
NumPy进阶80题完整版|附Notebook版本下载
点击上方“早起Python”,关注并“星标”
每日接收精彩Python干货!
本文是NumPy进阶修炼系列的第八篇
前言
完整版NumPy80题
Notebook版下载方式
NumPy进阶修炼80题完整版
import numpy as np
print(np.__version__)array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])np.zeros(10)np.zeros(10,dtype = 'int')array([ 0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80,
85, 90, 95])np.arange(0,100,5)List = [1,2,3,4,5,6,7,8,9]result = np.array(List)#方法1
np.ones((3,3))
#方法2
np.array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])array([[ True, True],
[ True, True]])np.full((2,2), True, dtype=bool)np.linspace(start=5,stop=50,num=10)np.arange(start = 5, stop = 55, step = 5,dtype = 'int32')备注2:思考与上一题的不同
np.random.randint(0,10,(3,3))np.random.randn(3, 3)result = result.reshape(3,3)result.Tresult.dtype
#dtype('int64')#方法一:直接查看
result.nbytes
#方法2
手动计算
result.itemsize * 9
#72result = result.astype(float)result[2,2]result[2,2] = result[2,2] * 10array([ 2., 4., 6., 8., 90.])result[result % 2 == 0]result[result % 2 == 1] = 666result = np.diag([5,5,5,5,5])a = result[:, [1,0,2,3,4]]result[result % 2 == 1] = 666print((a == b).all())len(np.argwhere(a != b))np.argwhere(a != b)np.dot(a,b)print(np.multiply(a,b))
print('========方法2========')
print(a * b) #方法2np.linalg.det(result)np.linalg.inv(result)a = np.matrix(a)
b = np.matrix(b)np.multiply(a,b)a * bnp.hstack((a,b))np.vstack((a,b))new = np.pad(result,pad_width = 1,constant_values=1)np.argwhere(new > 1)new[new > 1] = 8np.sum(new, 0)np.sum(new, 1)data = np.random.randint(1,100, [6,6])np.amax(data, axis=0)np.amin(data, axis=1)np.unique(data,return_counts=True)data.argsort()np.repeat(data, 2, axis=0)np.unique(data,axis = 0)np.random.choice(data[0:1][0], 3, replace=False)a = data[1:2]
b = data[2:3]
index=np.isin(a,b)
array=a[~index]
array(~data.any(axis=1)).any()data.sort(axis = 1)data1 = data.astype(float)思考:为什么不能在data本身转换
data1[data1 < 5] = np.nandata1 = data1[~np.isnan(data1).any(axis=1), :]vals, counts = np.unique(data1[0,:], return_counts=True)
print(vals[np.argmax(counts)])a = 100
data1.flat[np.abs(data1 - a).argmin()]data1 - data1.mean(axis=1, keepdims=True)a = np.max(data1) - np.min(data1)
(data1 - np.min(data1)) / amu = np.mean(data1, axis=0)
sigma = np.std(data1, axis=0)
(data1 - mu) / sigmanp.savetxt('test.txt',data1)import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
arr1 = np.random.randint(10,6,6)
arr2 = np.random.randint(10,6,6)arr1 = np.random.randint(10,6,6)
arr2 = np.random.randint(10,6,6)
print("arr1: %s"%arr1)
print("arr2: %s"%arr2)
np.intersect1d(arr1,arr2)
arr1 = np.random.randint(10,6,6)
arr2 = np.random.randint(10,6,6)arr1 = np.random.randint(1,10,10)
arr2 = np.random.randint(1,10,10)
print("arr1: %s"%arr1)
print("arr2: %s"%arr2)
np.setdiff1d(arr1,arr2)
arr1 = np.random.randint(1,10,10)arr1 = np.random.randint(1,10,10)
arr1.flags.writeable = False
a = [1,2,3,4,5]a = [1,2,3,4,5]
np.array(a)
df = pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]})df.values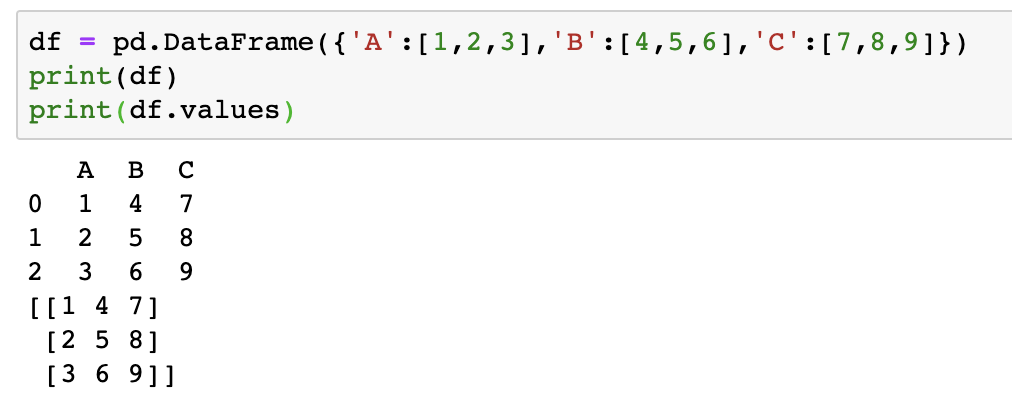
arr1 = np.random.randint(1,10,10)
arr2 = np.random.randint(1,10,10)arr1 = np.random.randint(1,10,10)
arr2 = np.random.randint(1,10,10)
print("arr1的平均数为:%s" %np.mean(arr1))
print("arr1的中位数为:%s" %np.median(arr1))
print("arr1的方差为:%s" %np.var(arr1))
print("arr1的标准差为:%s" %np.std(arr1))
print("arr1,arr的相关性矩阵为:%s" %np.cov(arr1,arr2))
print("arr1,arr的协方差矩阵为:%s" %np.corrcoef(arr1,arr2))
arr = np.array([1,2,3,4,5])arr = np.array([1,2,3,4,5])
np.random.choice(arr,10,p = [0.1,0.1,0.1,0.1,0.6])
arr = np.array([1,2,3,4,5])#对副本数据进行修改,不会影响到原始数据
arr = np.array([1,2,3,4,5])
arr1 = arr.copy()arr = np.arange(10)arr = np.arange(10)
a = slice(2,8,2)
arr[a] #等价于arr[2:8:2]
str1 = ['I love']
str2 = [' Python']#拼接字符串
str1 = ['I love']
str2 = [' Python']
print(np.char.add(str1,str2))
#大写首字母
str3 = np.char.add(str1,str2)
print(np.char.title(str3))
arr = np.random.uniform(0,10,10)arr = np.random.uniform(0,10,10)
print(arr)
###向上取整
print(np.ceil(arr))
###向下取整
print(np.floor(arr) )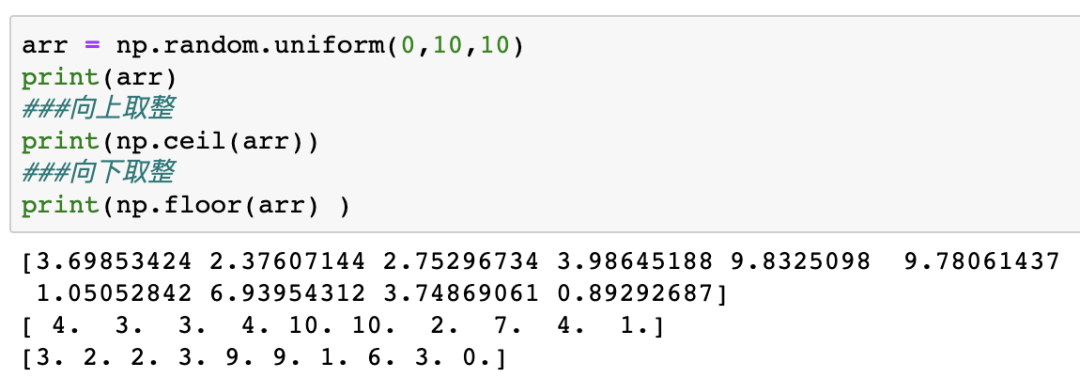
np.set_printoptions(suppress=True)arr = np.random.randint(1,10,[3,3])arr = np.random.randint(1,10,[3,3])
print(arr)
print('列逆序')
print(arr[:, -1::-1])
print('行逆序')
print(arr[-1::-1, :])
arr1 = np.random.randint(1,10,5)
arr2 = np.random.randint(1,20,10)arr1 = np.random.randint(1,10,5)
arr2 = np.random.randint(1,20,10)
print(arr1)
print(arr2)
print(np.take(arr2,arr1))
a = 10
b = 3np.mod(a,b)A = np.random.randint(1,10,[3,3])np.linalg.svd(A)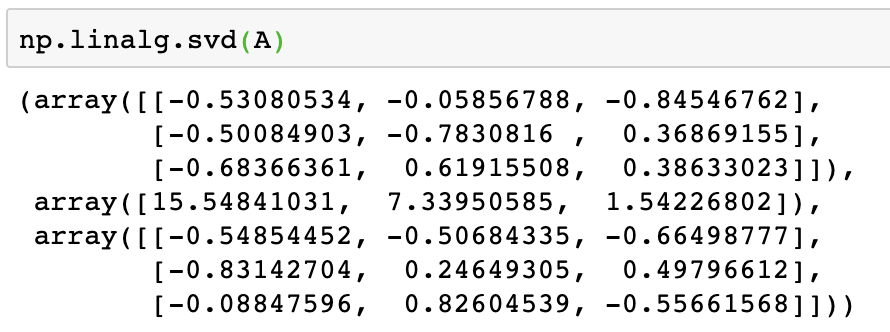
arr = np.random.randint(1,20,10)arr = np.random.randint(1,20,10)
print(arr[(arr>1)&(arr<7)&(arr%2==0)])arr = np.random.randint(1,20,10)arr = np.random.randint(1,20,10)
print(arr)
print(np.piecewise(arr, [arr < 3, arr >= 7], [-1, 1]))
arr = np.random.randint(1,10,[3,1])arr = np.random.randint(1,10,[3,1])
print(arr)
print(np.squeeze(arr))
A = np.array([[1, 2, 3], [2, -1, 1], [3, 0, -1]])
b = np.array([9, 8, 3])A = np.array([[1, 2, 3], [2, -1, 1], [3, 0, -1]])
b = np.array([9, 8, 3])
x = np.linalg.solve(A, b)
print(x)
下载方式

一份有答案版本用来参考学习?


在后台回复numpy即可下载完整的NumPy80题,因为我每题仅给出一种解法,因此在刷题过程中也应该思考是否有不一样/更高效的方法,结合Pandas120题使用更是威力无穷!另外Python数据可视化同款专题正在准备中,敬请期待!
还想了解更多干货?
关注早起Python,查看更多精彩文章↓
还想了解更多干货?
关注早起Python,查看更多精彩文章↓
觉得这篇文章还不错?点亮「在看」鼓励一下早起!
觉得这篇文章还不错?点亮「在看」鼓励一下早起!
- THE END



评论