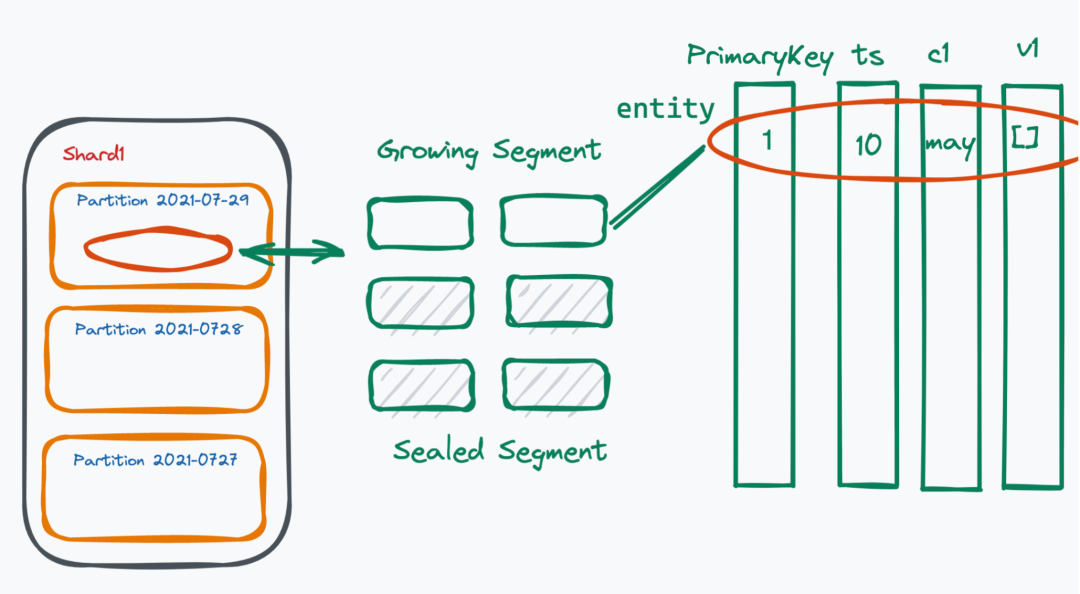
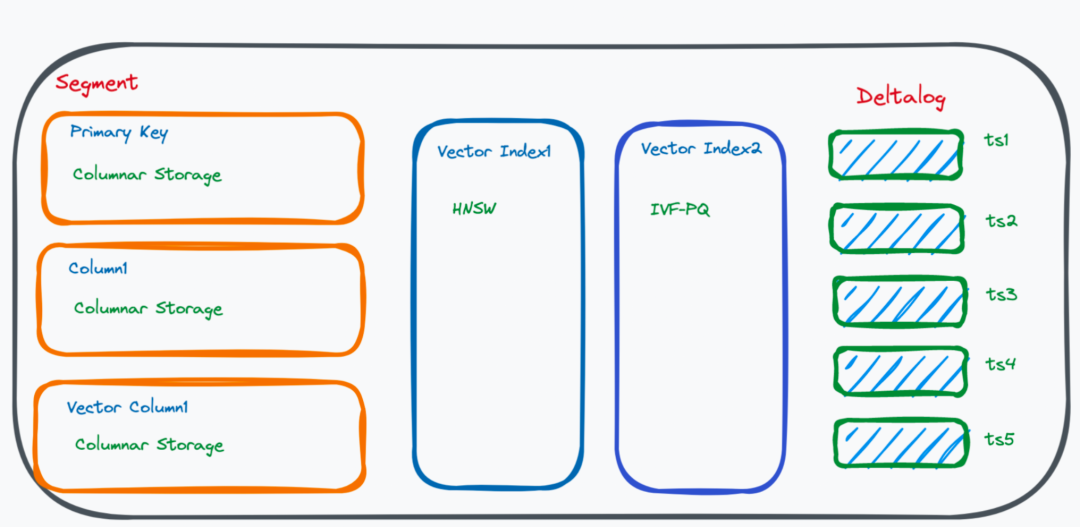
Milvus 数据存储模式
Milvus 代码阅读注意事项
准备工作
学习路径
等我熟悉了 Milvus,我可以……
 阅读原文,解锁更多应用场景
阅读原文,解锁更多应用场景
评论