
UnicodeEncodeError: 'gbk' codec can't encode character解决方法
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
前言
前几天有个叫【低端玩家.】的粉丝在Python交流群里问了一道关于requests库请求后,出现编码错误的问题,如下图所示。
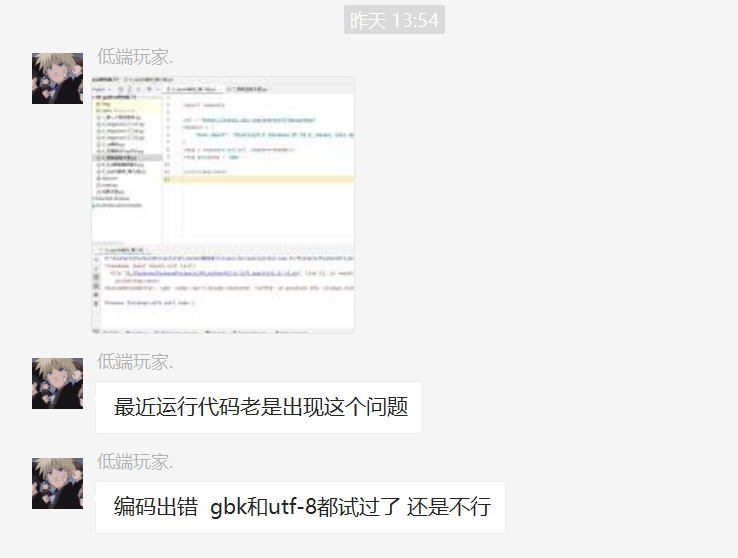
粉丝也说了,同样代码,别人都能运行,但是他这个就不行,真是头大。
一、思路
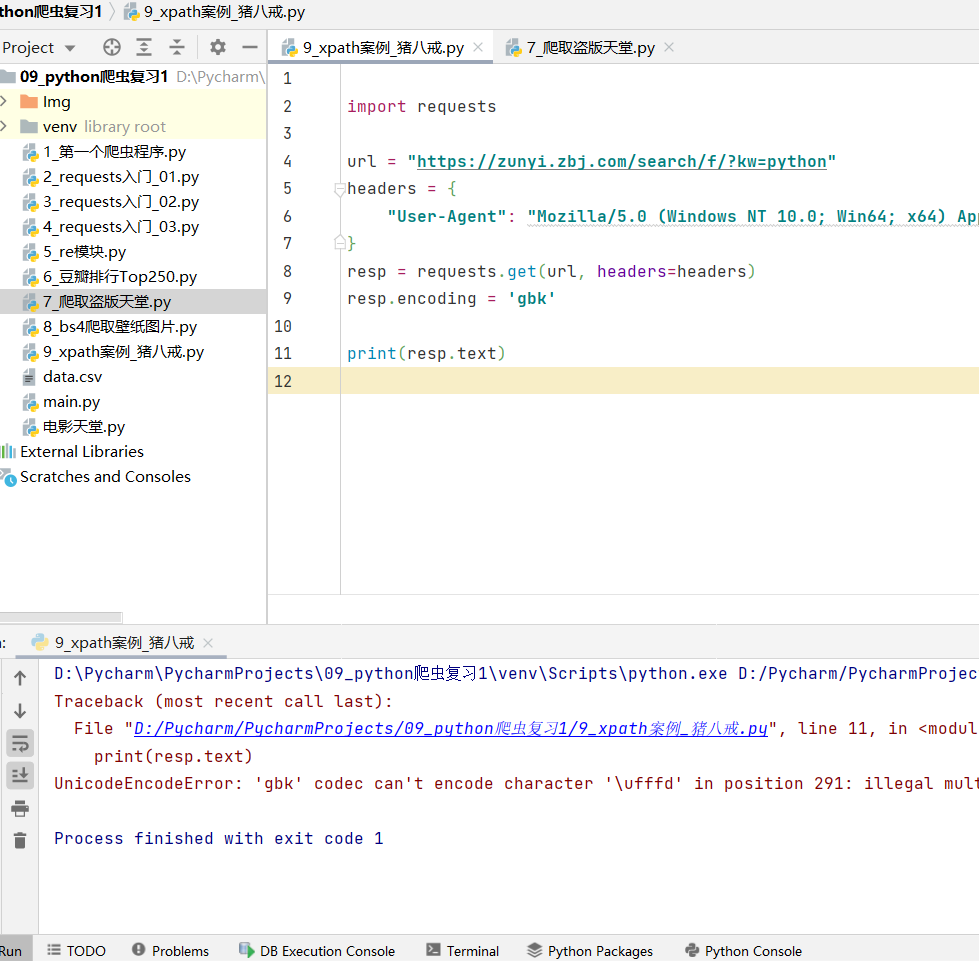
其实问题的关键点就是在于编码和解码的问题,首先要确定网站的编码方式,剩下的就是自己电脑中的Pycharm编码设置的问题了。一般来说,苹果机默认就是utf-8编码,所以苹果机中的编码问题一般比较少,但是其他机型就不好说了,一般默认的编码是gbk,所以需要进行转编码。这也是为什么在苹果机下使用open()函数,不指定编码格式,抓取下来的网页或者数据是不会乱码的,而使用其他机型抓取的情况下,不指定编码,就会乱码的原因所在了。
二、解决方法
response.text.encode('utf-8').decode('utf-8')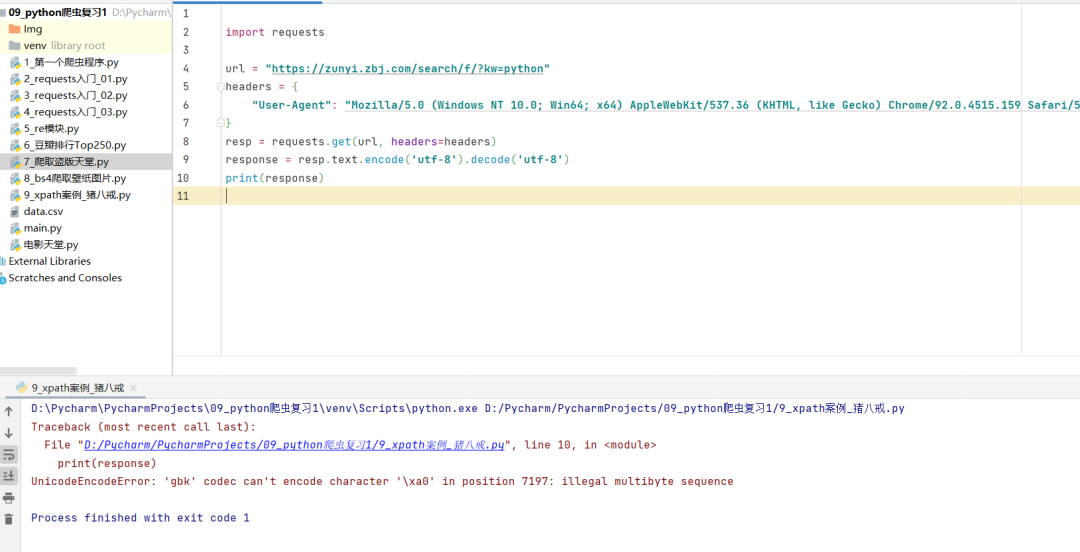
我看了下他的代码,是没毛病的,而且网页的编码就是utf-8,编码没问题,那么只能是Pycharm中的编码设置的问题了。
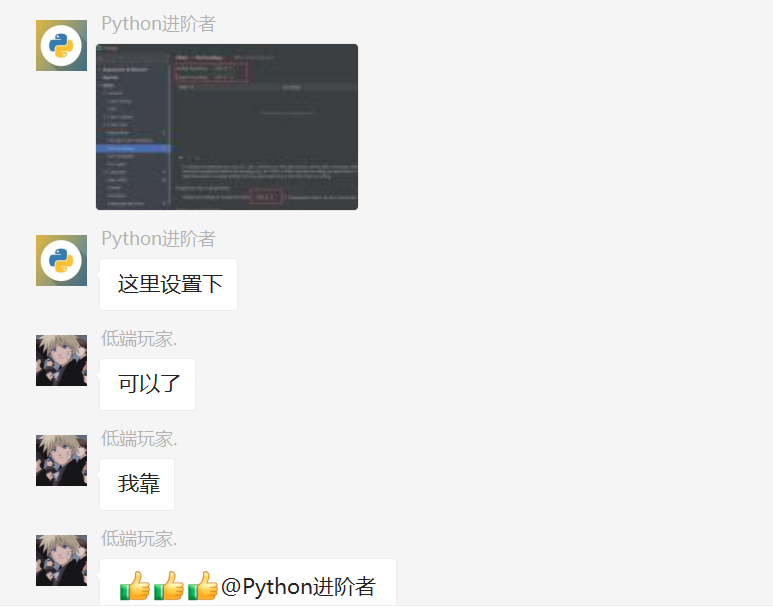
在setting里边指定编码为utf-8,就可以解决问题了,如下图所示。
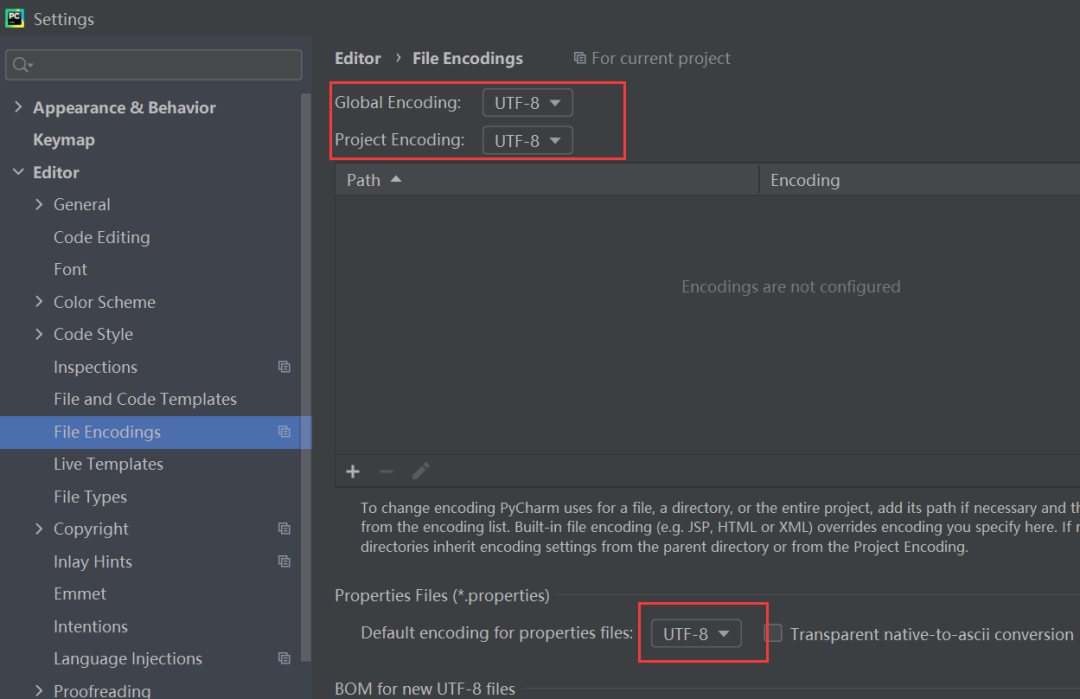
这里设置好之后,然后运行代码,就可以正常跑了,不会出现报错了。
【拓展知识】
下次小伙伴们有遇到类似这种'\u7535\u5546'编码报错问题,确定在Pycharm里边确定为utf-8编码的情况下,可以使用下面的解决方式,小编屡试不爽:
text = '\u7535\u5546'print(text.encode('utf-8').decode('utf-8'))
好了,今天的文章就分享到这里了,希望对大家的学习有帮助。
三、总结
我是Python进阶者。本文基于粉丝提问,针对编码问题,主要从两个方面进行出发,其一是网页编码,其二是Pycharm编码,顺利解决这个小bug。小编相信小伙伴们在实际敲代码的过程中,肯定还有遇到其他的编码bug,也欢迎大家在评论区谏言。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~