
【底层原理】一层层剥开Linux文件系统的面纱(一)
文件系统
概述
提到文件系统,Linux的老江湖们对这个概念当然不会陌生,然而刚接触Linux的新手们就会被文件系统这个概念弄得晕头转向,恰好我当年正好属于后者。
从windows下转到Linux的童鞋听到最多的应该是fat32和ntfs(在windows 2000之后所出现的一种新型的日志文件系统),那个年代经常听到说“我要把C盘格式化成ntfs格式,D盘格式化成fat32格式”。
一到Linux下,很多入门Linux的书籍中当牵扯到文件系统这个术语时,二话不说,不管三七二十一就给出了下面这个图,然后逐一解释一下每个目录是拿来干啥的、里面会放什么类型的文件就完事儿了,弄得初学者经常“丈二和尚摸不着头脑”。
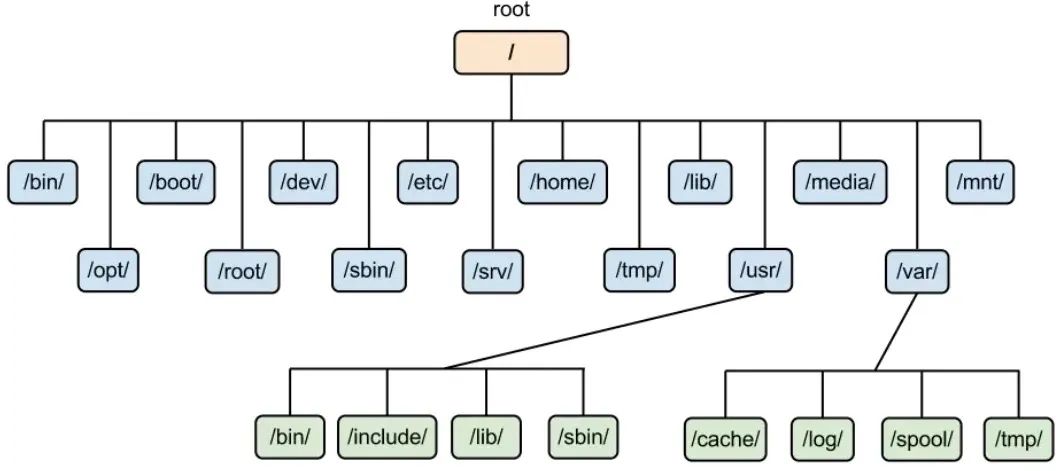
本文的目的就是和大家分享一下我当初是如何学习Linux的文件系统的,也算是一个“老”油条的一些心得吧。
“文件系统”的主语是“文件”,那么文件系统的意思就是“用于管理文件的(管理)系统”,在大多数操作系统教材里,“文件是数据的集合”这个基本点是一致的,而这些数据最终都是存储在存储介质里,如硬盘、光盘、U盘等。
另一方面,用户在管理数据时也是文件为基本单位,他们所关心的问题是:
• 1.我的文件在什么地方放着?
• 2.我如何将数据存入某个文件?
• 3.如何从文件里将数据读出来?
• 4.不再需要的文件怎么将其删除?
简而言之,文件系统就是一套用于定义文件的命名和组织数据的规范,其根本目的是便对文件进行查询和存取。
虚拟文件系统VFS
在Linux早期设计阶段,文件系统与内核代码是整合在一起的,这样做的缺点是显而易见的。假如,我的系统只能识别ext3格式的文件系统,我的U盘是fat32格式,那么很不幸的是我的U盘将不会被我的系统所识别,
为了支持不同种类的文件系统,Linux采用了在Unix系统中已经广泛采用的设计思想,通过虚拟文件系统VFS来屏蔽下层各种不同类型文件系统的实现细节和差异。
其实VFS最早是由Sun公司提出的,其基本思想是将各种文件系统的公共部分抽取出来,形成一个抽象层。对用户的应用程序而言,VFS提供了文件系统的系统调用接口。而对具体的文件系统来说,VFS通过一系列统一的外部接口屏蔽了实现细节,使得对文件的操作不再关心下层文件系统的类型,更不用关心具体的存储介质,这一切都是透明的。
ext2文件系统
虚拟文件系统VFS是对各种文件系统的一个抽象层,抽取其共性,以便对外提供统一管理接口,便于内核对不同种类的文件系统进行管理。那么首先我们得看一下对于一个具体的文件系统,我们该关注重点在哪里。
对于存储设备(以硬盘为例)上的数据,可分为两部分:
• 用户数据:存储用户实际数据的部分;
• 管理数据:用于管理这些数据的部分,这部分我们通常叫它元数据(metadata)。
我们今天要讨论的就是这些元数据。这里有个概念首先需要明确一下:块设备。所谓块设备就是以块为基本读写单位的设备,支持缓冲和随机访问。每个文件系统提供的mk2fs.xx工具都支持在构建文件系统时由用户指定块大小,当然用户不指定时会有一个缺省值。
我们知道一般硬盘的每个扇区512字节,而多个相邻的若干扇区就构成了一个簇,从文件系统的角度看这个簇对应的就是我们这里所说块。用户从上层下发的数据首先被缓存在块设备的缓存里,当写满一个块时数据才会被发给硬盘驱动程序将数据最终写到存储介质上。如果想将设备缓存中数据立即写到存储介质上可以通过sync命令来完成。
块越大存储性能越好,但浪费比较严重;块越小空间利用率较高,但性能相对较低。如果你不是专业的“骨灰级”玩儿家,在存储设备上构建文件系统时,块大小就用默认值。通过命令“tune2fs -l /dev/sda1”可以查看该存储设备上文件系统所使用的块大小:
[root@localhost ~]#tune2fs -l /dev/sda1
tune2fs 1.39 (29-May-2006)
Filesystem volume name: /boot
Last mounted on:
Filesystem UUID: 6ade5e49-ddab-4bf1-9a45-a0a742995775
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 38152
Block count: 152584
Reserved block count: 7629
Free blocks: 130852
Free inodes: 38111
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 256
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2008
Inode blocks per group: 251
Filesystem created: Thu Dec 13 00:42:52 2012
Last mount time: Tue Nov 20 10:35:28 2012
Last write time: Tue Nov 20 10:35:28 2012
Mount count: 12
Maximum mount count: -1
Last checked: Thu Dec 13 00:42:52 2012
Check interval: 0 ()
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Journal inode: 8
Default directory hash: tea
Directory Hash Seed: 72070587-1b60-42de-bd8b-a7b7eb7cbe63
Journal backup: inode blocks
该命令已经暴露了文件系统的很多信息,接下我们将详细分析它们。
下图是我的虚拟机的情况,三块IDE的硬盘。容量分别是:
hda: 37580963840/(102410241024)=35GB
hdb: 8589934592/(102410241024)=8GB
hdd: 8589934592/(102410241024)=8GB
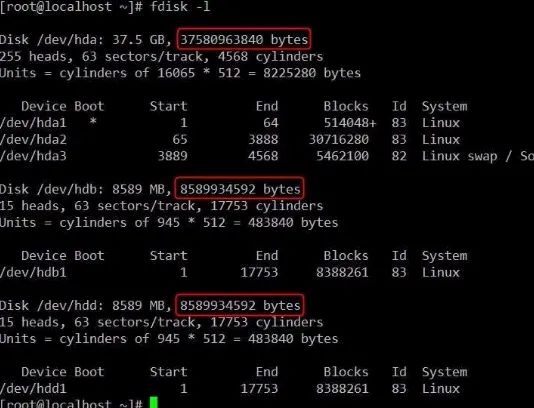
如果这是三块实际的物理硬盘的话,厂家所标称的容量就分别是37.5GB、8.5GB和8.5GB。可能有些童鞋觉得虚拟机有点“假”,那么我就来看看实际硬盘到底是个啥样子。
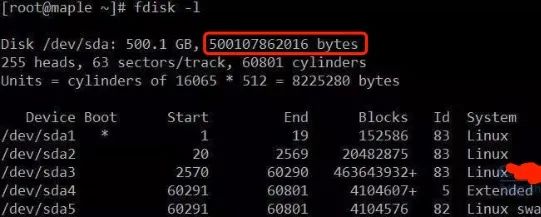
主角1:西部数据 500G SATA接口 CentOS 5.5
实际容量:500107862016B = 465.7GB
主角2:希捷 160G SCSI接口 CentOS 5.5
实际容量:160041885696B=149GB

大家可以看到,VMware公司的水平还是相当不错的,虚拟硬盘和物理硬盘“根本”看不出差别,毕竟属于云平台基础架构支撑者的风云人物嘛。
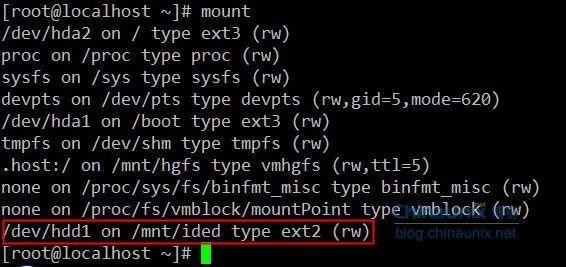
以硬盘/dev/hdd1为例,它是我新增的一块新盘,格式化成ext2后,根目录下只有一个lost+found目录,让我们来看一下它的布局情况,以此来开始我们的文件系统之旅。
对于使用了ext2文件系统的分区来说,有一个叫superblock的结构 ,superblock的大小为1024字节,其实ext3的superblock也是1024字节。下面的小程序可以证明这一点:
#include <stdio.h>
#include <linux/ext2_fs.h>
#include <linux/ext3_fs.h>
int main(int argc,char** argv){
printf("sizeof of ext2 superblock=%d\n",sizeof(struct ext2_super_block));
printf("sizeof of ext3 superblock=%d\n",sizeof(struct ext3_super_block));
return 0;
}
******************【运行结果】******************
sizeof of ext2 superblock=1024
sizeof of ext3 superblock=1024硬盘的第一个字节是从0开始编号,所以第一个字节是byte0,以此类推。/dev/hdd1分区头部的1024个字节(从byte0~byte1023)都用0填充,因为/dev/hdd1不是主引导盘。superblock是从byte1024开始,占1024B存储空间。我们用dd命令把superblock的信息提取出来:
dd if=/dev/hdd1 of=./hdd1sb bs=1024 skip=1 count=1上述命令将从/dev/hdd1分区的byte1024处开始,提取1024个字节的数据存储到当前目录下的hdd1sb文件里,该文件里就存储了我们superblock的所有信息,上面的程序稍加改造,我们就可以以更直观的方式看到superblock的输出了如下:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <linux/ext2_fs.h>
#include <linux/ext3_fs.h>
int main(int argc,char** argv){
printf("sizeof of ext2 superblock=%d\n",sizeof(struct ext2_super_block));
printf("sizeof of ext3 superblock=%d\n",sizeof(struct ext3_super_block));
char buf[1024] = {0};
int fd = -1;
struct ext2_super_block hdd1sb;
memset(&hdd1sb,0,1024);
if(-1 == (fd=open("./hdd1sb",O_RDONLY,0777))){
printf("open file error!\n");
return 1;
}
if(-1 == read(fd,buf,1024)){
printf("read error!\n");
close(fd);
return 1;
}
memcpy((char*)&hdd1sb,buf,1024);
printf("inode count : %ld\n",hdd1sb.s_inodes_count);
printf("block count : %ld\n",hdd1sb.s_blocks_count);
printf("Reserved blocks count : %ld\n",hdd1sb.s_r_blocks_count);
printf("Free blocks count : %ld\n",hdd1sb.s_free_blocks_count);
printf("Free inodes count : %ld\n",hdd1sb.s_free_inodes_count);
printf("First Data Block : %ld\n",hdd1sb.s_first_data_block);
printf("Block size : %ld\n",1<<(hdd1sb.s_log_block_size+10));
printf("Fragment size : %ld\n",1<<(hdd1sb.s_log_frag_size+10));
printf("Blocks per group : %ld\n",hdd1sb.s_blocks_per_group);
printf("Fragments per group : %ld\n",hdd1sb.s_frags_per_group);
printf("Inodes per group : %ld\n",hdd1sb.s_inodes_per_group);
printf("Magic signature : 0x%x\n",hdd1sb.s_magic);
printf("size of inode structure : %d\n",hdd1sb.s_inode_size);
close(fd);
return 0;
}
******************【运行结果】******************
inode count : 1048576
block count : 2097065
Reserved blocks count : 104853
Free blocks count : 2059546
Free inodes count : 1048565
First Data Block : 0
Block size : 4096
Fragment size : 4096
Blocks per group : 32768
Fragments per group : 32768
Inodes per group : 16384
Magic signature : 0xef53
size of inode structure : 128可以看出,superblock 的作用就是记录文件系统的类型、block大小、block总数、inode大小、inode总数、group的总数等信息。
对于ext2/ext3文件系统来说数字签名Magic signature都是0xef53,如果不是那么它一定不是ext2/ext3文件系统。这里我们可以看到,我们的/dev/hdd1确实是ext2文件系统类型。hdd1中一共包含1048576个inode节点(inode编号从1开始),每个inode节点大小为128字节,所有inode消耗的存储空间是1048576×128=128MB;总共包含2097065个block,每个block大小为4096字节,每32768个block组成一个group,所以一共有2097065/32768=63.99,即64个group(group编号从0开始,即Group0~Group63)。所以整个/dev/hdd1被划分成了64个group,详情如下:
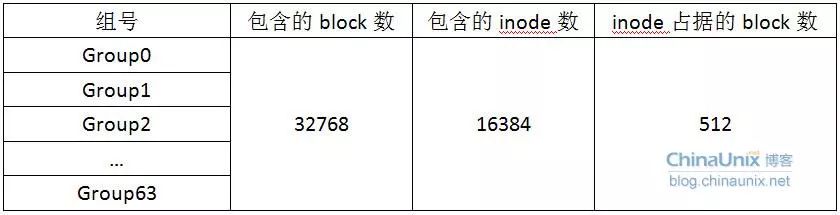
用命令tune2fs可以验证我们之前的分析:

再通过命令dumpe2fs /dev/hdd1的输出,可以得到我们关注如下部分:
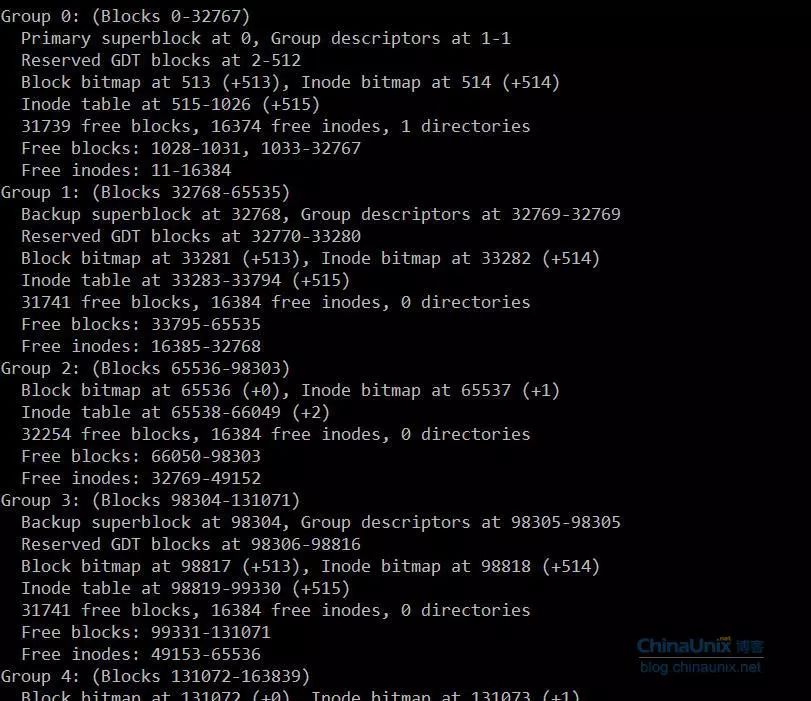
接下来以Group0为例,主superblock在Group0的block0里,根据前面的分析,我们可以画出主superblock在block0中的位置如下:

因为superblock是如此之重要,一旦它出错你的整个系统就玩儿完了,所以文件系统中会存在磁盘的多个不同位置会存在主superblock的备份副本,一旦系统出问题后还可以通过备份的superblock对文件系统进行修复。
第一版ext2文件系统的实现里,每个Group里都存在一份superblock的副本,然而这样做的负面效果也是相当明显,那就是严重降低了磁盘的空间利用率。所以在后续ext2的实现代码中,选择用于备份superblock的Group组号的原则是3的N次方、5的N次方、7的N次方其中N=0,1,2,3…。根据这个公式我们来计算一下/dev/hdd1中备份有supeblock的Group号:
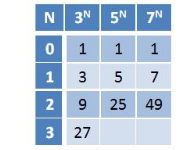
也就是说Group1、3、5、7、9、25、27、49里都保存有superblock的拷贝,如下:
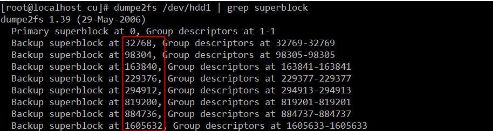
用block号分别除以32768就得到了备份superblock的Group号,和我们在上面看到的结果一致。我们来看一下/dev/hdd1中Group和block的关系:
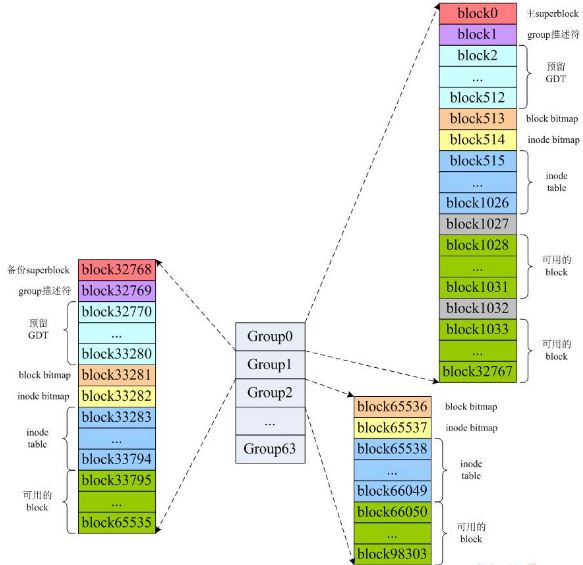
从上图中我们可以清晰地看出在使用了ext2文件系统的分区上,包含有主superblock的Group、备份superblock的Group以及没有备份superblock的Group的布局情况。存储了superblock的Group中有一个组描述符(Group descriptors)紧跟在superblock所在的block后面,占一个block大小;同时还有个Reserved GDT跟在组描述符的后面。
Reserved GDT的存在主要是支持ext2文件系统的resize功能,它有自己的inode和data block,这样一来如果文件系统动态增大,Reserved GDT就正好可以腾出一部分空间让Group descriptor向下扩展。
— 完 —