
HTTP/3发布了,我们来谈谈HTTP/3
经过了多年的努力,在 6 月 6 号,IETF (互联网工程任务小组) 正式发布了 HTTP/3 的 RFC, 这是超文本传输协议(HTTP)的第三个主要版本,完整的 RFC 超过了 20000 字,非常详细的解释了 HTTP/3。

HTTP 历史

1991 HTTP/1.1 2009 Google 设计了基于TCP的SPDY 2013 QUIC 2015 HTTP/2 2018 HTTP/3
QUIC 协议概览
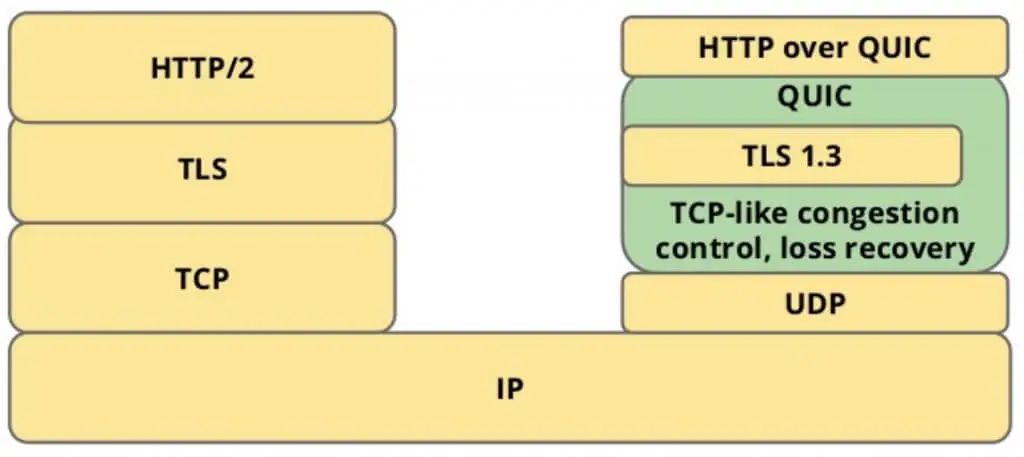
HTTP over QUIC即HTTP/3的含义HTTP/3, QUIC是绕不过去的, 下面是几个重要的QUIC特性.0 RTT建立连接
RTT: round-trip time, 仅包括请求访问来回的时间
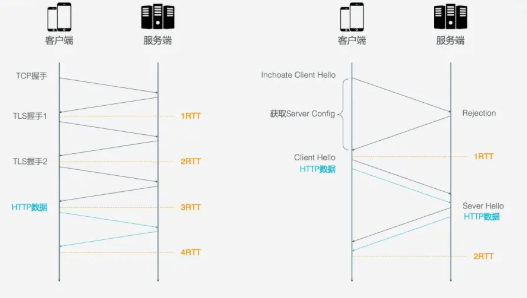
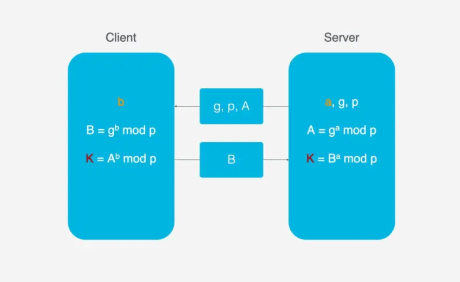
HTTP/2的连接建立需要3 RTT, 如果考虑会话复用, 即把第一次握手计算出来的对称密钥缓存起来, 那也需要2 RTT. 更进一步的, 如果TLS升级到1.3, 那么HTTP/2连接需要2RTT, 考虑会话复用需要1RTT. 如果HTTP/2不急于HTTPS, 则可以简化, 但实际上几乎所有浏览器的设计都要求HTTP/2需要基于HTTPS.HTTP/3首次连接只需要1RTT, 后面的链接只需要0RTT, 意味着客户端发送给服务端的第一个包就带有请求数据, 其主要连接过程如下:首次连接, 客户端发送 Inchoate Client Hello, 用于请求连接;服务端生成g, p, a, 根据g, p, a算出A, 然后将g, p, A放到Server Config中在发送 Rejection消息给客户端.客户端接收到g,p,A后, 自己再生成b, 根据g,p,a算出B, 根据A,p,b算出初始密钥K, B和K算好后, 客户端会用K加密HTTP数据, 连同B一起发送给服务端. 服务端接收到B后, 根据a,p,B生成与客户端同样的密钥, 再用这密钥解密收到的HTTP数据. 为了进一步的安全(前向安全性), 服务端会更新自己的随机数a和公钥, 在生成新的密钥S, 然后把公钥通过 Server Hello发送给客户端. 连同Server Hello消息, 还有HTTP返回数据.
连接迁移
Connection ID, 即使IP或者端口发生变化, 只要Connection ID没有变化, 那么连接依然可以维持.队头阻塞/多路复用
HTTP/1.1和HTTP/2都存在队头阻塞的问题(Head Of Line blocking).ACK消息, 以确认对象已接受数据. 如果每次请求都要在收到上次请求的ACK消息后再请求, 那么效率无疑很低. 后来HTTP/1.1提出了Pipeline技术, 允许一个TCP连接同时发送多个请求. 这样就提升了传输效率.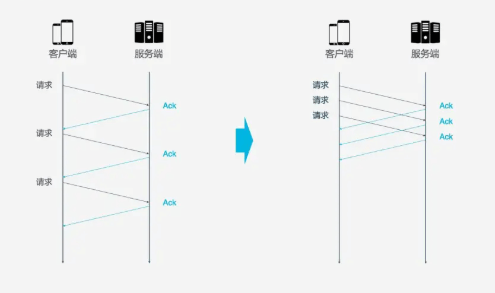
Frame通过一条TCP连接同时被传输, 这样即使一个请求被阻塞, 也不会影响其他的请求.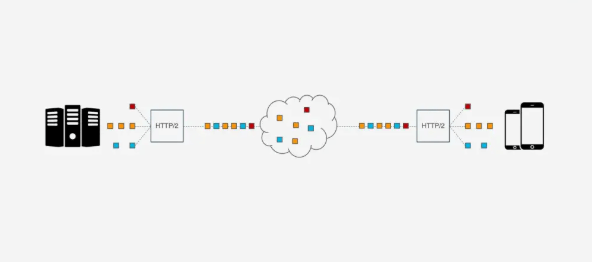
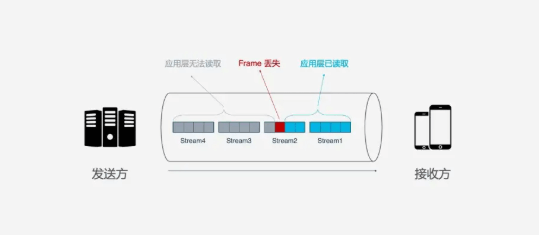
但是, HTTP/2虽然可以解决请求这一粒度下的阻塞, 但HTTP/2的基础TCP协议本身却也存在队头阻塞的问题. HTTP/2的每个请求都会被拆分成多个Frame, 不同请求的Frame组合成Stream, Stream是TCP上的逻辑传输单元, 这样HTTP/2就达到了一条连接同时发送多个请求的目标, 其中Stram1已经正确送达, Stram2中的第三个Frame丢失, TCP处理数据是有严格的前后顺序, 先发送的Frame要先被处理, 这样就会要求发送方重新发送第三个Frame, Steam3和Steam4虽然已到达但却不能被处理, 那么这时整条链路都会被阻塞.
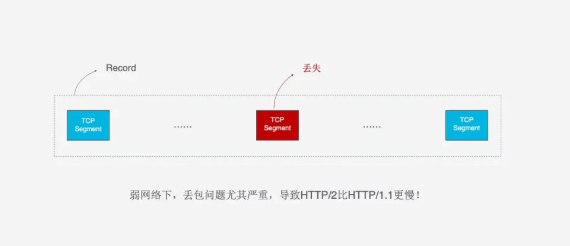
QUIC的传输单位是Packet, 加密单元也是Packet, 整个加密, 传输, 解密都基于Packet, 这就能避免TLS的阻塞问题. QUIC基于UDP, UDP的数据包在接收端没有处理顺序, 即使中间丢失一个包, 也不会阻塞整条连接. 其他的资源会被正常处理.
拥塞控制
慢启动: 发送方像接收方发送一个单位的数据, 收到确认后发送2个单位, 然后是4个, 8个依次指数增长, 这个过程中不断试探网络的拥塞程度. 避免拥塞: 指数增长到某个限制之后, 指数增长变为线性增长 快速重传: 发送方每一次发送都会设置一个超时计时器, 超时后认为丢失, 需要重发 快速恢复: 在上面快速重传的基础上, 发送方重新发送数据时, 也会启动一个超时定时器, 如果收到确认消息则进入拥塞避免阶段, 如果仍然超时, 则回到慢启动阶段.
1. 热插拔
2. 前向纠错 FEC
3. 单调递增的Packer Number
Sequence Number和ACK来确认消息是否有序到达, 但这样的设计存在缺陷.RTT: Round Trip Time, 往返事件 RTO: Retransmission Timeout, 超时重传时间
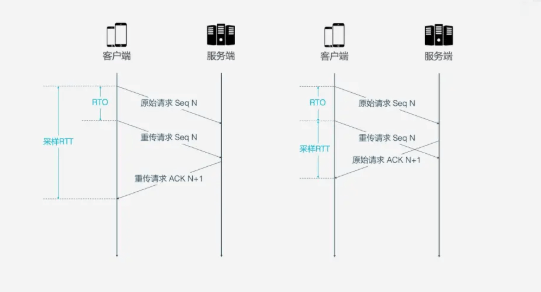
Sequence Number不同, Packet Number严格单调递增, 如果Packet N丢失了, 那么重传时Packet的标识就不会是N, 而是比N大的数字, 比如N+M, 这样发送方接收到确认消息时, 就能方便的知道ACK对应的原始请求还是重传请求.4. ACK Delay
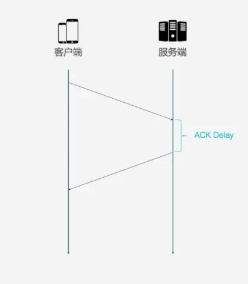
5. 更多的ACK块
ACK, 而QUIC最多可以捎带256个ACK block, 在丢包率比较严重的网络下, 更多的ACK可以减少重传量, 提升网络效率.浏览控制
Stream, 好比有一条道路, 量都分别有一个仓库, 道路中有很多车辆运送物资. QUIC的流量控制有两个级别: 连接级别(Connection Level)和Stream 级别(Stream Level).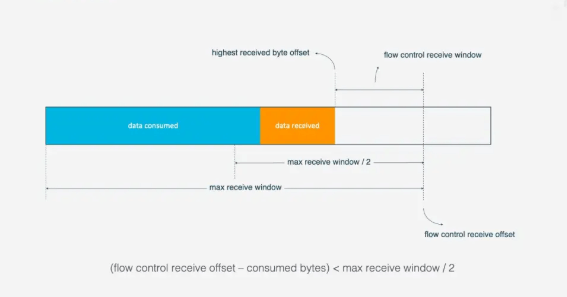
(flow control receivce offset - consumed bytes) < (max receive window/2)时, 接收方会发送WINDOW_UPDATE frame告诉发送方你可以再多发送数据, 这时候flow control receive offset就会偏移, 接收窗口增大, 发送方可以发送更多数据到接收方.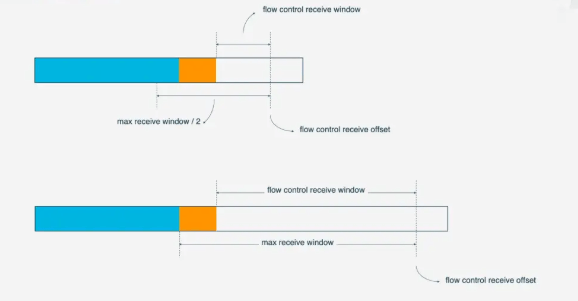
Stream级别对防止接收端接收过多数据作用有限, 更需要借助Connection级别的流量控制. 理解了Stream流量那么也很好理解Connection的流控. Stream中,
接收窗口=最大接受窗口 - 已接收数据而对于Connection来说:接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + ... + StreamN 接收窗口参考链接
HTTP/3 原理实战 (https://mp.weixin.qq.com/s?__biz=MjM5ODYwMjI2MA==&mid=2649746858&idx=1&sn=26e90bb6dde7541fb9fe9f121eb11984&scene=21#wechat_redirect)
作者:shuerbuzuo
来源:http://know.shuerbuzuo.cn/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/HTTP3.html#%E6%B5%8F%E8%A7%88%E6%8E%A7%E5%88%B6
版权申明:内容来源网络,仅供分享学习,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
END
推荐阅读
END
一键生成Springboot & Vue项目!【毕设神器】
Java可视化编程工具系列(一)
Java可视化编程工具系列(二)
顺便给大家推荐一个GitHub项目,这个 GitHub 整理了上千本常用技术PDF,绝大部分核心的技术书籍都可以在这里找到,
GitHub地址:https://github.com/javadevbooks/books
电子书已经更新好了,你们需要的可以自行下载了,记得点一个star,持续更新中..

顺便给大家推荐一个GitHub项目,这个 GitHub 整理了上千本常用技术PDF,绝大部分核心的技术书籍都可以在这里找到,
GitHub地址:https://github.com/javadevbooks/books
电子书已经更新好了,你们需要的可以自行下载了,记得点一个star,持续更新中..