
面向多场景而设计的 Erda Pipeline
Erda Pipeline 是端点自研、用 Go 编写的一款企业级流水线服务。截至目前,已经为众多行业头部客户提供交付和稳定的服务。
为什么我们坚持自研,而不用 jenkins 等产品呢?在当时,至少有以下几点理由:
时至今日,开源社区仍没有一个事实上的流水线标准 K8s、DC/OS 等的 Job 实现都偏弱,上下文传递等缺失,不满足我们的需求,更不要说 Flow 了 自研能更快地响应业务需求,进行定制化开发
作为基础服务,Pipeline 在 Erda 内部支撑了 CI/CD、快数据平台、自动化测试平台、SRE 运维链路等产品化场景。本文就从几个方面来介绍一下 Pipeline。
01
为什么会有 Pipeline
这就需要从应用构建开始说起。Pipeline 的前身是 Packer 和 CI。

Packer
Erda 最开始是端点内部使用的 PaaS 平台。从 2017 年开始,Erda 就管理了公司所有的研发项目。项目下每个应用都逃不开 代码 -> 编译 -> 镜像制作 -> 部署 的标准流程。这个时候我们开发了 Packer,顾名思义,它是一个专门负责 打包 的组件。用户需要提供 Dockerfile,这在当时还是有着较高学习成本的。
CI
随着 CI/CD(持续集成、持续交付)概念的深入人心,我们也推出了 Packer 的升级版 CI 。同时,基础设施即代码(IaC)的理念也在这里得到了实践:通过 erda.yaml 1.0 语法同时声明应用的微服务架构和构建过程。
在用户体验上,我们不再直接暴露 Dockerfile,而是把最佳实践以 BuildPack 大礼包的方式给到使用者,使用者甚至不需要声明应用的开发语言和构建方式,就可以通过 BuildPack 的自动探测和识别,完成 CI/CD 流程。
受限于单容器的运行方式,当时我们也遇到了一些问题,譬如把 CI 构建过程自定义能力开放、构建环境多版本问题等,这些问题在 Pipeline 里都迎刃而解。
Pipeline
今天回过头来看,从 CI 升级到 Pipeline 是一个很自然的过程:因为 CI/CD 本身就是一个很标准的流程,我们完全可以抽象出一个更通用的流程引擎,这就是 Pipeline。CI/CD 成为了 Pipeline 最开始支撑的场景。
在设计之初,我们就做了以下改进:
对外:通过清晰易用的 pipeline.yaml 语法,降低使用者的上手成本。 对内:抽象出任务定义,配合 ActionExecutor Plugin Mechenism(任务执行器插件机制),很方便地对接各个单任务执行平台,譬如 DC/OS Metronome、K8s Job、Flink/Spark Job 等。 由 Pipeline 提供一致、强大的流程编排能力。
02
Pipeline 功能特性
Pipeline 有许多灵活、强大的功能,譬如:
配置即代码,通过 pipeline.yaml 语法描述流程,基于 Stage 语法简化编排复杂度。 丰富的扩展市场,平台内置超过百款开箱即用的 Action,满足大部分日常场景;同时可轻松扩展你自己的 Action。 可视化编辑,通过图形界面交互快速配置流水线。 支持嵌套流水线,在流水线级别进行复用,组合出更强大的流水线。 灵活的执行策略,包括串并行、循环、分支策略、超时、人工确认等。 支持工作流优先队列,优先级可实时调整,保证高优先级流水线优先执行。 多维度的重试机制,支持断点重试、全流程重试。 定时流水线,同时提供强大的定时补偿功能。 动态配置,支持 值和文件两种类型,均支持加密存储,确保数据安全性。上下文传递,后置任务可以引用前置任务的 值和文件。开放的 OpenAPI 接口,方便第三方系统快速接入。 ······
03
Pipeline 架构
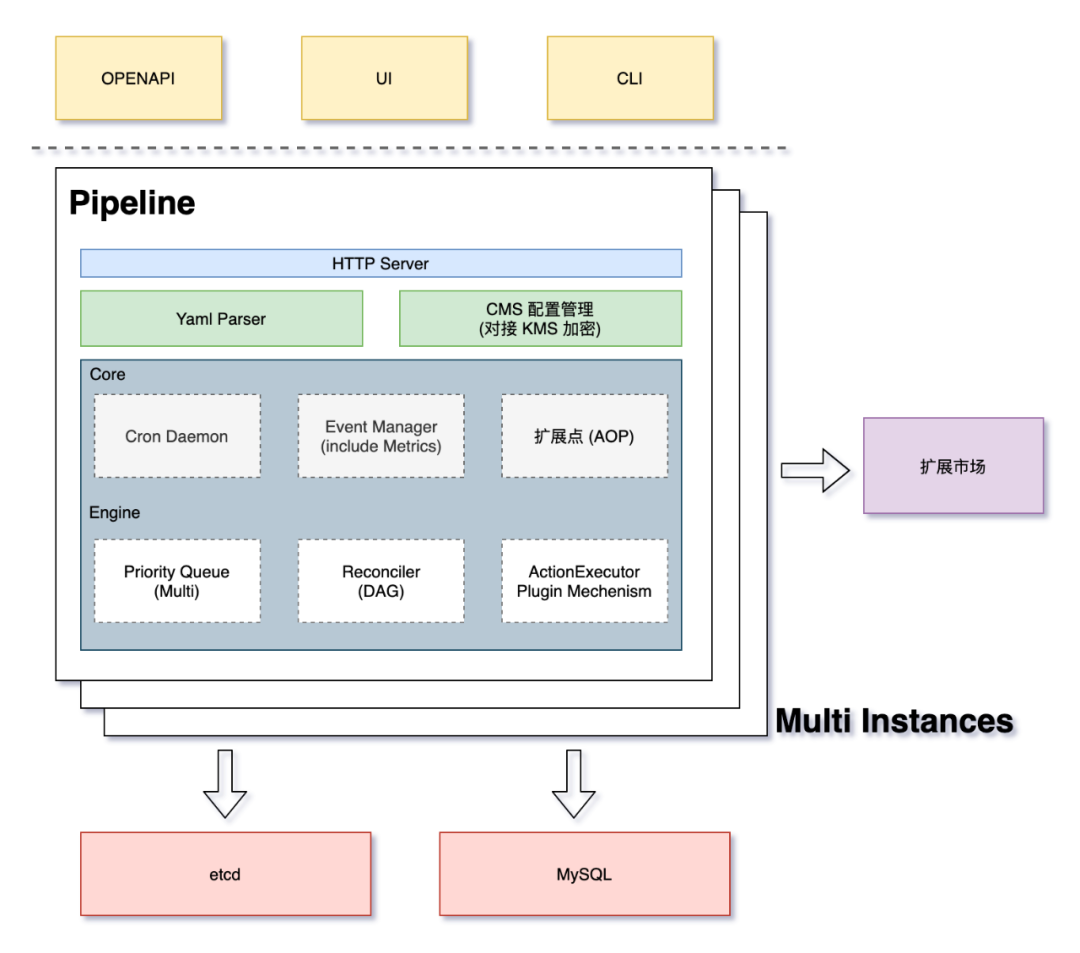
如上图所示,Pipeline 支持 UI / OPENAPI / CLI 多种方式进行交互。
Pipeline 本身支持水平扩展,保证高可用,还可以将其划分为:服务层、核心层和引擎层。下面我们详细介绍一下。
服务层
yaml parser 解析流程定义文件,支持灵活的变量语法。例如上下文值引用: ${{ outputs.preTaskName.key }};配置管理引用:${{ configs.key }}等。对接扩展市场获取扩展能力。
核心层
Cron 守护进程。 EventManager 抽象内部事件发送,使用适配器模式解耦监控指标上报、发送 ws 消息、支持 webhook 等。 AOP 扩展点机制(借鉴 Spring),把代码关键节点进行暴露,方便开发同学在不修改核心代码的前提下定制流水线行为。这个能力后续我们还会开放给调用方,包括用户,支持他们去做一些有意思的事情。
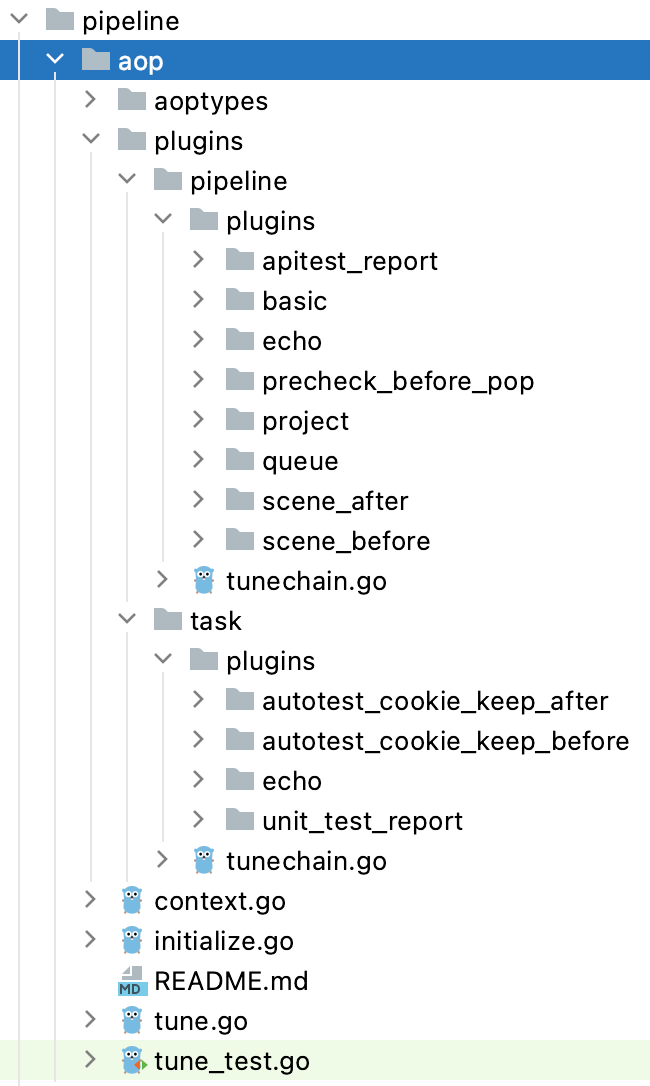
目前许多有意思的功能都是通过扩展点机制实现的,譬如自动化测试报告嵌套生成、队列弹出前检查、接口测试 Cookie 保持等:
引擎层
引擎层包括:
流程推进器(Reconciler) 优先队列管理器 任务执行器插件机制
具体内容在下一节会展开讲解。
中间件依赖
我们尽可能做到简化中间件依赖,使部署更简单。
使用 MySQL 做数据持久化。 使用 etcd watch 功能实现多实例状态同步以及分布式锁。 使用 etcd key ttl 实现数据 defer GC。
04
流水线是如何被推进的
在引擎侧,pipeline.yaml 被解析为 DAG(Directed Acyclic Graph,有向无环图) 结构后被推进。
换句话说,引擎并不认识、也不关心 pipeline.yaml 语法,用户侧完全可以提供多种多样的语法方便不同用户使用,只需要最终能被转换成 Pipeline 简单封装过的 DAG (https://github.com/erda-project/erda/blob/master/pkg/dag/dag.go#L27)结构。
Pipeline 级别由推进器 Reconciler (https://github.com/erda-project/erda/blob/master/modules/pipeline/pipengine/reconciler/define.go#L44)根据 DAG 计算出当前可被推进的任务,每个任务异步去执行推进逻辑。
任务的推进由 TaskFramework (https://github.com/erda-project/erda/blob/master/modules/pipeline/pipengine/reconciler/taskrun/framework.go#L37) 处理,其中抽象出 prepare -> create -> start -> queue -> wait 标准步骤。当有需要时也可以很方便地进行标准扩展。
当任意一个任务推进完毕时,会再次递归调用 reconcile 方法去重复上述流程,直到流程整体执行完毕。
Reconciler 中 通过 DAG 计算可调度任务代码如下(https://github.com/erda-project/erda/blob/master/modules/pipeline/pipengine/reconciler/scheduable.go#L27):
// getSchedulableTasks return the list of schedulable tasks.
// tasks in list can be schedule concurrently.
func (r *Reconciler) getSchedulableTasks(p *spec.Pipeline, tasks []*spec.PipelineTask) ([]*spec.PipelineTask, error) {
// construct DAG
dagNodes := make([]dag.NamedNode, 0, len(tasks))
for _, task := range tasks {
dagNodes = append(dagNodes, task)
}
_dag, err := dag.New(dagNodes,
// pipeline DAG 中目前可以禁用任意节点,即 dag.WithAllowMarkArbitraryNodesAsDone=true
dag.WithAllowMarkArbitraryNodesAsDone(true),
)
if err != nil {
return nil, err
}
// calculate schedulable nodes according to dag and current done tasks
schedulableNodeFromDAG, err := _dag.GetSchedulable((&spec.PipelineWithTasks{Tasks: tasks}).DoneTasks()...)
if err != nil {
return nil, err
}
......
}
05
ActionExecutor 插件机制
把复杂留给自己,把简单留给别人。
在前文我们说到:由流水线提供灵活、一致的流程编排能力。它的前提是单个任务的执行已经被很好的抽象了。
在 Pipeline 中,我们对一个任务执行的抽象是 ActionExecutor:
type ActionExecutor interface {
Kind() Kind
Name() Name
Create(ctx context.Context, action *spec.PipelineTask) (interface{}, error)
Start(ctx context.Context, action *spec.PipelineTask) (interface{}, error)
Update(ctx context.Context, action *spec.PipelineTask) (interface{}, error)
Exist(ctx context.Context, action *spec.PipelineTask) (created bool, started bool, err error)
Status(ctx context.Context, action *spec.PipelineTask) (apistructs.PipelineStatusDesc, error)
// Optional
Inspect(ctx context.Context, action *spec.PipelineTask) (apistructs.TaskInspect, error)
Cancel(ctx context.Context, action *spec.PipelineTask) (interface{}, error)
Remove(ctx context.Context, action *spec.PipelineTask) (interface{}, error)
}
因此,一个执行器只要实现 单个任务 的 创建、启动、更新、状态查询、删除 等基础方法,就可以注册成为一个 ActionExecutor。
恰当的任务执行器抽象,使得 Batch/Streaming/InMemory Job 的配置和使用方式完全一致,批流一体,对使用者屏蔽底层细节,做到无感知切换。在同一条流水线中,可以混用各种 ActionExecutor。
调度时,Pipeline 根据任务类型和集群信息,将任务调度到对应的任务执行器上。
目前我们已经拥有许多的 ActionExecutor:
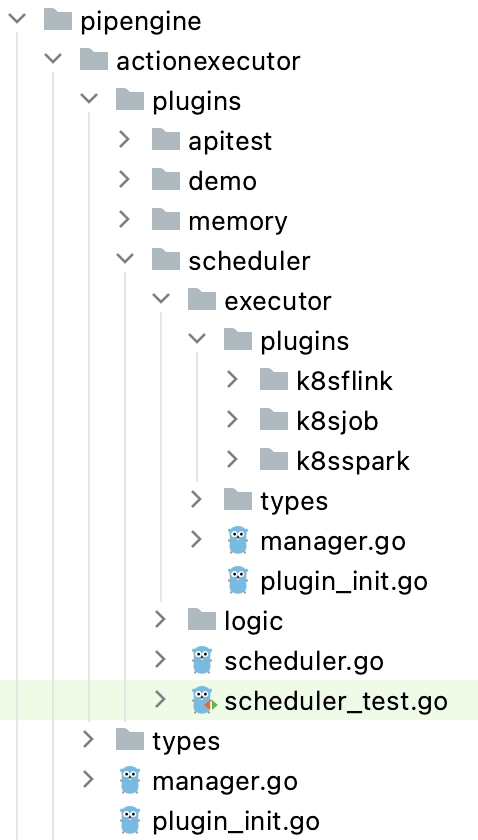
插件化的开发机制,使我们在未来对接其他任务引擎也变得非常简单,例如对接 Jenkins 成为一个 ActionExecutor。
这里举一个真实的例子:在自动化测试平台里,之前每一个 API 都会启动一个容器去执行,而容器的启停最快也需要数秒,这和 API 接口正常毫秒级的耗时比起来,慢了几个数量级。得益于 ActionExecutor 插件机制,我们快速开发了基于内存的 API-Test 任务执行器,很快就解决了这个问题,使用者不需要做任何调整,节省了很多时间成本。
06
更友好的用户接入层 pipeline.yaml
pipeline.yaml (https://docs.erda.cloud/1.1/manual/deploy/pipeline.html#%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99-pipeline-yml-%E6%96%87%E4%BB%B6) 是 IaC 的一个实践,我们通过 YAML 格式描述流水线定义,基于 Stage 语法简化编排复杂度。
一个简单的示例如下所示:
version: 1.1
cron: 0 */10 * * * ?
# stage 表示 阶段,多个 stage 串行成为 stages
stages:
# 一个 stage 内包含多个 并行 的 Action
- stage:
- git-checkout: # Action 类型
params:
depth: 1
- stage:
- buildpack:
alias: backend
params:
context: ${{ dirs.git-checkout }}
resources:
cpu: 0.5
mem: 2048
- custom-script:
image: centos:7
commands: # 支持直接执行命令
- sleep 5
- echo hello world
- cat ${{ dirs.git-checkout }}/erda.yml # 这里通过 ${{ dirs.git-checkout }} 语法来引用文件
07
以 Pipeline 为技术底座
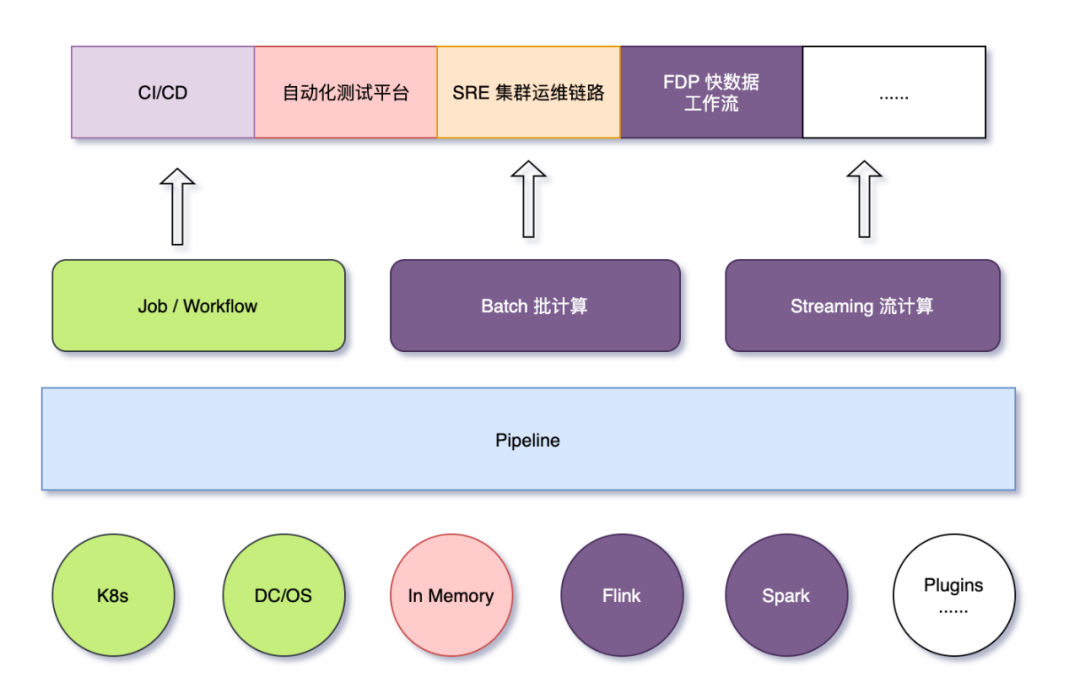
目前,以 Pipeline 作为技术底座,向上支撑了:
DevOps CI/CD 场景,包括 Erda 自身的持续集成和 Release 版本发布。 快数据平台:工作流编排,批流一体,支持工作流优先级队列,保证高优先级数据任务必须执行。至今已为多家世界 500 强企业和头部客户提供稳定服务。 自动化测试平台:测试流程编排,API(出参、断言)、数据银行等不同类型的任务统一编排。 SRE 集群运维链路。 提供无限扩展:基于 ActionExecutor 扩展机制和扩展市场。
08
开源架构升级
目前,Pipeline 所有代码均已完成开源。我们正在进行的重构工作包括:
使用 Erda-Infra 微服务架构重新梳理功能模块 Pipeline 平台支持独立部署,UI 自动适配 通过 ActionExecutor 插件机制支持使用者本地 Agent,充分利用本地资源 在 GitHub 上推出 Erda Cloud Pipeline App,提供免费的 CI 能力
09
结束语
最后,我们欢迎有更多的同学来使用流水线,不论是代码级的使用,还是通过 Erda Cloud (https://www.erda.cloud)来体验我们的服务。
欢迎 GitHub 提交 Issue 和 PR !
Erda Github 地址:https://github.com/erda-project/erda
Erda Cloud 官网:https://www.erda.cloud/