
入门语音分离,从鸡尾酒问题开始!
AI作者:田 旭
AI编辑:田 旭
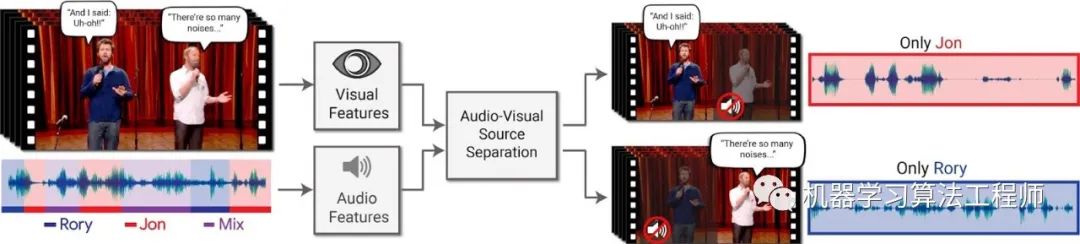
谷歌这篇文章《Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation》,宣称“攻克”了鸡尾酒会问题。从提供的视频演示来看,可以通过滑动控制只听某一个人说话,非常神奇。


这篇文章本身大概讲了这么一个事:
提出一个视觉-听觉联合模型,通过视觉信息来检测环境中谁在说什么并且分离出来;模型包含两个网络来分别分析视频和音频,通过融合层合并特征,最后使用传统的时频掩膜(Time-frequency masking)来分离语音部分;
训练过程中,搜集大量(90000)高质量、单说话人且头部位置比较正的视频,选取其中说话声音干净的部分,通过融合不同的视频或者给视频加噪声来创建训练集。
由于本人水平有限,如有分析不对的地方,欢迎指正和交流。
01
鸡尾酒会问题

“语音分离”(Speech Separation)来自于“鸡尾酒会问题”,采集的音频信号中除了主说话人之外,还有其他人说话声的干扰和噪音干扰。语音分离的目标就是从这些干扰中分离出主说话人的语音。
根据干扰的不同,语音分离任务可以分为三类:
当干扰为噪声信号时,可以称为“语音增强”(Speech Enhancement)
当干扰为其他说话人时,可以称为“多说话人分离”(Speaker Separation)
当干扰为目标说话人自己声音的反射波时,可以称为“解混响”(De-reverberation)
由于麦克风采集到的声音中可能包括噪声、其他人说话的声音、混响等干扰,不做语音分离、直接进行识别的话,会影响到识别的准确率。因此在语音识别的前端加上语音分离技术,把目标说话人的声音和其它干扰分开就可以提高语音识别系统的鲁棒性,这从而也成为现代语音识别系统中不可或缺的一环。
基于深度学习的语音分离,主要是用基于深度学习的方法,从训练数据中学习语音、说话人和噪音的特征,从而实现语音分离的目标。
02
传统方法
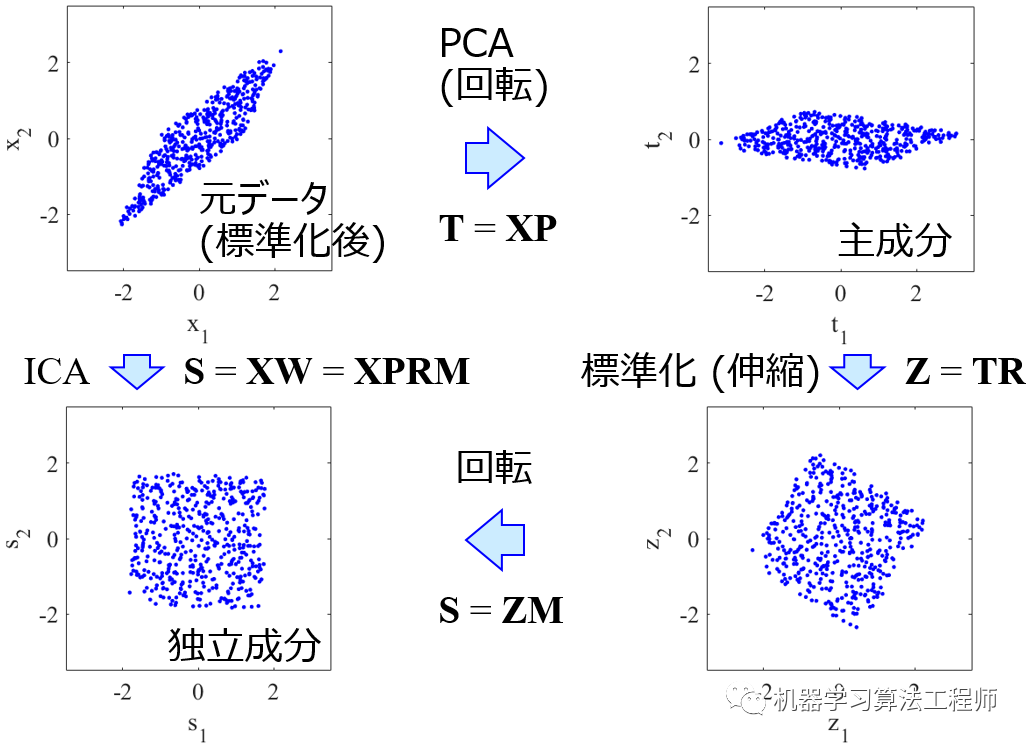
独立分量分析(Independent Component Analysis,ICA)是将信号之间的独立性作为分离变量判据的方法。由Comon于1994年首次提出。Comon指出ICA方法可以通过某个对比函数(Contrast Function)的目标函数达到极大值来消除观察信号中的高阶统计关联,实现盲源分离。盲源分离被描述成在不知道传输通道特性的情况下,从传感器或传感器阵列中分离或估计原始源波形的问题。然而,对于某些模型,不能保证估计或提取的信号与源信号具有完全相同的波形,因此有时要求放宽到提取的波形是源信号的失真或滤波版本。







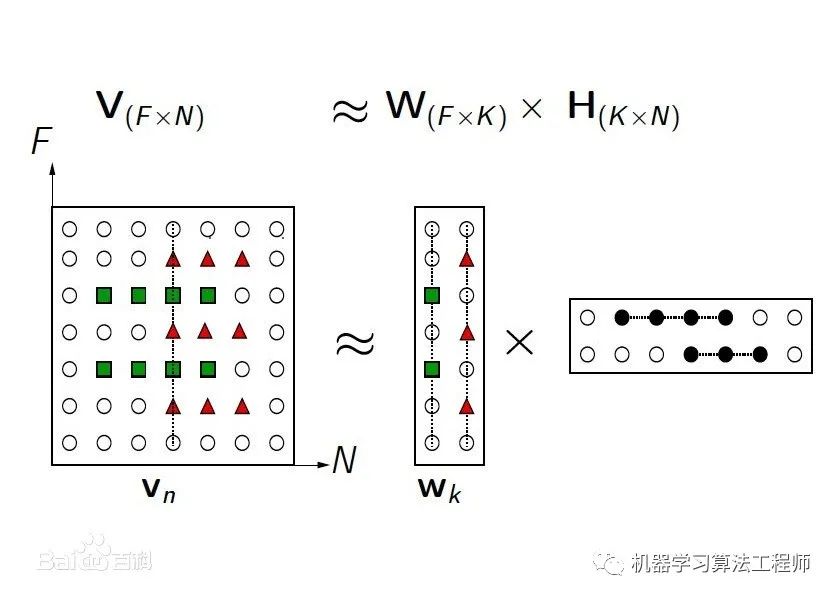
03
深度学习方法


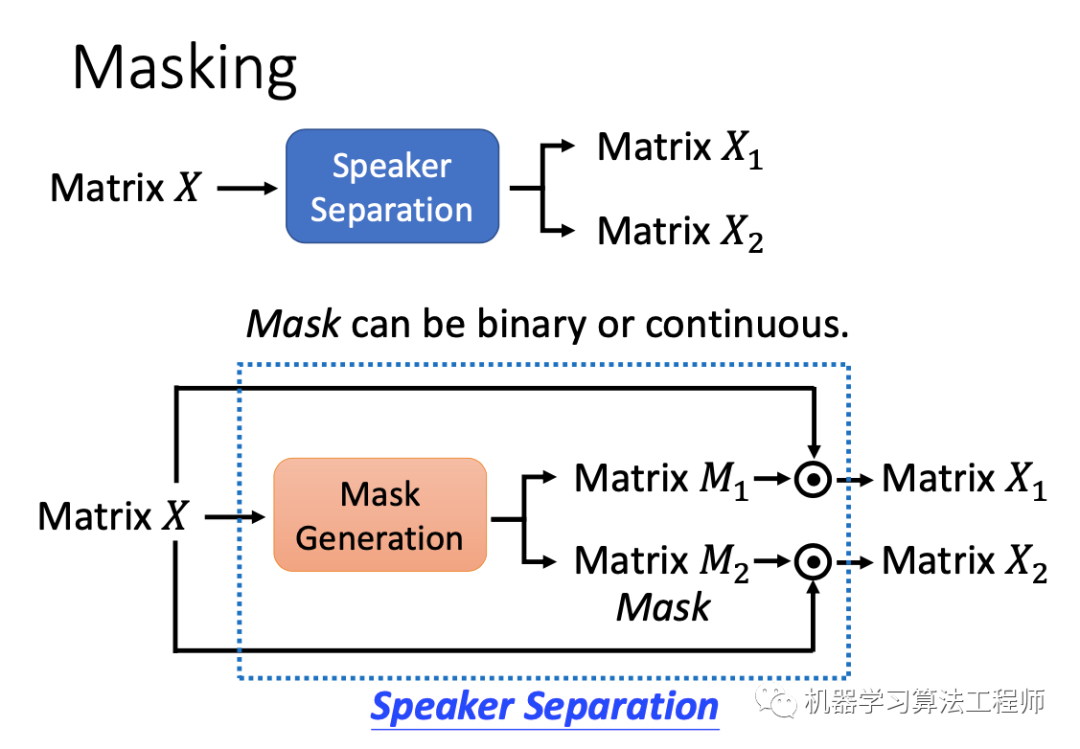
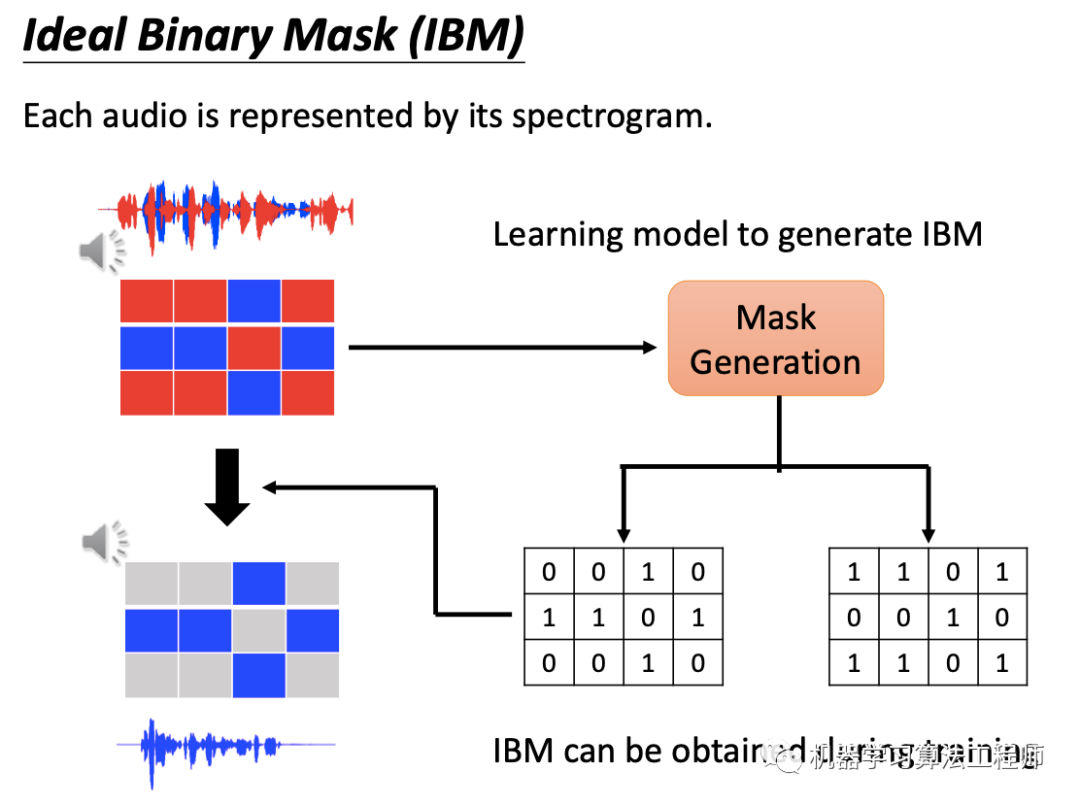
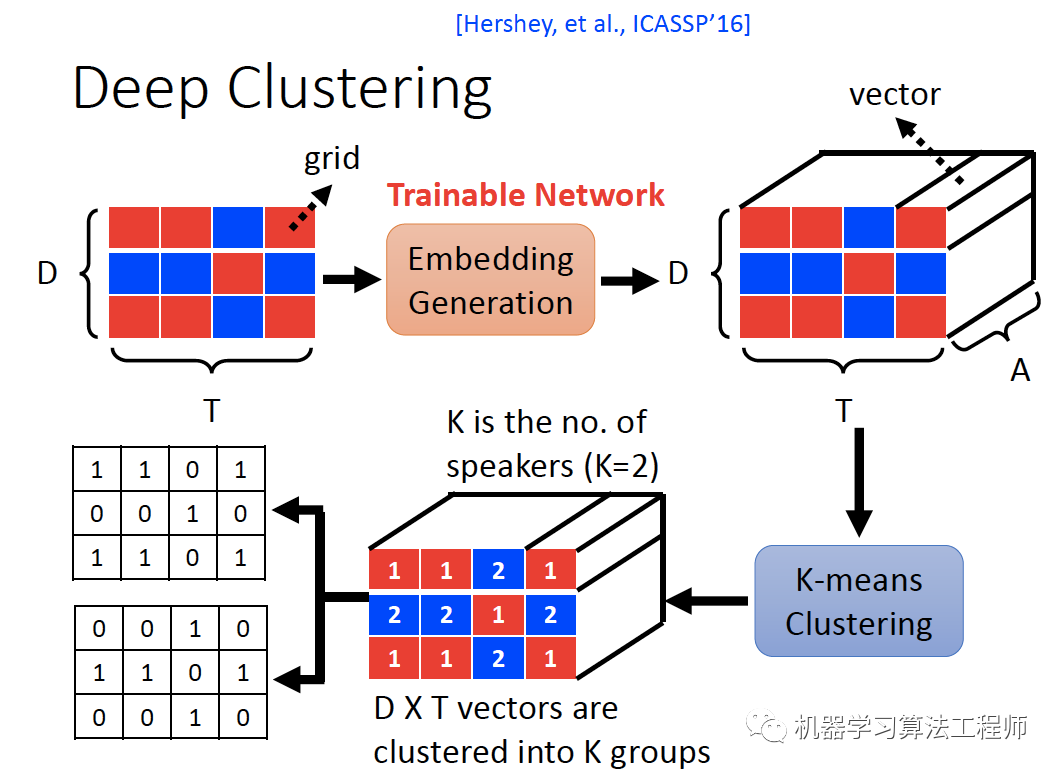
下面介绍几种流行的深度学习语音分离方法。


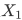 和
和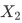 ,由于输出排列不确定,我们无法确定网络的哪一个输出与对应,哪一个与对应。假设网络对两个说话人的估计是
,由于输出排列不确定,我们无法确定网络的哪一个输出与对应,哪一个与对应。假设网络对两个说话人的估计是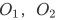 说话人无关语音分离需要解决的问题就是与,,之间如何匹配的问题。PIT网络中对说话人语音的估计可以使用特征映射的方法,也可以使用时频掩蔽的方法。此时对说话人的预测可能由下式得到:
说话人无关语音分离需要解决的问题就是与,,之间如何匹配的问题。PIT网络中对说话人语音的估计可以使用特征映射的方法,也可以使用时频掩蔽的方法。此时对说话人的预测可能由下式得到: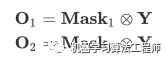
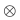 表示元素相乘。对于与,,网络预测与真实目标之间可能共有两种组合方式,可以每种组合方式计算对应的预测误差,选择误差小的那种输出排列,利用这种排列再对网络进行训练。
表示元素相乘。对于与,,网络预测与真实目标之间可能共有两种组合方式,可以每种组合方式计算对应的预测误差,选择误差小的那种输出排列,利用这种排列再对网络进行训练。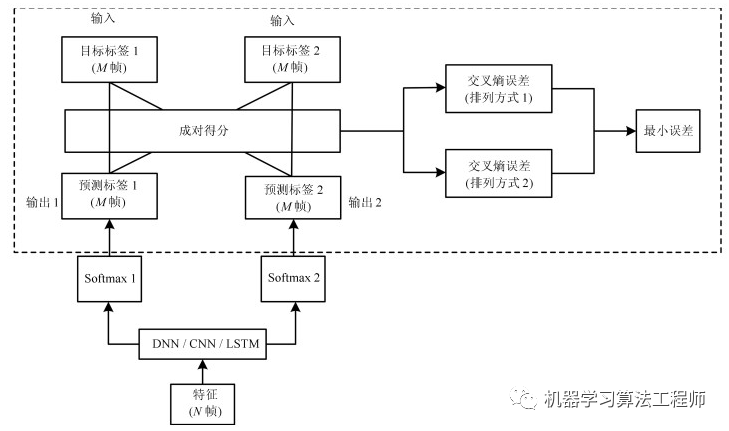

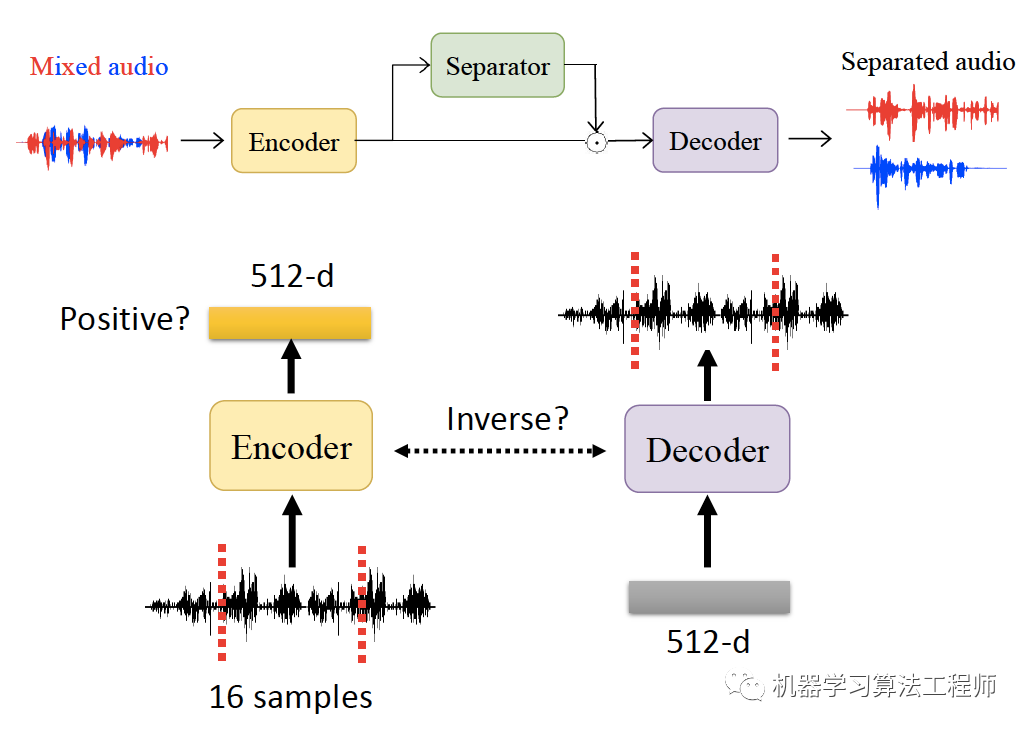
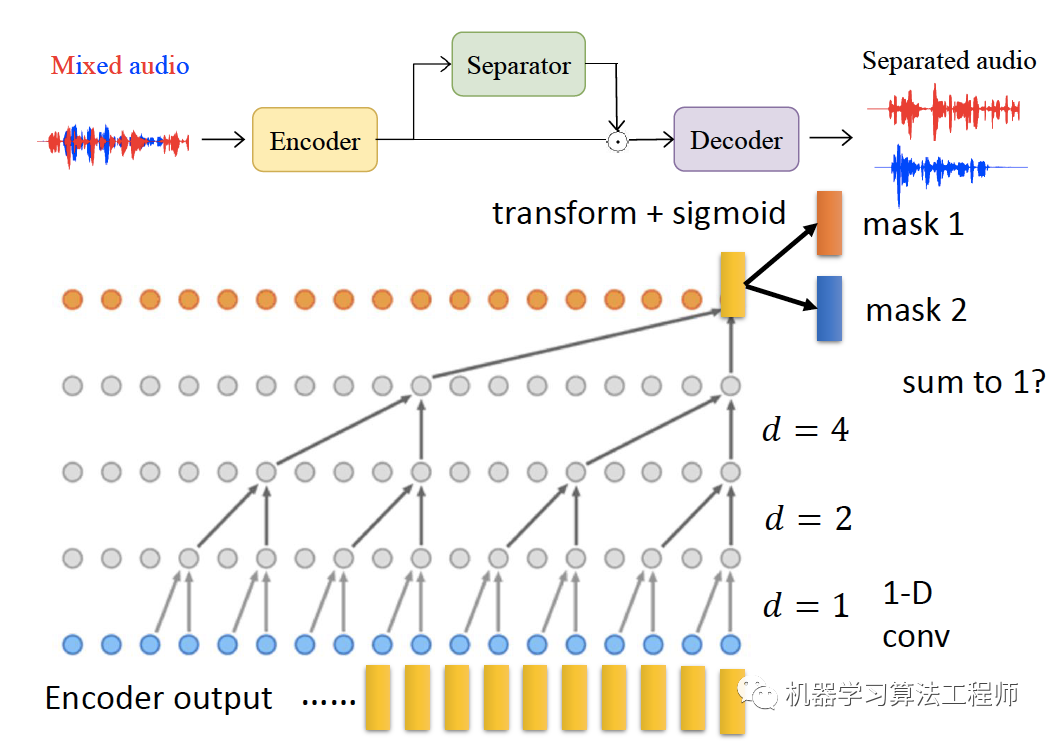
04
总结
参考资料:
李宏毅深度学习(2020)课程http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
https://www.zhihu.com/question/274090770
李宏毅深度学习(2020)学习笔记 https://zhuanlan.zhihu.com/p/137771442

END
机器学习算法工程师
一个用心的公众号
