
Spark 特性 | 即将发布的 Apache Spark 3.2 将内置 Pandas API
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。
几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koalas 作为 Project Zen 的一部分被正式合并到 PySpark 中,具体参见 SPIP: Support pandas API layer on PySpark,也可以参见 Data + AI Summit 2021 中的 Project Zen: Making Data Science Easier in PySpark 议题分享。
在即将发布的 Spark 3.2 版本中,pandas 用户仅需要修改一行就可以以分布式的方式使用现有工作负载:
from pandas import read_csvfrom pyspark.pandas import read_csvpdf = read_csv("data.csv")修改为from pyspark.pandas import read_csvpdf = read_csv("data.csv")
本文总结了 Spark 3.2 上的 Pandas API 支持,并重点介绍了值得注意的特性、变化和路线图。
更好的扩展性
众所周知,pandas 的一个限制是只能单机处理,它不能随数据量线性伸缩。例如,如果 pandas 试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败:
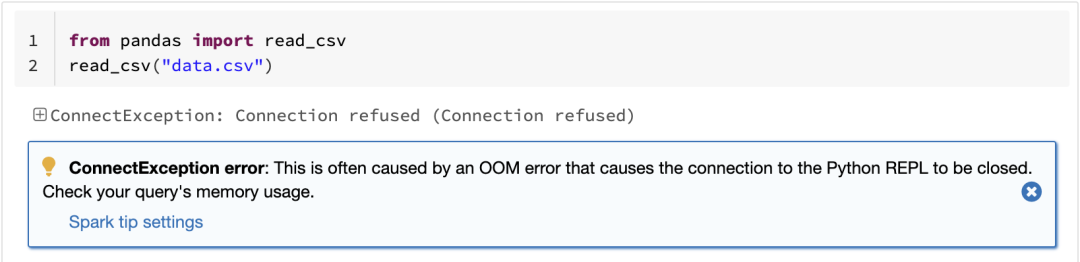
Spark 上的 pandas API 克服了这个限制,使用户能够通过利用 Spark 来处理大型数据集:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Spark 上的 pandas API 也可以很好地扩展到大型节点集群。下图显示了使用部分规模的集群分析 15TB 大小的 Parquet 数据集时的性能。集群中的每台机器都有 8 个 vCPU 和 61 GiBs 内存。
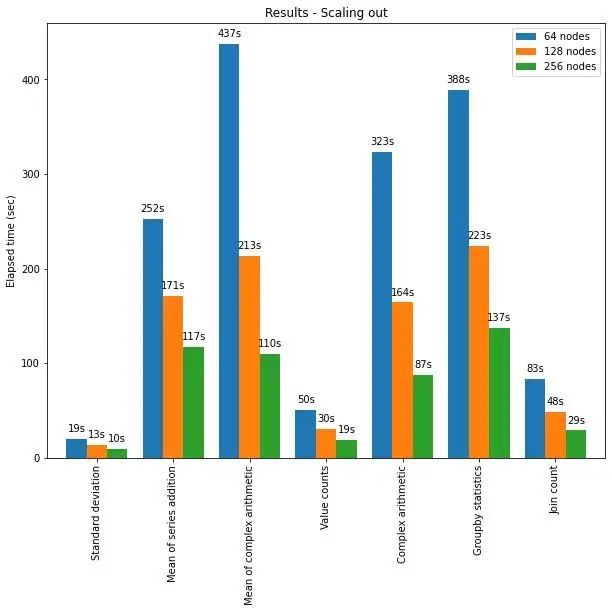
在此测试中,Pandas API 在 Spark 上的分布式执行几乎呈线性扩展。当集群中的机器数量增加一倍时,运行时间减少一半。与单台机器相比,加速也很显着。例如,在标准偏差基准(Standard deviation benchmark)测试中,由 256 台机器组成的集群可以在大致相同的时间内处理比单台机器多 250 倍的数据(每台机器有 8 个 vCPU 和 61 GiB 内存):
| Single machine | Cluster of 256 machines | |
| Parquet Dataset | 60GB | 60GB x 250 (15TB) |
| Elapsed time (sec) of Standard deviation | 12s | 10s |
优化单机性能
由于 Spark 引擎中的优化,Spark 上的 pandas API 甚至在单台机器上的性能都优于 pandas。下图展示了在一台机器(具有 96 个 vCPU 和 384 GiBs 内存)上运行 Spark 和单独调用 pandas 分析 130GB 的 CSV 数据集的性能对比。
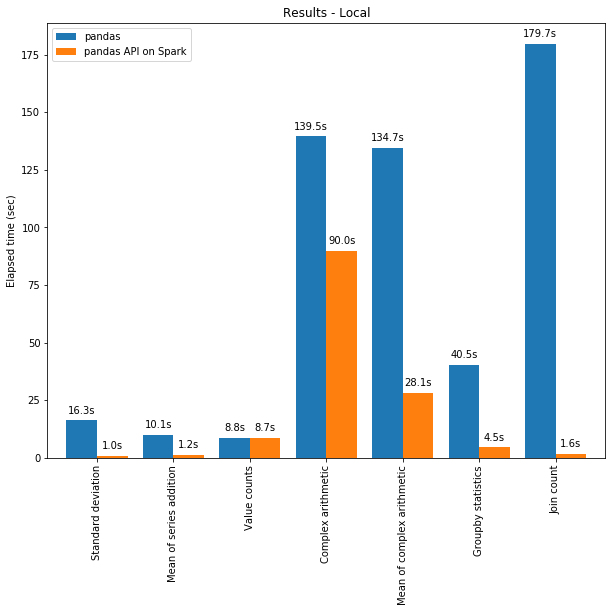
多线程和 Spark SQL Catalyst Optimizer 都有助于优化性能。例如,Join count 操作在整个阶段代码生成时快 4 倍:没有代码生成时为 5.9 秒,代码生成时为 1.6 秒。
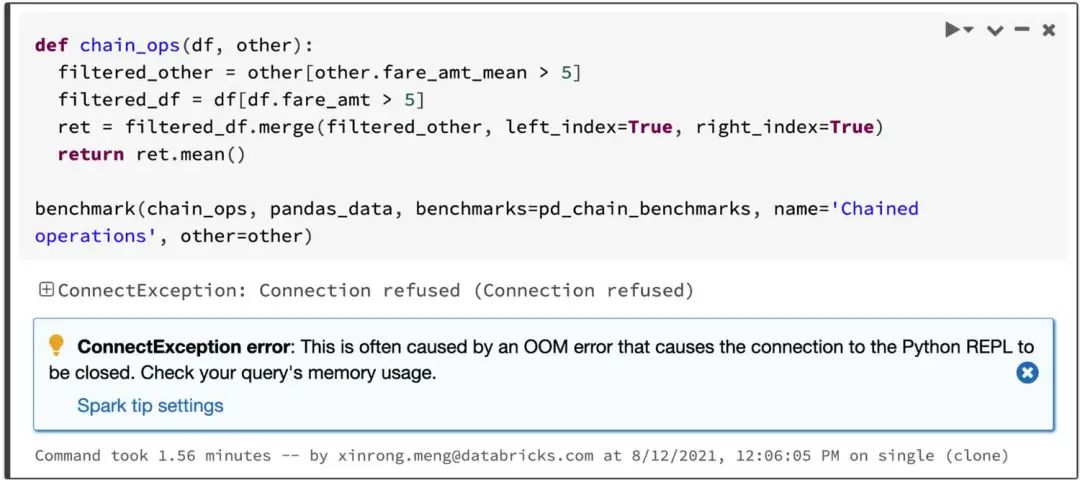
Spark 在链式操作(chaining operations)中具有特别显着的优势。Catalyst 查询优化器可以识别过滤器以明智地过滤数据并可以应用基于磁盘的连接(disk-based joins),而 Pandas 倾向于每一步将所有数据加载到内存中。
考虑两个过滤数据进行 JOIN,然后计算数据集的平均值的查询,Spark 上的 Pandas API 在 4.5 秒内成功,而 Pandas 由于 OOM(内存不足)错误而失败,如下所示:
以可视化的方式交互式操作数据
pandas 默认使用 matplotlib,它提供静态绘图图表。例如,下面的代码生成一个静态图表:
# Areapandas.DataFrame(np.random.rand(100, 4), columns=list("abcd")).plot.area()

相反,Spark 上的 Pandas API 默认使用 plotly,它提供交互式图表。例如,它允许用户交互地放大和缩小。根据图的类型,Spark 上的 pandas API 在生成交互式图表时会自动确定在内部执行计算的最佳方式:
# Areapandas.DataFrame(np.random.rand(100, 4), columns=list("abcd")).plot.area()
利用 Spark 中的统一分析功能
pandas 是为 Python 数据科学的批处理而设计的,而 Spark 是为统一分析而设计的,包括 SQL、流处理和机器学习。为了填补它们之间的空白,Spark 上的 Pandas API 为高级用户提供了许多不同的方式来利用 Spark 引擎,例如:
用户可以使用 Spark 优化后的 SQL 引擎直接通过 SQL 查询数据,如下图:
>>> import pandas as pd>>> import pyspark.pandas as ps>>> pdf = pd.DataFrame({"a": [1, 3, 5]}) # pandas DataFrame>>> sdf = spark.createDataFrame(pdf) # PySpark DataFrame>>> psdf = sdf.to_pandas_on_spark() # pandas-on-Spark DataFrame>>> # Query via SQL... ps.sql("SELECT count(*) as num FROM {psdf}")
它还支持字符串插值语法(string interpolation syntax)以自然地与 Python 对象交互:
>>> pred = range(4)>>> # String interpolation with Python instances... ps.sql("SELECT * from {psdf} WHERE a IN {pred}")
Spark 上的 pandas API 也支持流处理:
>>> def func(sdf, _):... # pandas-on-Spark DataFrame... psdf = sdf.to_pandas_on_spark()... psdf.describe()...>>> spark.readStream.format(... "kafka").load().writeStream.foreachBatch(func).start()
用户可以轻松调用 Spark 中可扩展的机器学习库:
>>> from pyspark.ml.feature import StringIndexer>>> sdf = psdf.to_spark() # PySpark DataFrame>>> indexer = StringIndexer(... inputCol="category", outputCol="categoryIndex")>>> indexed = indexer.fit(sdf).transform(sdf)>>> indexed.show()
下一步
对于下一个 Spark 版本,重点关注以下几个方向:
更多类型提示
Spark 上的 Pandas API 中的代码目前是部分类型化的,它仍然支持静态分析和自动完成。将来,所有代码都将是完全类型化的。
性能提升
Spark 上的 Pandas API 有几个地方,我们可以通过与引擎和 SQL 优化器更密切的交互来进一步提高性能。
稳定性
有几个地方需要修复,特别是与缺失值相关的地方,例如 NaN 和 NA 具有行为差异的极端情况。
此外,在这些情况下,Spark 上的 Pandas API 将遵循并将其行为与最新版本的 Pandas 匹配。
更多 API 覆盖
Spark 上的 Pandas API 达到了 Pandas API 的 83% 覆盖率,并且这个数字还在继续增加,现在目标高达 90%。