
脑机接口技术使瘫痪病人重获运动能力,4D打印技术已经到来!|技术...

热点追踪 / 深度探讨 / 实地探访 / 商务合作
滴!友情提醒:您的假期余额已经不足一天。
今天小探也按时为你带来技术前沿洞察,最近高校、大公司的最近技术真是眼花缭乱,阿司匹林减轻能够减轻空气污染伤害,4D打印系统已经到来,脑机接口技术帮助瘫痪病人站起来了!还有更多振奋人心的新技术,赶紧跟硅谷洞察来看!
美国高校
哈佛、哥大研究团队发现服用阿司匹林可以减轻空气污染伤害
一项新研究表明非甾体抗炎药(NSAID, 如阿司匹林)可以减轻空气污染暴露对肺功能的不利影响。
研究人员分析了从波士顿地区的2,280名男性退伍军人中收集的数据。参加者的平均年龄为73岁。研究人员检查了测试结果,自我报告的NSAID使用情况,测试前一个月的环境颗粒物(PM)和碳烟之间的关系,同时考虑了多种因素,包括受试者的健康状况以及是否吸烟。
由于研究人群中服用NSAID的大多数人都使用阿司匹林,因此研究人员说,他们观察到的修饰作用主要来自阿司匹林,但补充说非阿司匹林NSAID的作用值得进一步探讨。虽然机理尚不清楚,但研究人员推测,非甾体抗炎药可减轻空气污染引起的炎症。
“将我们暴露于空气污染的风险降至最低仍然很重要,因为空气污染与从癌症到心血管疾病等一系列不良健康影响有关。” 研究人员说。
感兴趣可以阅读:
https://www.sciencedaily.com/releases/2019/10/191002165233.htm
MIT开发新系统在干扰环境中定位,补位GPS
传统的定位技术利用GPS卫星或设备之间共享的无线信号来确定它们之间的相对距离和位置。但是在建筑物的内部、地下隧道、反射表面,障碍物或其他有干扰信号的地方,准确性会受到很大影响。
麻省理工学院,费拉拉大学,巴斯克应用数学中心(BCAM)和南加州大学的研究人员开发了一种系统,即使在这些干扰环境里也可以捕获位置信息。
当网络中的称为“节点”的设备在信号不通的环境中进行无线通信时,系统会融合节点之间交换的残缺的无线信号中的各种类型的位置信息以及数字地图和惯性信号数据。这样做时,每个节点都会考虑与所有其他节点的位置相关的所有信息(称为“软信息”)。
该系统利用机器学习技术和减少已处理数据维度的技术来根据测量值和背景数据确定可能的位置。然后使用这些信息来精确定位节点的位置。在恶劣环境的模拟中,该系统的运行明显优于传统方法。
感兴趣可以阅读:
http://news.mit.edu/2019/iot-smart-device-position-1003
无线疼痛控制器有望取代易成瘾阿片类药物
莱斯大学和得克萨斯医学中心的神经工程学者正合作开发一种可植入人体的无线神经刺激器,这种神经刺激器有望代替阿片类药物用于缓解病患疼痛。
神经性疼痛约占慢性疼痛患者的40%,常常导致病患焦虑,抑郁和对阿片类药物成瘾。作为阿片类药物的可替代品,新发明的可植入神经刺激器体积将足够小,可以被放置在支架上并在邻近中枢神经系统和周围神经系统特定区域的血管内输送。
研究表明,当医生测试脊髓和背根神经节(一束将感觉信息传递到脊髓的神经束)时,电刺激能够有效的减轻病患疼痛。这项技术将有助于减少与神经刺激疗法相关的风险,例如降低手术和感染的可能性。较小的设备还利于更精确的放置和更可预测的结果。
研究人员表示,研发才刚刚开始,需要进行临床前和试验来测试该装置的安全性和有效性。“我们的目标是为患有神经性疼痛且对药物治疗有抵抗力的患者提供一种非阿片类药物替代品。”

感兴趣可以阅读:
http://news.rice.edu/2019/10/04/wireless-pain-management-could-be-alternative-to-opioids/
卡内基梅隆大学、哈佛大学同时研发4D打印系统
4D打印是什么?4D打印是指利用“可编程物质”和3D打印技术,制造出在预定的刺激下(如放入水中,或者加热、加压、通电、光照等)可自我变换物理属性的三维物体。
最近,卡内基梅隆大学研发了一套叫做"A-line," 的4D打印系统。当需要被打印的物体可以穿过狭窄的开口,并随后变换形状时,该系统打印的材料就具有特殊的性能。例如,穿过狭窄瓶颈插入的杆可能会变成钩子,以将物体从瓶中捞出。或者将细长的细紧固件插入椅子座位的孔中,可能会将椅子腿锁定到位。
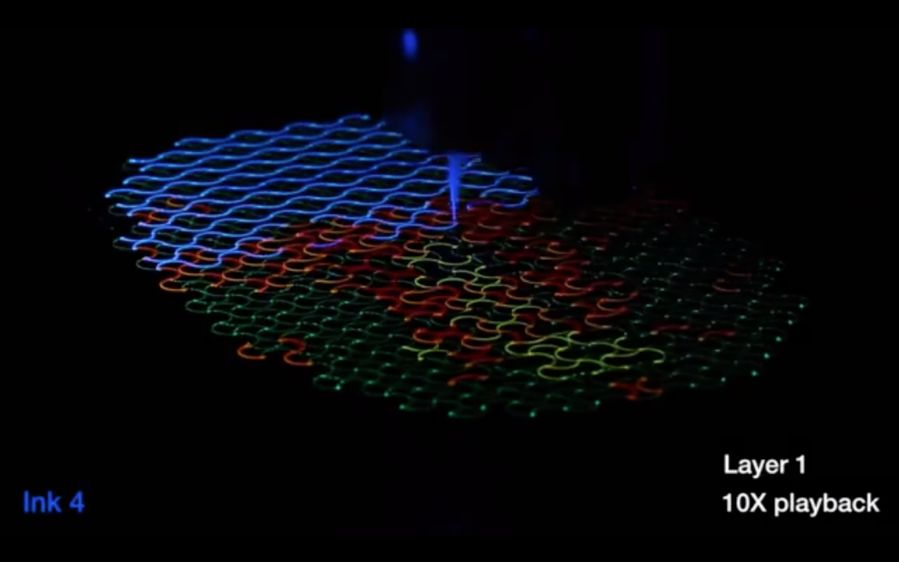
图:用A线系统生产的“线”形塑料结构在受热触发时会弯曲,折叠和扭曲成预定的形状
到目前为止,4D打印面临的最大挑战之一就是创建复杂的,平滑弯曲的形状的能力。这很难用简单的材料结构处理,而是需要使用多种材料的异构设计。因此哈佛的研究人员使用弯曲肋条,通过多方向的选择与重复,可以多层构建复杂的晶格。
在此过程中,肋条是使用四种不同的弹性体墨水组合沉积的-每种墨水对刺激的反应都不同。为了实现可预测的转换,在设计阶段预先确定了用于创建每个单独的肋的确切位置,方向和材料等等。
感兴趣可以阅读:
https://www.cs.cmu.edu/news/one-dimensional-objects-morph-new-dimensions
斯坦福大学深层组织成像技术,照亮人体内深处的肿瘤
斯坦福大学的化学家近日开发了一种新的深层组织成像技术,通过该技术,医生可以“看到”人体的皮肤下方,以无与伦比的清晰度探测到埋藏的肿瘤。
在9月30日出版的《自然生物技术》杂志上的一项新研究中,研究人员分享了如何使用这项技术来预测癌症患者对免疫疗法的反应,并跟踪其在治疗后的进展。
研究负责人为斯坦福大学人文与科学学院的化学教授Hongjie Dai,其把这种技术称为无创生物组织探测法。
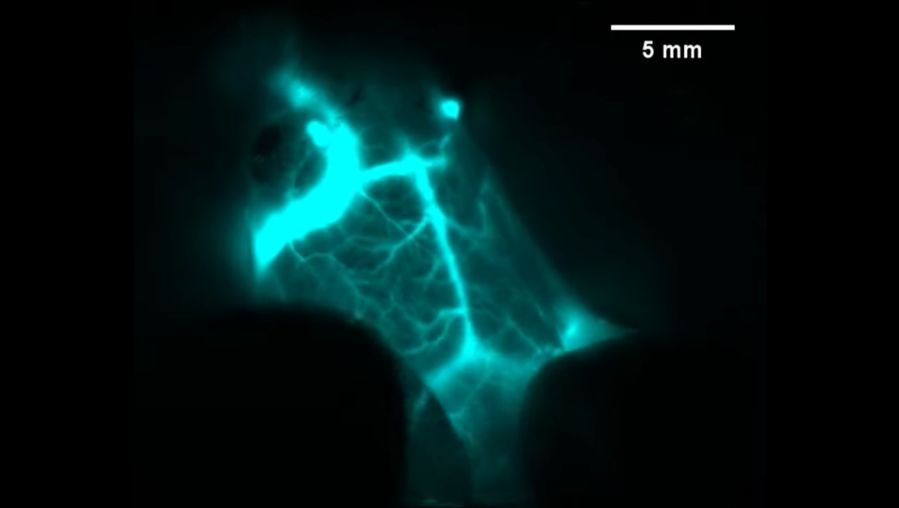
该技术依赖于含有铒元素的纳米颗粒,这种元素属于一类所谓的稀土矿物,在红外线照射下会发出独特的光线。
研究人员用化学涂层覆盖纳米颗粒,这有助于纳米颗粒溶解在人的血液中,并使其毒性更小并且能更快地排出体外。另外,该涂层为分子提供了锚定点,这些分子可以定位并附着在细胞上的特定蛋白质上。
感兴趣可以阅读:
https://news.stanford.edu/2019/10/03/infrared-vision-immunotherapy/
海外高校
瘫痪病人使用脑接机器再次“站立行走”
BBC报道,30岁的法国瘫痪男子Thibault穿戴可以由他本人大脑控制的机器外衣,成功恢复了对瘫痪四肢的控制。
研究人员对Thibault进行了手术,将两个感应片放置在他的大脑表面,覆盖控制运动的大脑部分。感应片读取大脑的指令信号,将指令发送到连接的计算机,该计算机随后将信号转换为机器外衣的运动信号。

实验室公布了一段视频,视频中Thibault穿着笨重的重达143磅的机器外衣,该机器被称为“体外骨架”。他走过房间,双臂向各个方向移动。
2017年起,他参与了Clinatec实验室和格勒诺布尔大学一起研发的“体外骨架”项目。最初他在游戏中练习使用大脑读取片控制虚拟角色,逐渐进展到穿戴机器人外衣行走。
该实验室希望获得更详细的大脑植入物读数图,及功能更强大的计算机来改善机器的响应能力。但目前的实验结果已经使研究人员深受鼓舞。
目前Thibault能控制的动作远未完美,且机器人服目前仅能在实验室中使用。但研究人员说,这种方法总有一天可以大大改善患者的生活质量。
感兴趣可以阅读:
https://www.bbc.com/news/health-49907356
大公司
手机程序从个人照片中监测眼部疾病,AI发现某些早期眼疾胜过医生
智能手机应用程序White Eye Detector可以通过分析照片比医生早一年发现儿童眼部疾病。该APP使用机器学习,在照片中测评瞳孔在照片中反射白光的迹象。儿童白瞳症在照片中看起来与闪光导致的红眼相似,但是“红眼”实际上是眼睛健康的标志,而白色反射有可能是问题的征兆。
“白眼”有可能表明儿童患有视网膜癌母细胞瘤,或其他罕见眼疾,包括早产儿视网膜病变,白内障等。尽早发现这些疾病可以保留病眼,甚至挽救生命。
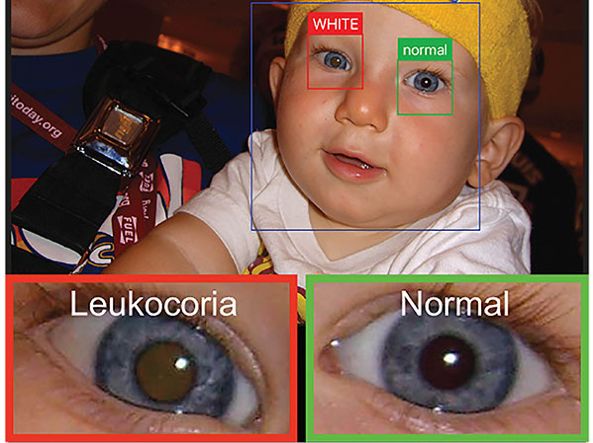
为了测试该系统,研发团队对40名儿童测试了近53000张照片。其中一半测试者眼睛健康,另一半已被诊断出患有白斑病相关的眼病。在20名患病的儿童中,该应用程序成功以被医生确诊前平均1.3年的照片确诊16名。
研究人员证实该APP平均能比医生提前9个月的时间确诊单侧视网膜母细胞瘤患病儿童,而这个时间足以决定患儿是否能保留病眼。
感兴趣可以阅读:
https://spectrum.ieee.org/the-human-os/biomedical/diagnostics/app-detects-eye-disease-in-personal-photos
谷歌提升大规模多语种的语音识别能力
Google Assistant的一项核心功能是理解人类语音,并且要确保其产品能够为世界上尽可能多的语种服务。但这充满了挑战,因为高质量的自动语音识别(ASR)系统需要大量的音频和文本数据。而许多小语种几乎没有可用的数据。
在2019年9月Interspeech上,谷歌研究团队发布了《具有流式端到端模型的大型多语言语音识别》论文,介绍了一个端到端(E2E)系统,该系统用单个语言训练模型,但可实现实时多语言识别。其背后的理念是,神经网络模型可以从一种数据丰富的语言的音频数据中学习“知识”,获得训练,然后被数据稀缺的语言使用,而并不需要从头开始学习所有内容。
研究团队用9种印度语言做了测试,证明了该系统在用于数据稀缺的小语种时,ASR质量显着提高。
感兴趣可以阅读:
https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
Deepfake专家表示:“完全真实”的Deepfake将在6个月到1年内发生
Deepfake专家兼南加州大学计算机科学副教授黎颢近日在接受CNBC采访时表示,肉眼无法辨别的深度虚假视频的出现,只需要6-12个月的时间。
黎颢说:“很快,我们将无法再真正检测Deepfake了,因此我们必须考虑其他类型的解决方案。”
他补充说,Deepfake在时尚和娱乐领域肯定有积极的用途,例如其可以使远程视频会议的体验更好。但是如果用于恶作剧和政治则很糟糕。黎颢原本预测该技术的发展还需要2-3年的时间,但是越来越多的研究和令人难以置信的Zao换脸应用程序使他调整了预测时间。
黎颢认为,Deepfake技术本身不是问题,而是人们使用该技术来欺骗或伤害会带来问题。那么我们如何避免严重的后果呢? “如果你需要构建能够检测出Deepfake内容的人工智能框架,则必须使用同类技术对检测模型进行训练。因为如果你不知道它们是如何工作的,则就很难检测出它们。”

感兴趣可以阅读:
https://futurism.com/pioneer-perfect-deepfake-six-months-away
怎么样,今天的哪条技术前沿让你印象最深?欢迎大家留言讨论!
更多硅谷热文,欢迎阅读硅谷洞察往期文章:
又见大裁员,WeWork计划裁员比例可能达25%!|一周硅谷热闻
没wifi没网也能用App!10分钟干洗机来了……硅谷初创公司在做啥?

推荐阅读
