
消息队列之推还是拉,RocketMQ 和 Kafka是如何做的?
今天我们就来谈一谈消息队列的推拉模式,这也是一个面试热点,例如你在简历里面写了 RocketMQ ,基本上会问你 RocketMQ 采用的是推模式还是拉模式啊?是拉模式?不是有 PushConsumer 吗?
今天我们就来谈谈推拉模式,并且再来看看 RocketMQ 和 Kafka 是如何做的。
推拉模式
首先明确一下推拉模式到底是在讨论消息队列的哪一个步骤,一般而言我们在谈论推拉模式的时候指的是 Comsumer 和 Broker 之间的交互。
默认的认为 Producer 与 Broker 之间就是推的方式,即 Producer 将消息推送给 Broker,而不是 Broker 主动去拉取消息。
想象一下,如果需要 Broker 去拉取消息,那么 Producer 就必须在本地通过日志的形式保存消息来等待 Broker 的拉取,如果有很多生产者的话,那么消息的可靠性不仅仅靠 Broker 自身,还需要靠成百上千的 Producer。
Broker 还能靠多副本等机制来保证消息的存储可靠,而成百上千的 Producer 可靠性就有点难办了,所以默认的 Producer 都是推消息给 Broker。
所以说有些情况分布式好,而有些时候还是集中管理好。
推模式
推模式指的是消息从 Broker 推向 Consumer,即 Consumer 被动的接收消息,由 Broker 来主导消息的发送。
我们来想一下推模式有什么好处?
消息实时性高, Broker 接受完消息之后可以立马推送给 Consumer。
对于消费者使用来说更简单,简单啊就等着,反正有消息来了就会推过来。
推模式有什么缺点?
推送速率难以适应消费速率,推模式的目标就是以最快的速度推送消息,当生产者往 Broker 发送消息的速率大于消费者消费消息的速率时,随着时间的增长消费者那边可能就“爆仓”了,因为根本消费不过来啊。当推送速率过快就像 DDos 攻击一样消费者就傻了。
并且不同的消费者的消费速率还不一样,身为 Broker 很难平衡每个消费者的推送速率,如果要实现自适应的推送速率那就需要在推送的时候消费者告诉 Broker ,我不行了你推慢点吧,然后 Broker 需要维护每个消费者的状态进行推送速率的变更。
这其实就增加了 Broker 自身的复杂度。
所以说推模式难以根据消费者的状态控制推送速率,适用于消息量不大、消费能力强要求实时性高的情况下。
拉模式
拉模式指的是 Consumer 主动向 Broker 请求拉取消息,即 Broker 被动的发送消息给 Consumer。
我们来想一下拉模式有什么好处?
拉模式主动权就在消费者身上了,消费者可以根据自身的情况来发起拉取消息的请求。假设当前消费者觉得自己消费不过来了,它可以根据一定的策略停止拉取,或者间隔拉取都行。
拉模式下 Broker 就相对轻松了,它只管存生产者发来的消息,至于消费的时候自然由消费者主动发起,来一个请求就给它消息呗,从哪开始拿消息,拿多少消费者都告诉它,它就是一个没有感情的工具人,消费者要是没来取也不关它的事。
拉模式可以更合适的进行消息的批量发送,基于推模式可以来一个消息就推送,也可以缓存一些消息之后再推送,但是推送的时候其实不知道消费者到底能不能一次性处理这么多消息。而拉模式就更加合理,它可以参考消费者请求的信息来决定缓存多少消息之后批量发送。
拉模式有什么缺点?
消息延迟,毕竟是消费者去拉取消息,但是消费者怎么知道消息到了呢?所以它只能不断地拉取,但是又不能很频繁地请求,太频繁了就变成消费者在攻击 Broker 了。因此需要降低请求的频率,比如隔个 2 秒请求一次,你看着消息就很有可能延迟 2 秒了。
消息忙请求,忙请求就是比如消息隔了几个小时才有,那么在几个小时之内消费者的请求都是无效的,在做无用功。
那到底是推还是拉
可以看到推模式和拉模式各有优缺点,到底该如何选择呢?
RocketMQ 和 Kafka 都选择了拉模式,当然业界也有基于推模式的消息队列如 ActiveMQ。
我个人觉得拉模式更加的合适,因为现在的消息队列都有持久化消息的需求,也就是说本身它就有个存储功能,它的使命就是接受消息,保存好消息使得消费者可以消费消息即可。
而消费者各种各样,身为 Broker 不应该有依赖于消费者的倾向,我已经为你保存好消息了,你要就来拿好了。
虽说一般而言 Broker 不会成为瓶颈,因为消费端有业务消耗比较慢,但是 Broker 毕竟是一个中心点,能轻量就尽量轻量。
那么竟然 RocketMQ 和 Kafka 都选择了拉模式,它们就不怕拉模式的缺点么?怕,所以它们操作了一波,减轻了拉模式的缺点。
长轮询
RocketMQ 和 Kafka 都是利用“长轮询”来实现拉模式,我们就来看看它们是如何操作的。
为了简单化,下面我把消息不满足本次拉取的条数啊、总大小啊等等都统一描述成还没有消息,反正都是不满足条件。
RocketMQ 中的长轮询
RocketMQ 中的 PushConsumer 其实是披着拉模式的方法,只是看起来像推模式而已。
因为 RocketMQ 在被背后偷偷的帮我们去 Broker 请求数据了。
后台会有个 RebalanceService 线程,这个线程会根据 topic 的队列数量和当前消费组的消费者个数做负载均衡,每个队列产生的 pullRequest 放入阻塞队列 pullRequestQueue 中。然后又有个 PullMessageService 线程不断的从阻塞队列 pullRequestQueue 中获取 pullRequest,然后通过网络请求 broker,这样实现的准实时拉取消息。
这一部分代码我不截了,就是这么个事儿,稍后会用图来展示。
然后 Broker 的 PullMessageProcessor 里面的 processRequest 方法是用来处理拉消息请求的,有消息就直接返回,如果没有消息怎么办呢?我们来看一下代码。
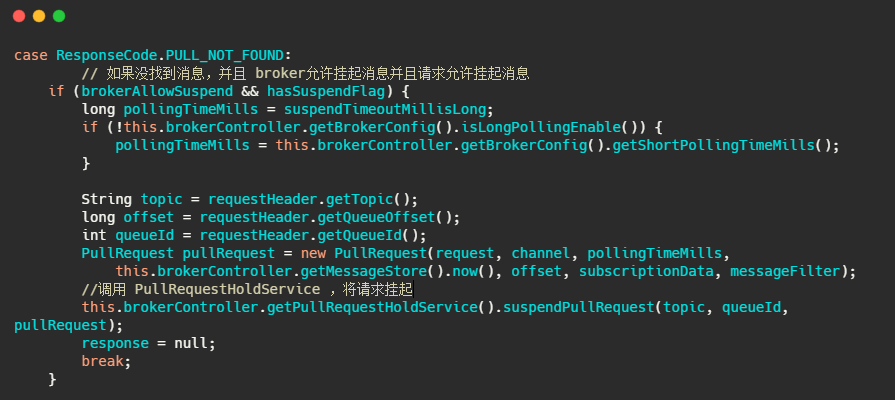
我们再来看下 suspendPullRequest 方法做了什么。
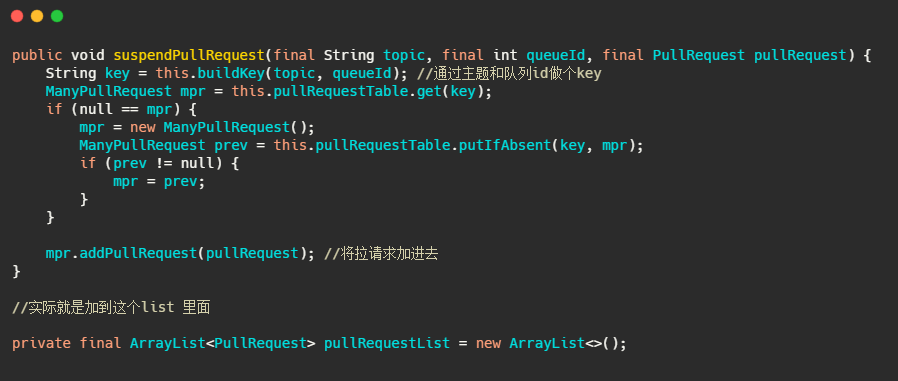
而 PullRequestHoldService 这个线程会每 5 秒从 pullRequestTable 取PullRequest请求,然后看看待拉取消息请求的偏移量是否小于当前消费队列最大偏移量,如果条件成立则说明有新消息了,则会调用 notifyMessageArriving ,最终调用 PullMessageProcessor 的 executeRequestWhenWakeup() 方法重新尝试处理这个消息的请求,也就是再来一次,整个长轮询的时间默认 30 秒。
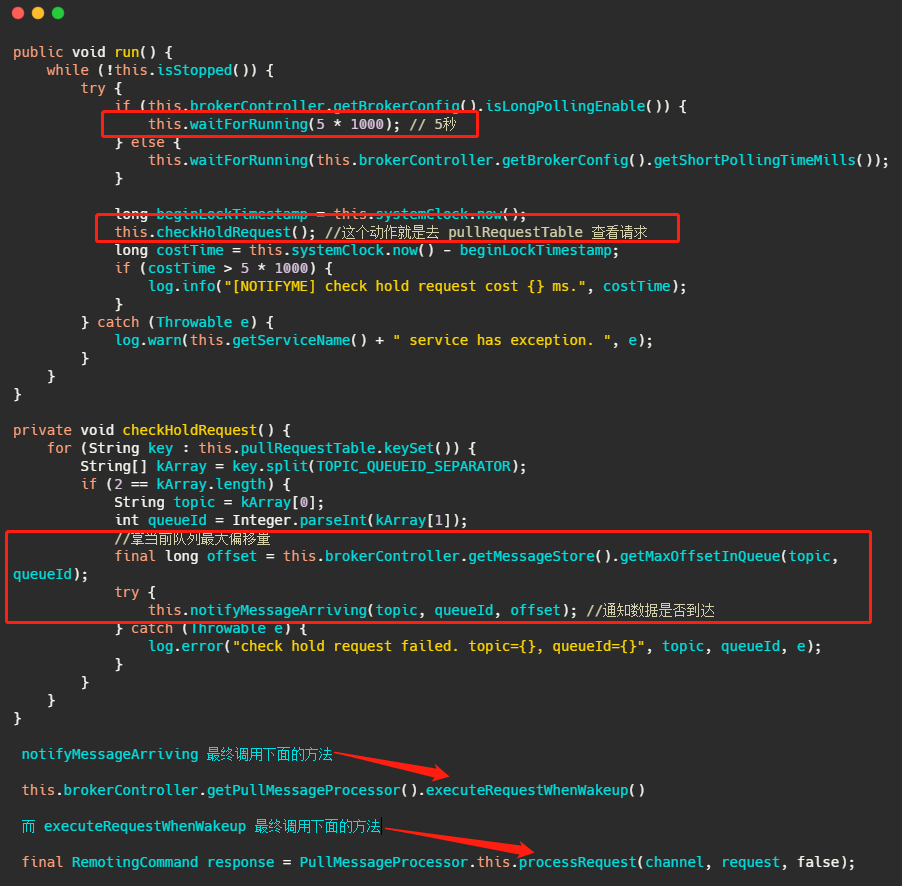
简单的说就是 5 秒会检查一次消息时候到了,如果到了则调用 processRequest 再处理一次。这好像不太实时啊?5秒?
别急,还有个 ReputMessageService 线程,这个线程用来不断地从 commitLog 中解析数据并分发请求,构建出 ConsumeQueue 和 IndexFile 两种类型的数据,并且也会有唤醒请求的操作,来弥补每 5s 一次这么慢的延迟
代码我就不截了,就是消息写入并且会调用 pullRequestHoldService#notifyMessageArriving。
最后我再来画个图,描述一下整个流程。
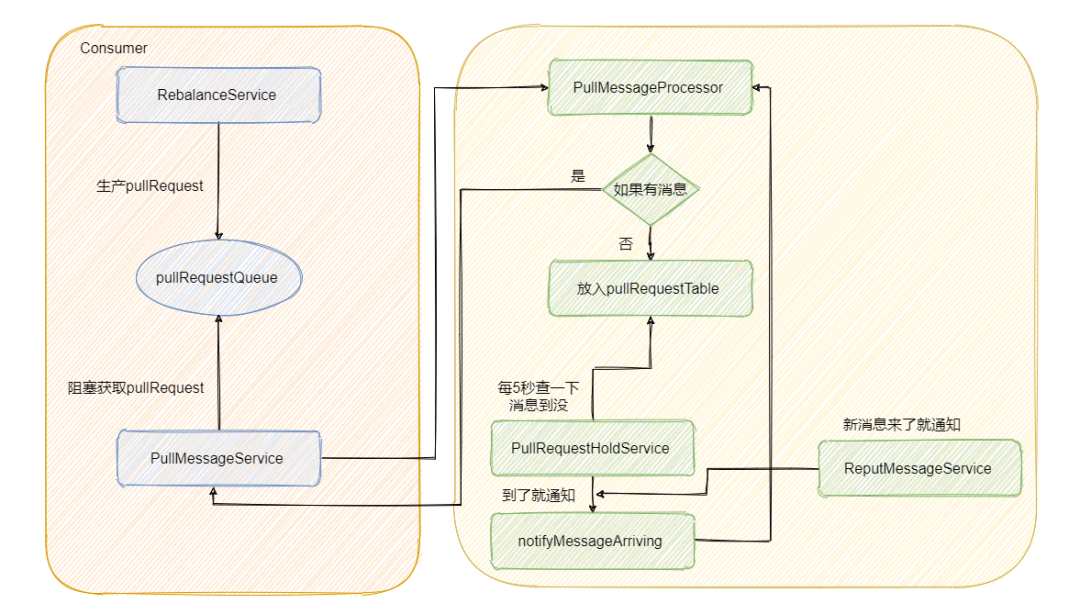
Kafka 中的长轮询
像 Kafka 在拉请求中有参数,可以使得消费者请求在 “长轮询” 中阻塞等待。
简单的说就是消费者去 Broker 拉消息,定义了一个超时时间,也就是说消费者去请求消息,如果有的话马上返回消息,如果没有的话消费者等着直到超时,然后再次发起拉消息请求。
并且 Broker 也得配合,如果消费者请求过来,有消息肯定马上返回,没有消息那就建立一个延迟操作,等条件满足了再返回。
我们来简单的看一下源码,为了突出重点,我会删减一些代码。
先来看消费者端的代码。
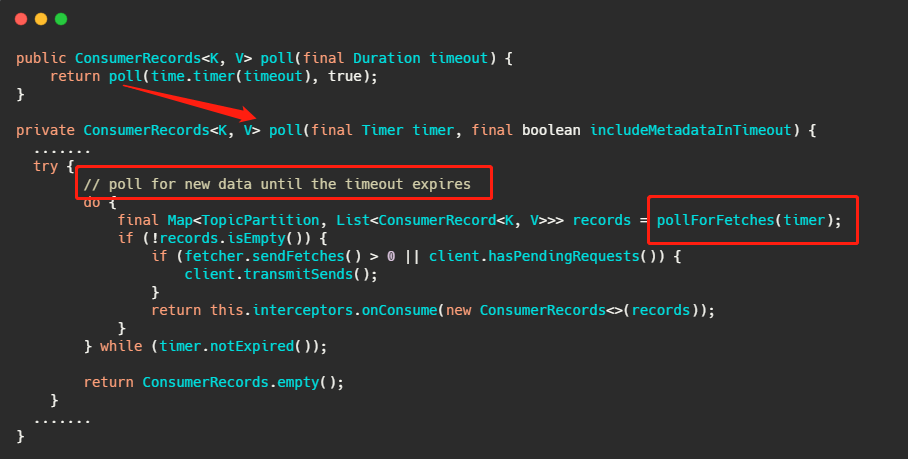
上面那个 poll 接口想必大家都很熟悉,其实从注解直接就知道了确实是等待数据的到来或者超时,我们再简单的往下看。
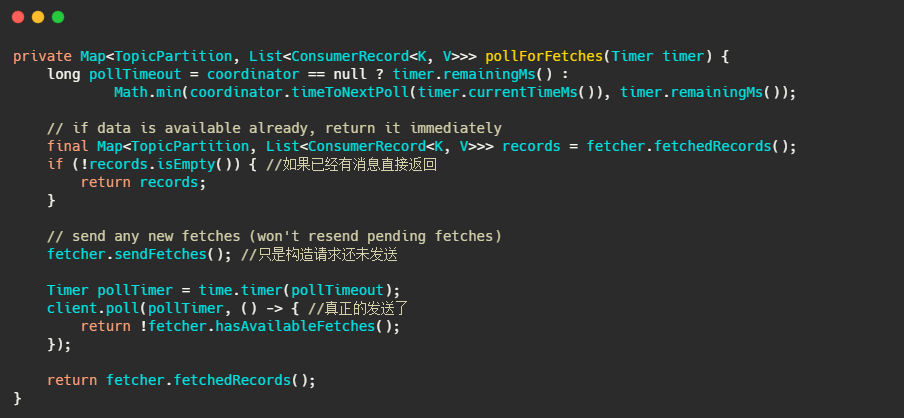
我们再来看下最终 client.poll 调用的是什么。
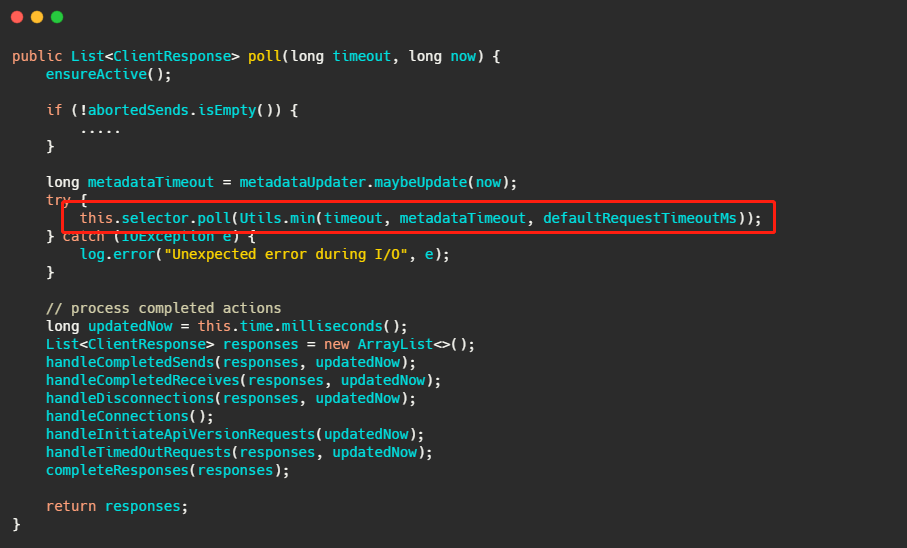
最后调用的就是 Kafka 包装过的 selector,而最终会调用 Java nio 的 select(timeout)。
现在消费者端的代码已经清晰了,我们再来看看 Broker 如何做的。
Broker 处理所有请求的入口其实我在之前的文章介绍过,就在 KafkaApis.scala 文件的 handle 方法下,这次的主角就是 handleFetchRequest 。
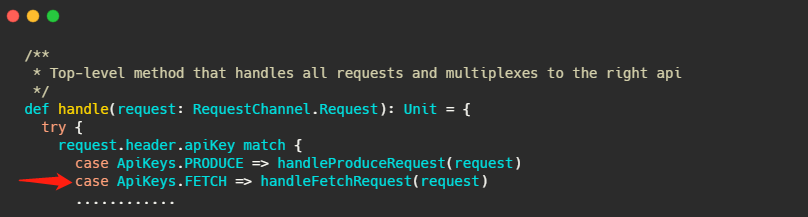
这个方法进来,我截取最重要的部分。
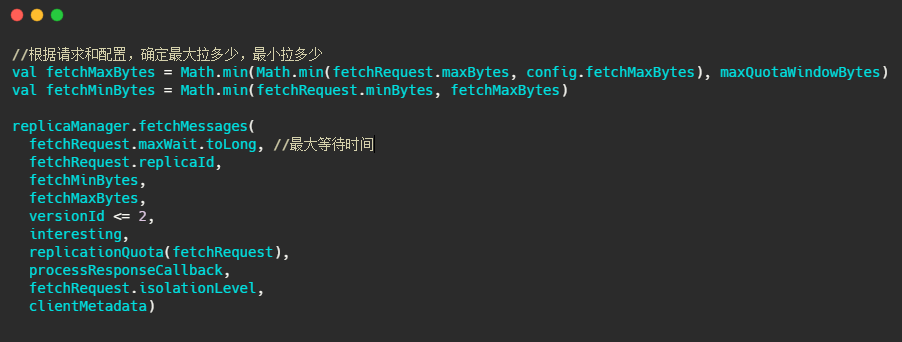
下面的图片就是 fetchMessages 方法内部实现,源码给的注释已经很清晰了,大家放大图片看下即可。
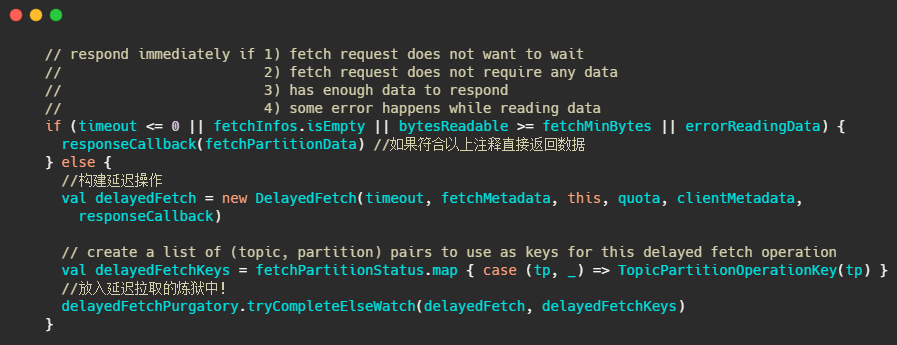
这个炼狱名字取得很有趣,简单的说就是利用我之前文章提到的时间轮,来执行定时任务,例如这里是delayedFetchPurgatory,专门用来处理延迟拉取操作。
我们先简单想一下,这个延迟操作都需要实现哪些方法,首先构建的延迟操作需要有检查机制,来查看消息是否已经到了,然后呢还得有个消息到了之后该执行的方法,还需要有执行完毕之后该干啥的方法,当然还得有个超时之后得干啥的方法。
这几个方法其实对应的就是代码里的 DelayedFetch ,这个类继承了 DelayedOperation 内部有:
isCompleted 检查条件是否满足的方法
tryComplete 条件满足之后执行的方法
onComplete 执行完毕之后调用的方法
onExpiration 过期之后需要执行的方法
判断是否过期就是由时间轮来推动判断的,但是总不能等过期的时候再去看消息到了没吧?
这里 Kafka 和 RocketMQ 的机制一样,也会在消息写入的时候提醒这些延迟请求消息来了,具体代码我不贴了, 在 ReplicaManager#appendRecords 方法内部再深入个两方法可以看到。
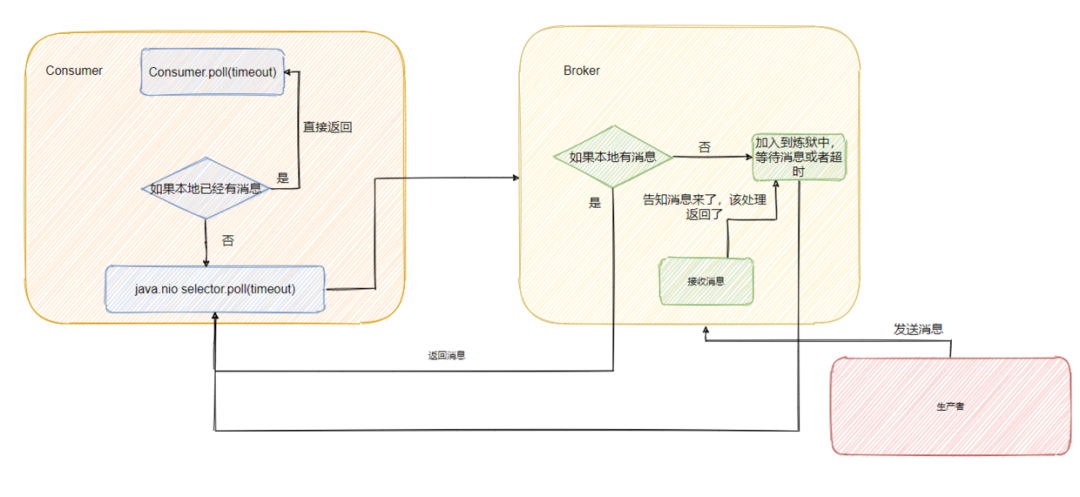
不过虽说代码不贴,图还是要画一下的。
小结一下
可以看到 RocketMQ 和 Kafka 都是采用“长轮询”的机制,具体的做法都是通过消费者等待消息,当有消息的时候 Broker 会直接返回消息,如果没有消息都会采取延迟处理的策略,并且为了保证消息的及时性,在对应队列或者分区有新消息到来的时候都会提醒消息来了,及时返回消息。
一句话说就是消费者和 Broker 相互配合,拉取消息请求不满足条件的时候 hold 住,避免了多次频繁的拉取动作,当消息一到就提醒返回。
最后
总的而言推拉模式各有优劣,而我个人觉得一般情况下拉模式更适合于消息队列。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️