
JDK8 Stream 效率如何?
点击上方 好好学java ,选择 星标 公众号
重磅资讯,干货,第一时间送达
今日推荐:推荐19个github超牛逼项目!
个人原创100W +访问量博客:点击前往,查看更多
作者:Al_assad 链接:blog.csdn.net/Al_assad/article/details/82356606
Stream 是Java SE 8类库中新增的关键抽象,它被定义于 java.util.stream (这个包里有若干流类型:Stream<T> 代表对象引用流,此外还有一系列特化流,如 IntStream,LongStream,DoubleStream等 )。
stream 的操作种类
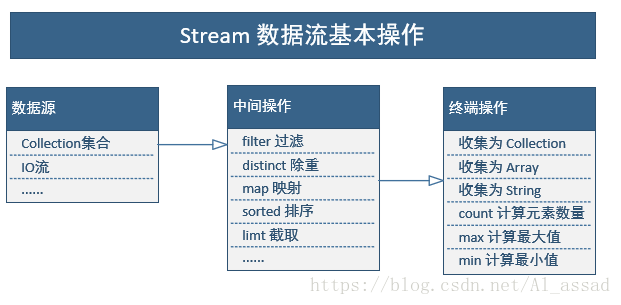
① 中间操作
当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为“中间操作”;
中间操作仍然会返回一个流对象,因此多个中间操作可以串连起来形成一个流水线;
stream 提供了多种类型的中间操作,如 filter、distinct、map、sorted 等等;
②终端操作
当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终端操作;
stream 对于终端操作,可以直接提供一个中间操作的结果,或者将结果转换为特定的 collection、array、String 等;
这一部分详细的说明可以参见:JDK8 Stream 详细使用
stream 的特点
① 只能遍历一次:
数据流的从一头获取数据源,在流水线上依次对元素进行操作,当元素通过流水线,便无法再对其进行操作,可以重新在数据源获取一个新的数据流进行操作;
② 采用内部迭代的方式:
对Collection进行处理,一般会使用 Iterator 遍历器的遍历方式,这是一种外部迭代;
而对于处理Stream,只要申明处理方式,处理过程由流对象自行完成,这是一种内部迭代,对于大量数据的迭代处理中,内部迭代比外部迭代要更加高效;
stream 相对于 Collection 的优点
无存储:
函数式风格:
对于一些collection的迭代处理操作,使用 stream 编写可以十分简洁,如果使用传统的 collection 迭代操作,代码可能十分啰嗦,可读性也会比较糟糕;
stream 和 iterator 迭代的效率比较
System:Ubuntu 16.04 xenial
CPU:Intel Core i7-8550U
RAM:16GB
JDK version:1.8.0_151
JVM:HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
JVM Settings:
-Xms1024m
-Xmx6144m
-XX:MaxMetaspaceSize=512m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=100//stream
List<Integer> result = list.stream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List<Integer> result = new ArrayList<>();
for(Integer e : list){
result.add(++e);
}
//parallel stream
List<Integer> result = list.parallelStream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));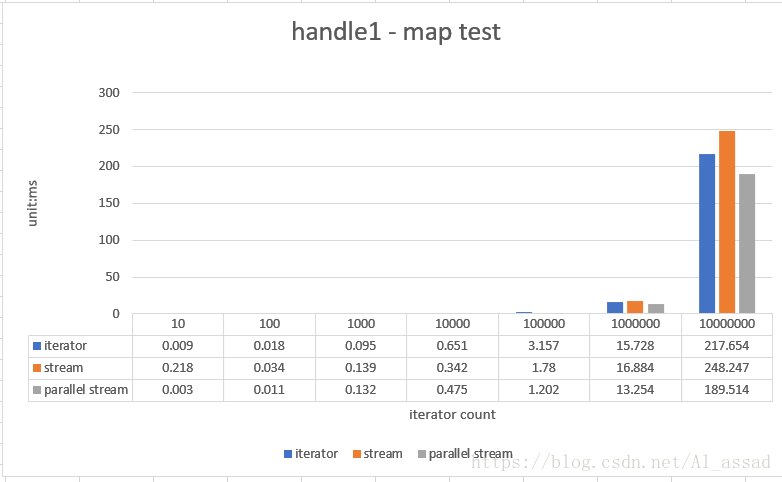
//stream
List<Integer> result = list.stream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List<Integer> result = new ArrayList<>(list.size());
for(Integer e : list){
if(e > 200){
result.add(e);
}
}
//parallel stream
List<Integer> result = list.parallelStream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));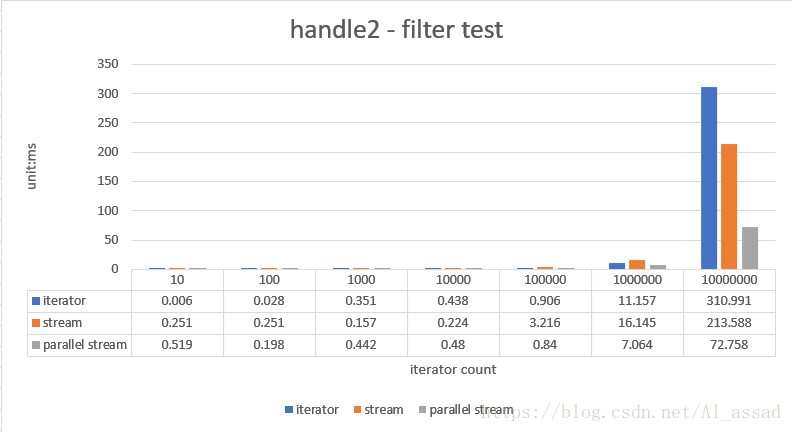
//stream
List<Integer> result = list.stream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List<Integer> result = new ArrayList<>(list);
Collections.sort(result);
//parallel stream
List<Integer> result = list.parallelStream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));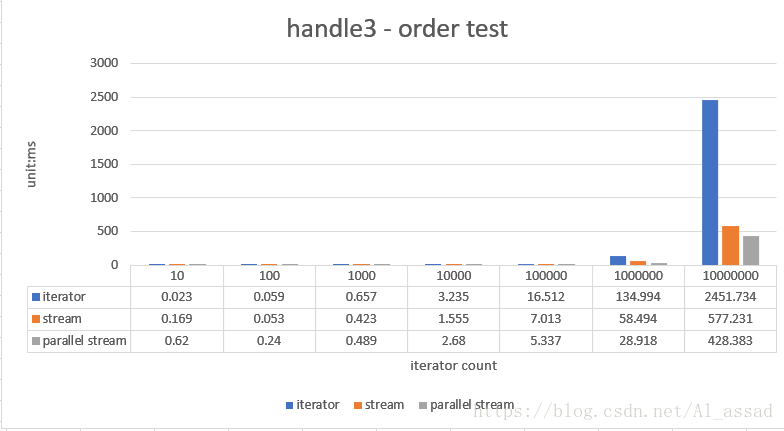
//stream
int max = list.stream()
.mapToInt(x -> x)
.max()
.getAsInt();
//iterator
int max = -1;
for(Integer e : list){
if(e > max){
max = e;
}
}
//parallel stream
int max = list.parallelStream()
.mapToInt(x -> x)
.max()
.getAsInt();
//stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
//iterator
StringBuilder builder = new StringBuilder();
for(Integer e : list){
builder.append(e).append(",");
}
String result = builder.length() == 0 ? "" : builder.substring(0,builder.length() - 1);
//parallel stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));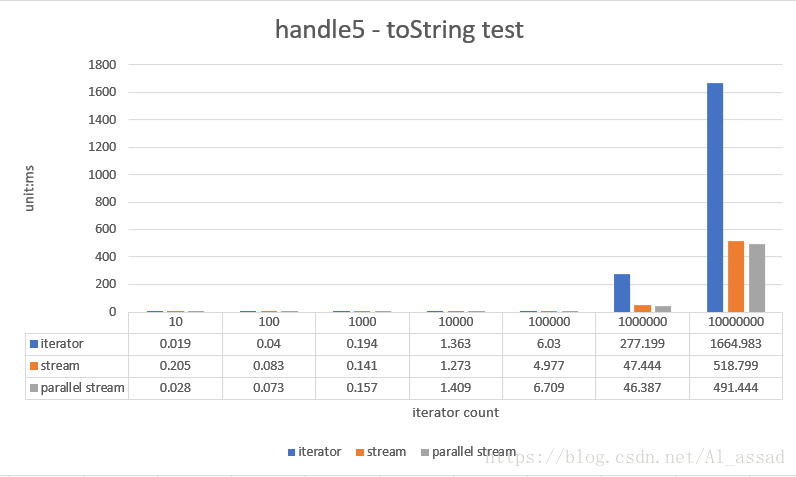
//stream
List<Integer> result = list.stream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
HashSet<Integer> set = new HashSet<>(list.size());
for(Integer e : list){
if(e != null && e > 200){
set.add(e + 1);
}
}
List<Integer> result = new ArrayList<>(set);
//parallel stream
List<Integer> result = list.parallelStream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));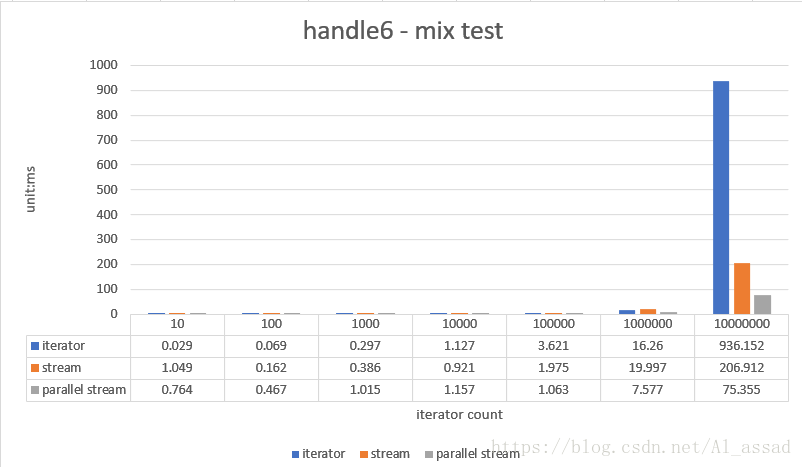
推荐文章
更多项目源码