
牛x!一个比传统数据库快 100-1000 倍的数据库!

阅读本文大概需要 2.8 分钟。
来自:juejin.im/post/6863283398727860238
一、ClickHouse 是什么?
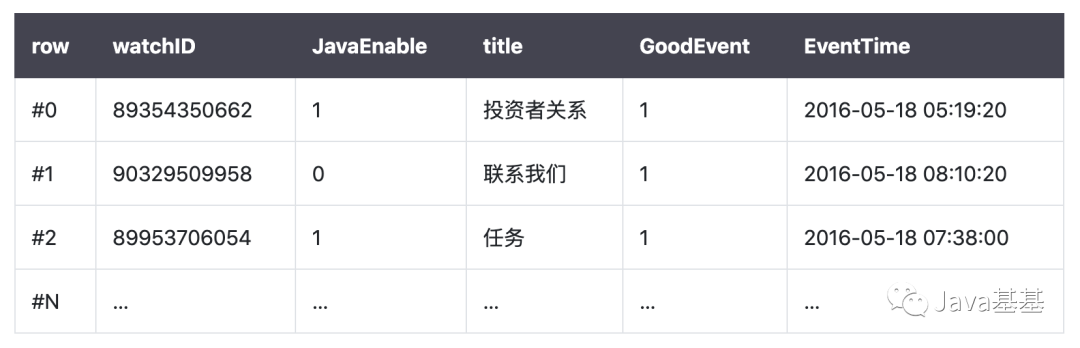
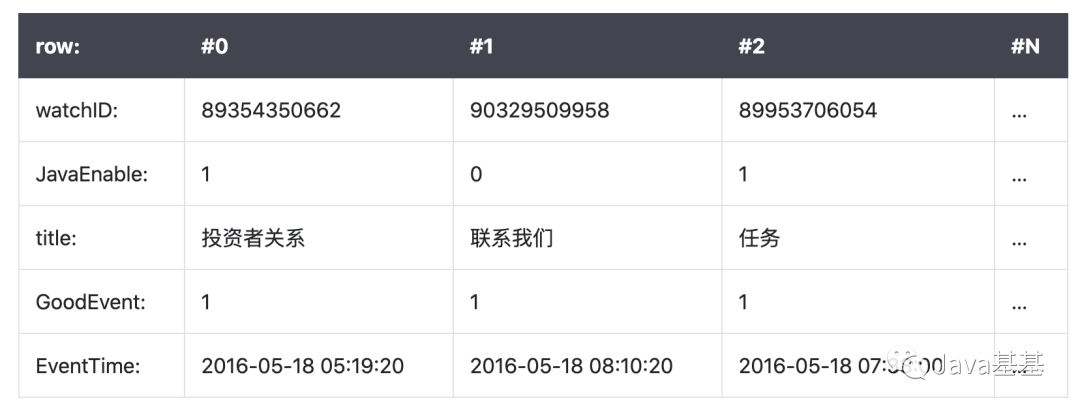
ClickHouse:是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
OLTP:
是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统
OLAP:
是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果
二、业务问题
三、ClickHouse实践
1.Mac下的Clickhouse安装
2.数据迁移:从Mysql到ClickHouse
create table engin mysql,映射方案数据还是在Mysql insert into select from,先建表,在导入 create table as select from,建表同时导入 csv离线导入 streamsets
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = Mergetree AS SELECT * FROM mysql('host:port', 'db', 'database', 'user', 'password')
3.性能测试对比

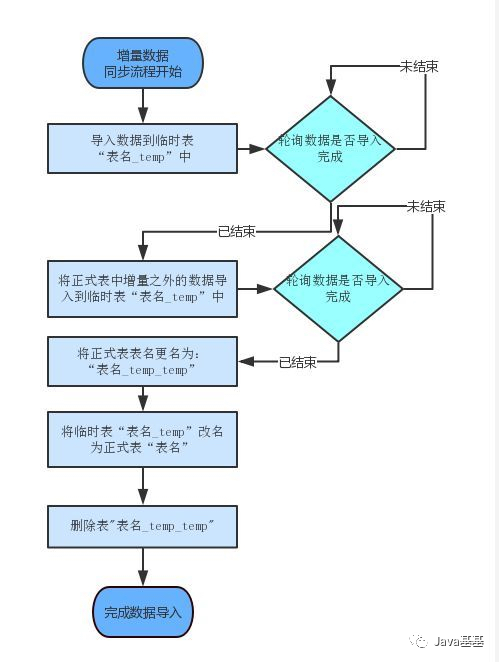
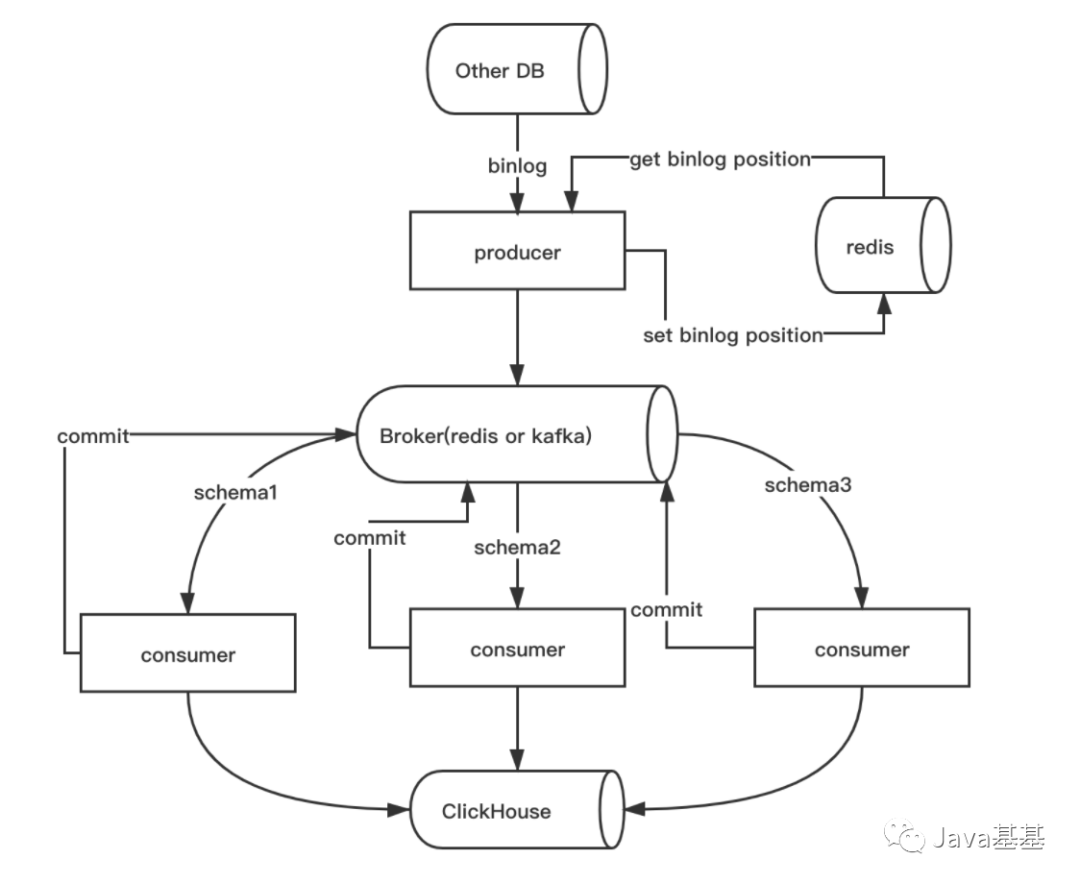
4.数据同步方案
5.ClickHouse为什么快?
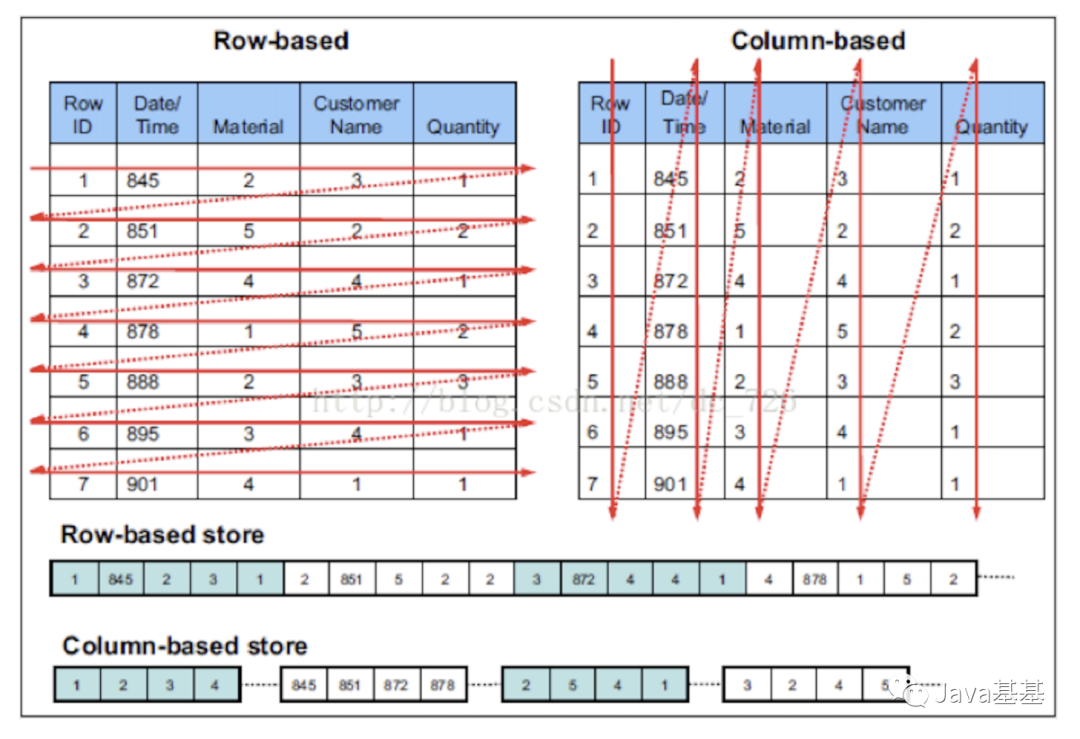
只需要读取要计算的列数据,而非行式的整行数据读取,降低IO cost 同列同类型,有十倍压缩提升,进一步降低IO clickhouse根据不同存储场景,做个性化搜索算法
四、遇到的坑
1.ClickHouse与mysql数据类型差异性

2.删除或更新是异步执行,只保证最终一致性

五、总结
推荐阅读:
微信扫描二维码,关注我的公众号
朕已阅 
评论