
图解unicode、utf8和utf8mb4
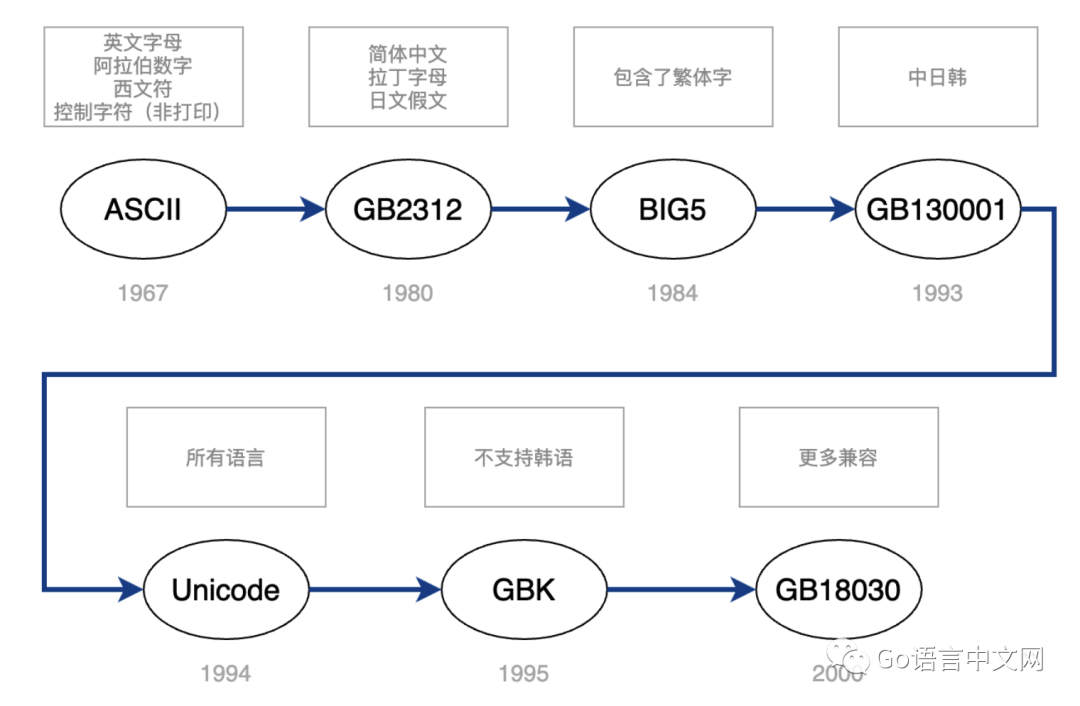
字符集和字符编码
字符集(CCS: Coded Character Set):
就是一个表格,表示每个字符对应数字(通常用16进制表示),比如unicode字符集中,数字1对应的就是U+00031,字母a对应的就是U+00061。
字符编码(CEF:Character Encoding Form):
因为计算机只认识0和1,所以计算机在存储字母a(U+00031)的时候,不能直接存储。所以就需要编码将字母a转换成01表示形式。对于unicode字符,utf8就是它的编码方案(如何utf8转换成01表示下文介绍)。
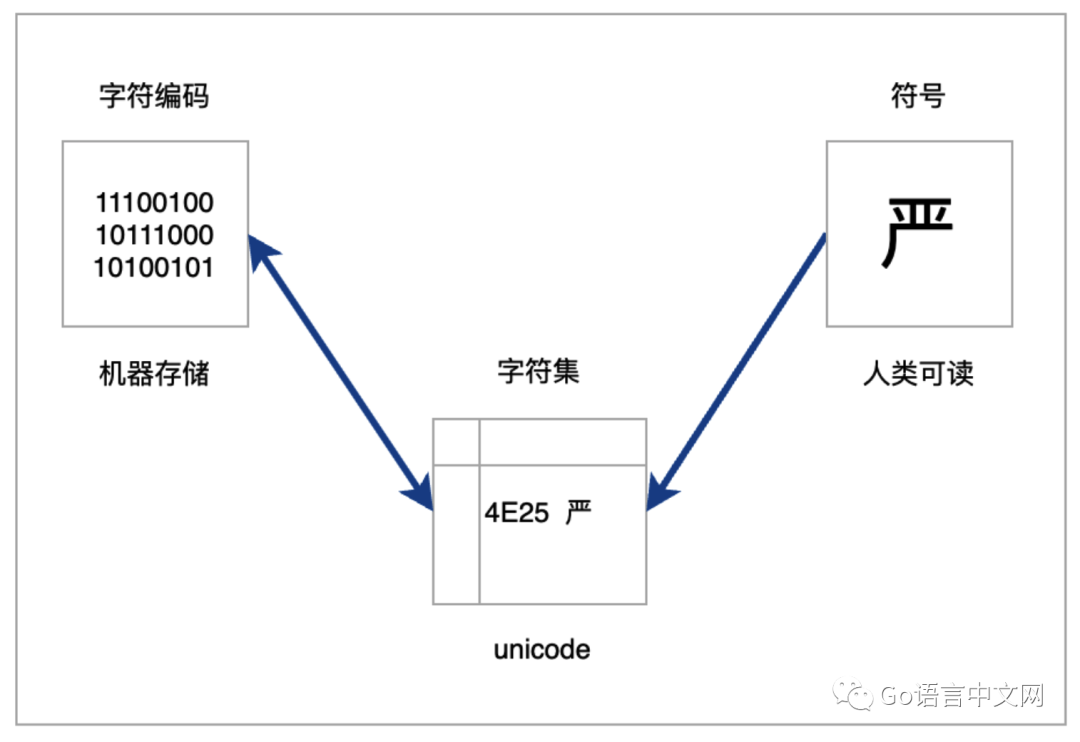
字符:
字符简单理解就是人类能(容易)看懂得符号。
比如对于汉字严,机器存储的是11100100 10111000 10100101,人类根本看不懂。转换成unicode表示方法是U+4E25,依然看不懂。
人类只能看懂严这个字符,三者之间的关系如下:
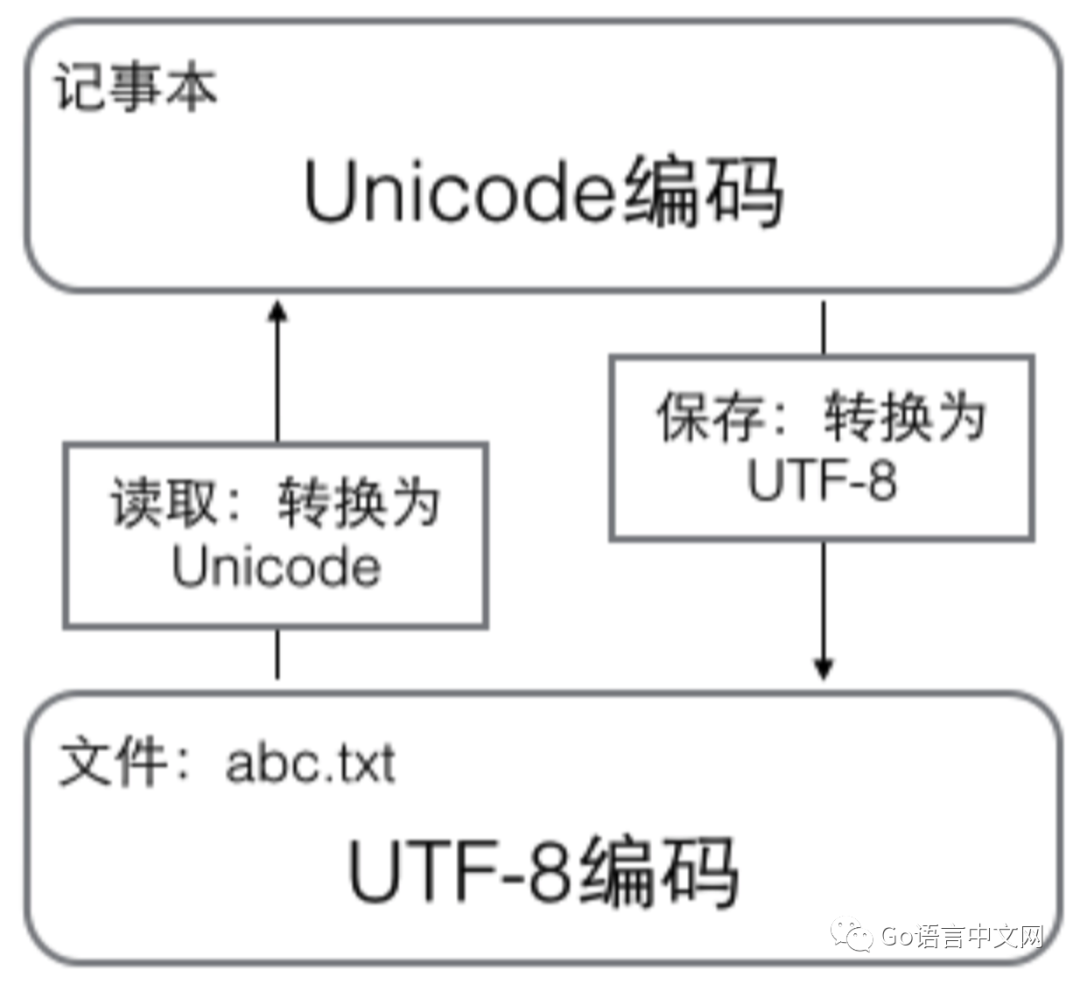
字符串到保存文件过程如下:
UTF-8编码
严这个字的unicode码是U+4E25(对应的二进制数字是100111000100101),而utf8编码之后是11100100 10111000 10100101,是不是很奇怪?两个二进制完全不一样,是因为utf8有一套编码规则。

UTF-8编码规则
utf8 最大的一个特点,就是它是一种可变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
utf8 的编码规则很简单,只有二条:
对于单字节的符号,字节的第一位设为 0,后面7位为这个符号的 Unicode 码。因此对于英语字母,utf8编码和ASCII码是相同的。对于 n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
严字的Unicode编码是4E25处于0000 0800 - 0000 FFFF这个范围里面,所以需要三个字节表示。
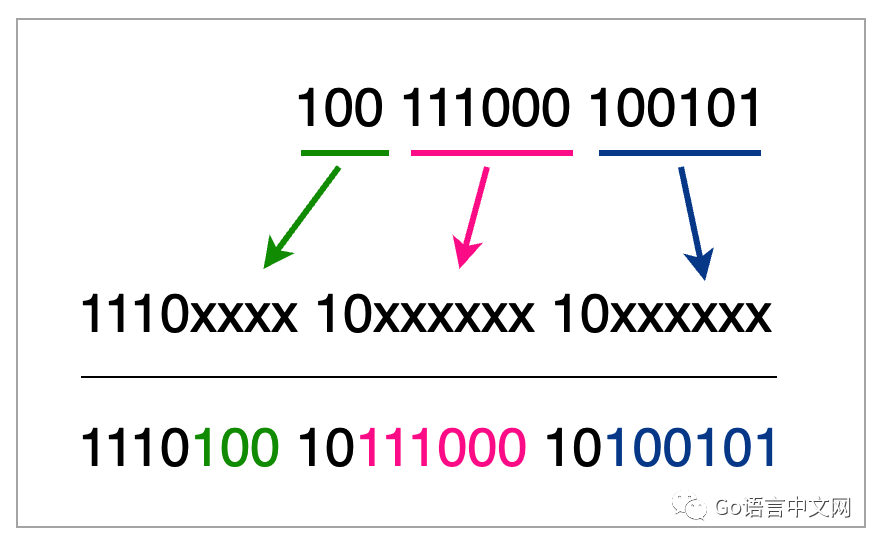
哇塞,原来是这样
utf8和utf8mb4
utf8mb4只是mysql特有的概念,原因是mysql在5.5.3之前,Unicode收录的字符还不是很多,(最大)3个字节足够存储,所以那时的mysql把utf8(alias of "utf8mb3")存储也设计为3字节存储。后来Unicode收录的字符更多了,扩张到4字节了(比如表情😁)。
MySQL也在5.5.3版本之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的Unicode。
MySQL官方网站也解释了utf8mb3和utf8mb4之间的关系。
https://dev.mysql.com/doc/refman/8.0/en/charset-unicode-utf8mb4.html
https://dev.mysql.com/doc/refman/8.0/en/charset-unicode-utf8mb3.html
总结
Unicode是字符集,是符合和码点的映射表utf8是Unicode的一种最常见的字符编码方式(还有utf16、utf32)mysql中utf8实际上是utf8mb3(最大存储3字节),utf8mb4最大可以存储4字节(大部分表情都要占用4字节,所以需要选择utf8mb4)
推荐阅读