
【性能】性能分析原则
性能分析
不合标准的应用程序性能会产生软件或网络问题。为确保软件满足或超过设计的期望值,有必要分析应用程序的性能以发现潜在的问题。这个过程被称为“性能分析”。它包括检查应用程序以确保每个组件有效地工作,并根据设计密切注视处理器的使用、网络和系统服务、存储和输入/输出(I/O)。
响应时间的2/5/8原则
Bug分布的2/8原则
80%的bug分布在20%的模块里
业务分布的2/8原则
80%的业务量在20%的时间里完成
二八原则计算的结果并非在线并发用户数,是系统要达到的处理能力(吞吐量),初学者容易被误导,那这这个数据就去设置并发数,这是错误滴。
如果你的系统性能要求更高,也可以选择一九原则或更严格的算法,二八原则比较通用,一般系统性能比较接近这个算法而已,大家应该活用。
理发店模型
模型假设
场景构建
场景1
理发店内只有1位顾客
有1名理发师为他提供服务,另外2位等着或打杂帮忙。1小时后,两位顾客剪完头发出门 在这1个小时里,整个理发店只服务了1位顾客,这位顾客花费在这次剪发的时间是1小时。
理发店内同时有2位顾客
同时有2名理发师在为顾客服务,另外1位等着或打杂帮忙。1小时后,两位顾客剪完头发出门 在这1小时里,整个理发店服务了两位顾客,这两位顾客花费在剪发的时间均为1小时
理发店内同时有3位顾客
同时有3名理发师在为顾客服务。1小时后,三位顾客剪完头发出门
在这1小时里,整个理发店服务了三位顾客,这三位顾客花费在剪发的时间均为1小时
场景总结:
在理发店同时服务的顾客数量从1位增加到3位的过程中,随着顾客数量的增多,理发店的整体工作效率在提高,而且每位顾客在理发店内所呆的时间并未延长。
当然,可以假设当只有1位顾客和2位顾客时,空闲的理发师可以帮忙打杂,使得其他理发师的工作效率提高,并使每位顾客的剪发时间小于1小时
不过即使根据这个假设,虽然随着顾客数量的增多,每位顾客的服务时间有所延长,但是这个时间始终还被控制在顾客可接受的范围之内,并且顾客是不需要等待的。
场景2
随着理发店的生意越来越好,顾客也越来越多,出现新的场景
假设有一次顾客A、B、C刚进理发店准备剪发,外面一推门又进来了顾客D、E、F
因为A、B、C三位顾客先到,所以D、E、F三位只好坐在长板凳上等着
1小时后,A、B、C三位剪完头发走了,他们每个人这次剪发所花费的时间均为1小时。可是D、E、F三位就没有这么好运,因为他们要先等A、B、C三位剪完才能剪,所以他们每个人这次剪发所花费的时间均为2小时——包括等待1小时和剪发1小时。
通过上面这个场景我们可以发现,对于理发店来说,都是每小时服务三位顾客——第1个小时是A、B、C,第二个小时是D、E、F;但是对于顾客D、E、F来说,“响应时间”延长了。
场景3
假设这次理发店里一次来了9位顾客,这9位顾客中有3位的“响应时间”为1小时,有3位的“响应时间”为2小时(等待1小时+剪发1小时),还有3位的“响应时间”为3小时(等待2小时+剪发1小时)——已经到达用户所能忍受的极限。假如在把这个场景中的顾客数量改为10,那么我们已经可以断定,一定会有1位顾客因为“响应时间”过长而无法忍受,最终离开理发店走了。(其实这种场景在我们生活中也是非常常见的一种情况)
上面的场景如何与性能测试挂钩呢?
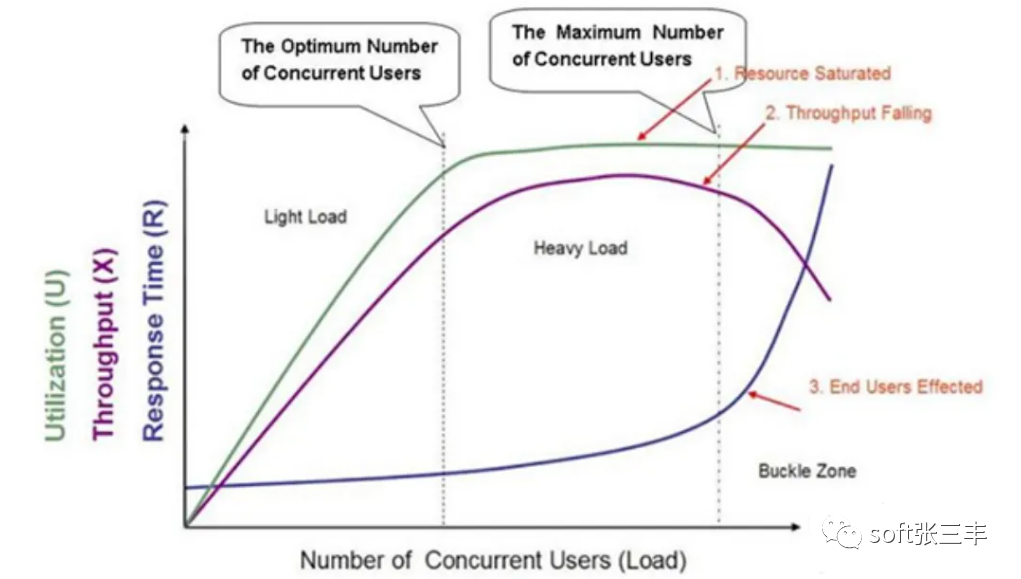
性能测试曲线模型是一条随着测试时间不断变化的曲线,与服务器资源,用户数或其他的性能指标密切相关的曲线。
一般的性能测试曲线图主要分为三个区域,分别是:
light load(轻压力区)
heavy load(重压力区)
Buckle Zone
图中的三条曲线,分别代表:
Utilization(资源利用率,指软硬件资源)
Throughput(吞吐量,即单位时间内处理请求的数量)
Response Time(响应时间)
图中坐标轴的横轴从左到右表示并发用户数(Number of Concurrent Users)的不断增长。
分析:
资源利用率在第一区域稳定增长,在第二区域小幅增长,在第三区域呈直线,表示饱和。
响应时间随着并发用户数的增加,在前两个区域基本平稳,小幅递增,在第三个区域急速递增,产生拐点。
同时,吞吐量随着并发用户数的增加,请求增加,在第一区域基本稳定上升,在第二区域处理达到顶点,随后开始下降。
当系统的负载等于最佳并发用户数时,整体效率最高,也没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大用户并发数之间时,系统可以继续工作但用户的等待时间延长;当系统负载大于最大并发用户数时,用户满意度基本为零,甚至放弃访问。
根据区域交界处,又衍生两个概念:
最佳并发用户数
The Optimum Number of Concurrent Users
Light Load和Heavy Load 两个区域交界处的并发用户数
最大并发用户数
The Maximum Number of Concurrent Users
Heavy Load和Buckle Zone两个区域交界处的并发用户数
性能拐点
1、对一个基本的请求做并发测试,看是否能达到tps=1000,或者找到tps拐点。
2、设置线程数为1,循环数为1,查看Throught为多少(假如是170),计算下如果想要达到1000的话大概需要多少线程数,1000/170,大约为6。
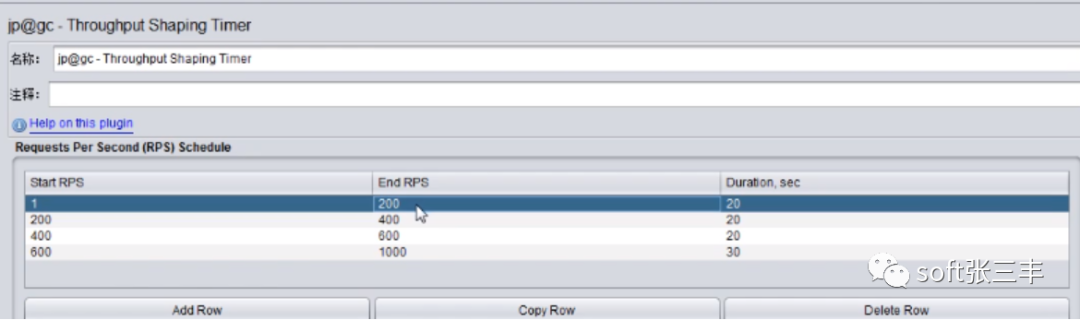
3、将线程数设置为6,对请求加一个Throught shaping timer ,设置如下:
4、将Tracactions per second的颗粒度调低点(settings)
5、运行,查看tps
性能测试行业常用的性能指标表示法

响应时间(RT response time)
吞吐量(Throughput)
并发用户数
QPS每秒查询率(Query Per Second)
TPS每秒执行的事务数量(throughput per second)
估算QPS峰值
并发数
首先,理解三个用户数的概念:
系统用户数、在线用户数、并发用户数
系统用户数就是一个系统中所有的注册用户数。eg. 当前微信中的所有注册用户数;在线用户数是当前登录系统的用户数,eg.当前登录微信的总用户数 (均为在线状态,不管该用户做什么操作);并发用户数是指对Server产生压力的用户数,eg.当前微信所有登录用户中,正在进行操作的用户数(仅指对Server产生压力的操作)
我们测试时仅关注并发用户数,一般,需求采集人员会将线上的并发用户数根据日志或工具分析统计出。测试时,要以性能测试需求为准,此外,并发操作也包含多种情况 ,如所有用户同时进行购买或支付操作;或多个用户同时发出多个不同请求,如加入购物车、删除商品、增减数量、支付、退款等操作。
响应时间
先看一个请求从发出到用户看到结果的过程:用户发送一个请求后,通过网络传输、DNS解析等步骤到达Server端后,Server通过各种算法处理,将结果通过网络传输返回到Client,Client要经过解析渲染等步骤,最后才呈现给用户。
通过以上流程可知,响应时间的计算模式:响应时间=请求传输时间+Server处理时间+响应传输时间+前端解析渲染时间。
由此可见,在工作中,一方面响应时间要根据不同业务及用户的具体要求而定;另一方面分析结果时要注意当前的业务模型(如前端性能测试与服务器性能测试)
资源利用率
关于资源利用率初期了解以下几个重要指标即可:
CPU
对于CPU都不陌生,简言之,是用来处理\判断事务的,CPU一般有系统CPU与用户CPU,前者是 处理系统占用的资源 ;而后者是处理应用程序占用的资源 。
网络
即网络传输的流量,测试过程中对网络的监控以,以分析是否存在瓶颈。
IO
即,Input/Output,输入/输出。关注与磁盘的交互频率等
内存
即数据存储区域。一般读数据时从内存中读取要比硬盘读取快很多 ,但需要关注的是内存溢出或内存泄漏问题。
队列
属于数据结构的概念了 ,是一种线性表,可以在队列前删除,在队尾处进行插入。测试过程中,如果发现队列越来越长,很可能会发生阻塞问题。