
new ArrayList 不当导致 CPU 飙升。。
往期热门文章:
1、假如Linus在中国···
2、通过 Arthas Trace 命令将接口性能优化十倍
3、一个由“ YYYY-MM-dd ”引发的惨案
4、不要只盯着大厂,这20家中小厂我建议你也试试
5、百万数据excel导出功能如何实现?
目录
前言
当时场景
具体分析
结束语

前言
昨天线上容器突然cpu飙升,也是第一次排查这种问题所以记录一下~
当时场景
1.正常的jvm监控曲线图
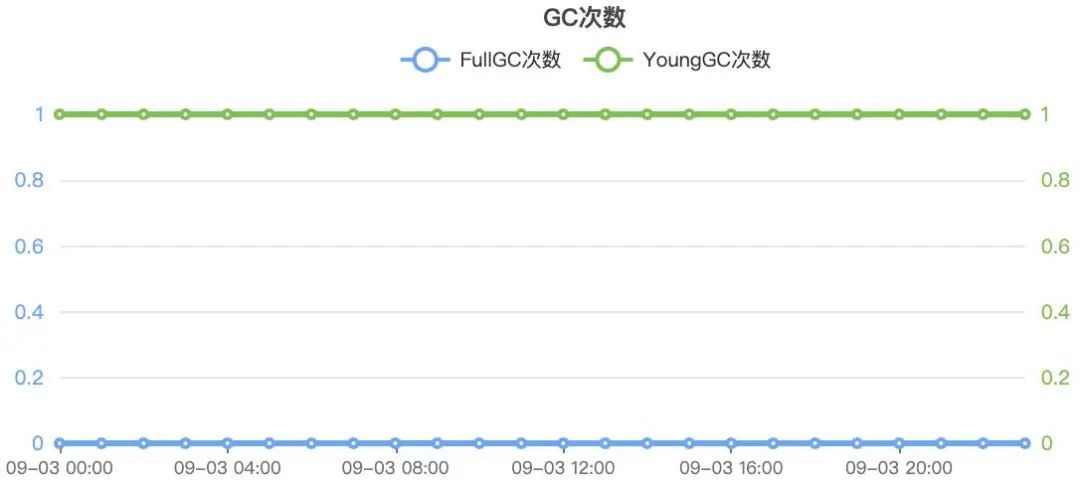
2.产生问题的jvm监控曲线图

具体分析
-
进入pod之后,输入top查看各linux进程对系统资源的使用情况(因我这是事后补稿,资源使用不高,大家看步骤即可)

-
分析资源使用情况在当时的情况下,
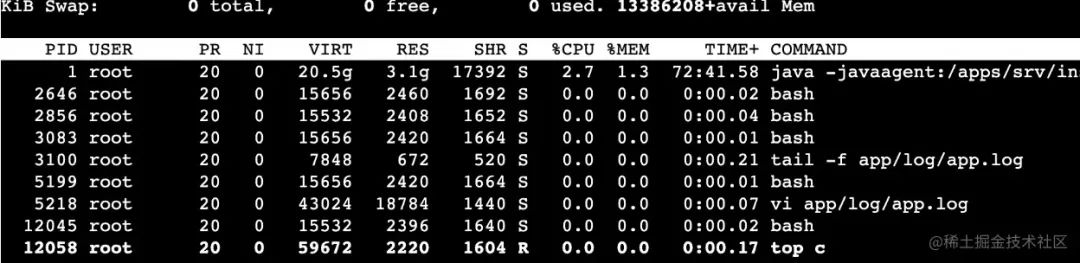 当时我的pid为1的进程cpu上到了130(多核)那我认定就是java应用出问题了,control+c退出继续往下走
当时我的pid为1的进程cpu上到了130(多核)那我认定就是java应用出问题了,control+c退出继续往下走
-
输入top -H -p pid 通过此命令可以查看实际占用CPU最高的的线程的id,pid为刚才资源使用高的pid号

-
出现具体线程的资源使用情况,表格里的pid代表线程的id,我们称他为tid

-
我记得当时的tip为746(上述图片只是我给大家重复步骤),使用命令printf "%x\n" 746,将线程tid转换为16进制,
 因为我们线程id号在堆栈里是16进制的所以需要做一个进制转换
因为我们线程id号在堆栈里是16进制的所以需要做一个进制转换
-
输入jstack pid | grep 2ea >gc.stack
 解释一下,jstack是jdk给提供的监控调优小工具之一,jstack会生成JVM当前时刻的线程快照,然后我们可以通过它查看某个Java进程内的线程堆栈信息,之后我们把堆栈信息通过管道收集2ea线程的信息,然后将信息生成为gc.stack文件,我随便起的,随意
解释一下,jstack是jdk给提供的监控调优小工具之一,jstack会生成JVM当前时刻的线程快照,然后我们可以通过它查看某个Java进程内的线程堆栈信息,之后我们把堆栈信息通过管道收集2ea线程的信息,然后将信息生成为gc.stack文件,我随便起的,随意
-
当时我先cat gc.stack 发现数据有点多在容器里看不方便,于是我下载到本地浏览,因为公司对各个机器的访问做了限制,我只能用跳板机先找到一台没用的机器a,把文件下载到a然后我再把a里的文件下载到本地(本地访问跳板机OK),先输入python -m SimpleHTTPServer 8080,linux自带python,这个是开启一个简单http服务供外界访问,
 然后登录跳板机,使用curl下载curl -o http://ip地址/gcInfo.stack 为方便演示,我在图中把ip换了一个假的
然后登录跳板机,使用curl下载curl -o http://ip地址/gcInfo.stack 为方便演示,我在图中把ip换了一个假的
 之后用同样的方法从本地下载跳板机就可以了,记得关闭python开启的建议服务嗷
之后用同样的方法从本地下载跳板机就可以了,记得关闭python开启的建议服务嗷
-
把文件下载到了本地,打开查看编辑器搜索2ea,找到nid为2ea的堆栈信息,
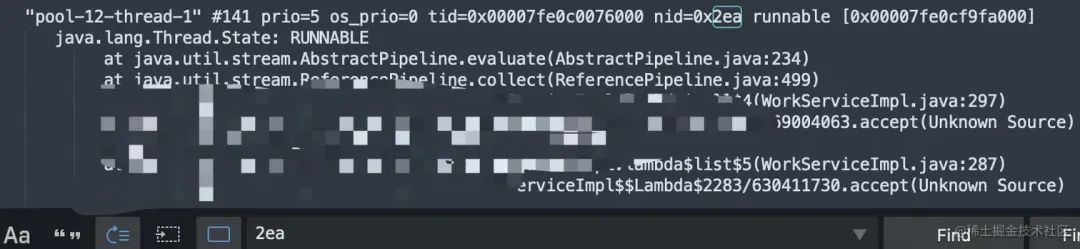 之后找到对应的impl根据行数分析程序
之后找到对应的impl根据行数分析程序
-
发现是在文件异步导出excel的时候,导出接口使用了公共列表查询接口,列表接口查询数据最多为分页200一批,而导出数据量每个人的权限几万到十几万不等
 并且该判断方法使用了嵌套循环里判断,且结合业务很容易get不到value,guawa下的newArrayList就是返回一个newArrayList(好像不用说这么细 (;一_一 ),在整个方法结束之前,产生的lists生命周期还在所以发生多次gc触发重启之后还影响到了别的pod。然后对代码进行了fix,紧急上线,问题解决~
并且该判断方法使用了嵌套循环里判断,且结合业务很容易get不到value,guawa下的newArrayList就是返回一个newArrayList(好像不用说这么细 (;一_一 ),在整个方法结束之前,产生的lists生命周期还在所以发生多次gc触发重启之后还影响到了别的pod。然后对代码进行了fix,紧急上线,问题解决~
结束语
往期热门文章:
1、为什么 Spring和IDEA 都不推荐使用 @Autowired 注解
2、公司新来一个同事:为什么 HashMap 不能一边遍历一边删除?一下子把我问懵了!
3、缓存没预热,翻车了!
4、Java反射和new效率对比,差距有多大?
5、Java14 处理 NullPointerException 新方式,真的太香了!
6、40 个 SpringBoot 常用注解:让生产力爆表!
7、优秀开源软件的类,都是怎么命名的?
8、宇宙第一 IDE 放弃了 Mac。。。
9、当年很流行,现在已经淘汰的Java技术,请不要在继续学了!!!
10、如何正确使用 ThreadLocal,你真的用对了吗?
评论