
这样教都不会?还得我亲自出马!

文 | 極光
来源:Python 技术「ID: pythonall」

上次说到了还有别的方法能找到搜索框吗?答案是当然有了。而且为了满足大部分场景,有很多方法可以定位元素。今天就来继续跟大家一起学习下 Python 如何使用 Selenium 进行自动化操控浏览器。
定位元素
如果想操作一个网页上面的一个元素,无论点击、输入、拖拽等等任何操作,第一步就是定义元素。因为每个元素对象又包含很多个属性,所以我们就能通过这些属性一项或几项轻松的找到它。
以下是几种常用的定位元素的方法:
find_element_by_id():通过元素的 id属性来定位,这是最常见的定位方式,一般网页包含的所有元素中,id属性是唯一的,定位速度快而且准确,首选推荐。
find_element_by_name():通过元素的
name属性来定位,这是次要推荐方式,有些元素没有id,但基本都有name,但可能存在重名。find_element_by_class_name():通过元素的
class属性来定位,一般HTML中元素都会有class用来做样式描述。
find_element_by_link_text():这个是通过 <a>对应的链接文本对象来定位的,仅用于文本有超链接的时候。
find_element_by_partial_link_text():同 find_element_by_link_text() 相似,但可以只是超链接文本的一部分。
find_element_by_tag_name():可以通过元素的
tag name来定位,但这个很容易会重复,同时返回多个元素。find_element_by_css_selector():这个是通过
css来定位的。CSS 是一种样式表语言,用来渲染元素样式的,是网页元素的重要组成部分。find_element_by_xpath():这是一种可以通过
HTML结构进行定位,可以通过根节点开始一层层定位,找到最终的元素。但这种方式在文档结构产生变化的时候可能会失效,所以不太推荐。
这么多的定位方法,基本上就能满足大部分场景的需求了。还有一些其他的方法这里就不再说了。
下面我把这些定位的例子列出来,大家就能知道该如何使用:
// 导入 webdriver
from selenium import webdriver
// executable_path 用于指定driver存放路径
browser = webdriver.Chrome(executable_path='/Users/xx/python/chromedriver')
// 打开百度页面
browser.get('https://wwww.baidu.com/')
// 在搜索框内输入 `python selenium` 并点搜索返回结果
browser.find_element_by_id("kw").send_keys("python selenium")
// name 属性定位
browser.find_element_by_name("wd").send_keys("python selenium")
// class name 属性定位
browser.find_element_by_class_name("s_ipt").send_keys("python selenium")
// 链接 text 属性定位
browser.find_element_by_link_text("关于百度").click()
// tag name 属性定位
browser.find_element_by_tag_name("input").send_keys("python selenium")
// CSS 方式定位
browser.find_element_by_css_selector("#kw").send_keys("python selenium")
// xpath 方式定位
browser.find_element_by_xpath("//input[@id='kw']").send_keys("python selenium")
// 点击 百度一下 按钮
browser.find_element_by_id("su").click()
元素是定位到了,接下来就是看要如何操作元素对象了
操作元素
上面我们说了元素是怎么定位找到的,那定位找到元素以后,我们又能对它进行什么操作呢,下面我就来一个个说下:
send_keys():这是最常用的,就是对元素模拟按键操作,输入你参数中传入的字符串,主要用来操作文本输入框时使用。
click():这个方法也是比较常用的,就是对元素对象进行鼠标单击操作,主要用来操作按钮或超链接文本时使用。
submit():如果是操作表单,则可以调用这个方法进行表单内容提交。
clear():如果对象有可以清除的内容,比如文本输入框,则清除已输入的内容。
text():这个方法主要用来获取元素的文本内容。
操作实例
好了,上面介绍那么多,现在我们来看一个实际的例子:
让浏览器自动输入 https://www.jd.com/,打开京东官网,然后搜索 ps5国行,并把搜索出来商品的名称和金额打印出来。
例子不复杂,我们直接来看代码:
# 导入库
from selenium import webdriver
import time
# executable_path 用于指定driver存放路径
browser = webdriver.Chrome(executable_path='/Users/xx/python/chromedriver')
# 打开京东官网
browser.get('https://www.jd.com/')
# browser.find_element_by_id("kw").send_keys("python selenium")
# 获取输入框对象
search = browser.find_element_by_xpath('//*[@id="key"]')
# 输入想要搜索的关键词,如"ps5国行"
search.send_keys('ps5国行')
# 获取搜索按钮对象并单击
browser.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()
# 将滚动条移动到页面底部,用于加载所有信息
javascript = "var q=document.documentElement.scrollTop=50000"
# 执行 javascript 移动滚动条
browser.execute_script(javascript)
# 等待3秒,有些异步加载的数据加载慢
time.sleep(3)
# 通过查看页面源码得到金额的 xpath 路径,并获取金额
prices = browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[2]/strong/i')
# 通过查看页面源码得到商品标题的 xpath 路径,并获取商品标题
names = browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[3]/a/em')
# 遍历打印出当前页所有标题和金额
for name,price in zip(names,prices):
print(name.text.replace('\n',''),price.text)
#退出浏览器
browser.quit()
代码中我已经对每一行做了注释,让大家能看明白每一行都是做什么的。接下来我们直接运行代码 python test.py,可以看到浏览器自动启动后,执行相关操作,然后退出,下面是执行中的截图:
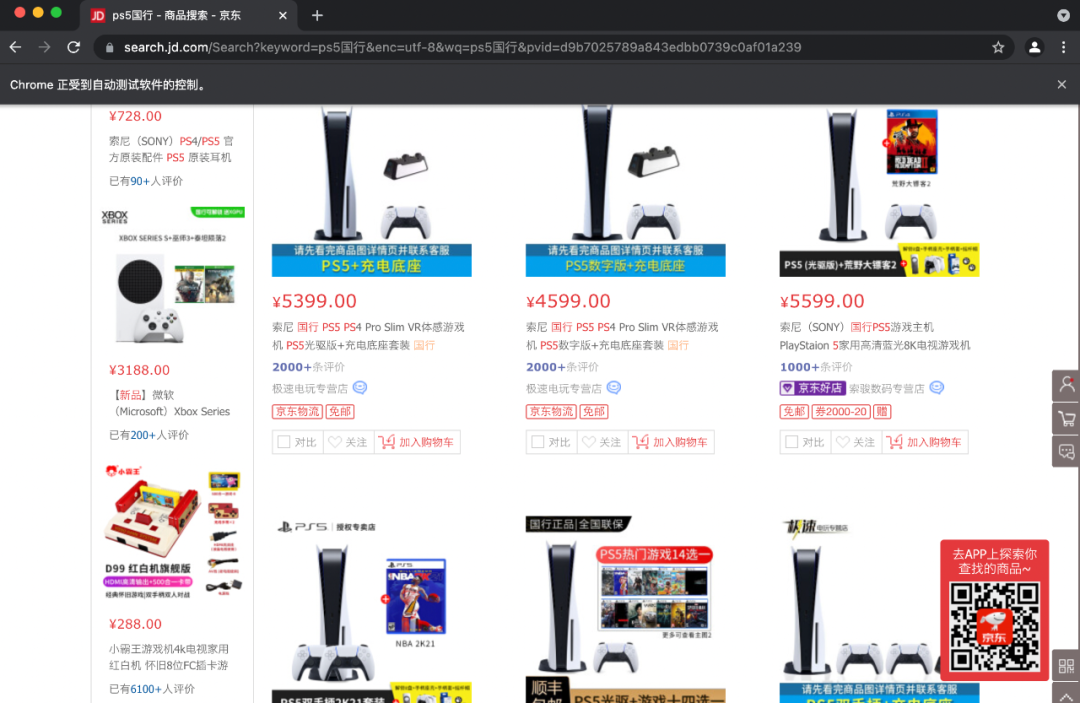
执行完成后,我们可以看到控制台已经打印出来相应信息:

总结
好了,今天我们又介绍了下 selenium 定位元素的多种方法,以及我们找到元素后,可以对它进行什么操作。并写了一个自动化操作的简单例子,给大家学习参考,后续还会为大家介绍更多。OK,今天就聊这些,如果你喜欢记得点 在看。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】