
如何从零开始实现全文搜索引擎?
【公众号回复 “1024”,免费领取程序员赚钱实操经验】

大家好,我是你们的章鱼猫。今天推荐的是一篇优秀博文的翻译,原文地址:https://artem.krylysov.com/blog/2020/07/28/lets-build-a-full-text-search-engine/
全文搜索(Full-Text Search)是一个大家每天都会使用的工具,但是只有少部分人真正理解其背后的原理。如果你曾经使用 Google 搜索过,类似“Golang 覆盖率报告”或者在某些电子商务网站搜索“室内无线摄像头”,意味着你都使用过全文搜索。
全文搜索(英文简写 FTS)是一项在一系列文档中搜索文本的技术。文档可以是网页、报刊文章、Email 邮件或者任何结构化的文本。
今天我们要从零开始构建一个 FTS 搜索引擎。当你看完这篇博文,你将会了解如何在 1 毫秒延时的情况下搜索百万级的文档。“给我搜索出所有包含 cat 单词的文档”,我们会从以上一个简单的搜索词开始逐步去扩展我们的搜索引擎,甚至去支持更为复杂的布尔查询功能。
提示:众所周知的全文搜索引擎是 Lucene,而比较知名的工具 Elasticsearch 和 Solr 都是在 Lucene 基础上构建的。
为什么是全文搜索?
在我们开始写代码之前,你肯定会问为什么不直接使用 grep 工具,或者通过顺序的方式逐步去对每个文档进行遍历?我们当然可以这样干,但是这并不是一个好的解决方案。
搜索语料
我们使用的搜索语料文档是英文 Wikipedia 的部分文档,可以通过网站 dumps.wikimedia.org 下载。目前解压后的文档大小是 913MB,里面包含了超过 60 万的 XML 文件。示例如下:
Wikipedia: Kit-Cat Klock https://en.wikipedia.org/wiki/Kit-Cat_Klock The Kit-Cat Klock is an art deco novelty wall clock shaped like a grinning cat with cartoon eyes that swivel in time with its pendulum tail.
加载文档
首先我们需要将所有的文档进行加载,而 Go 内建的 encoding/xml 包就非常的好用,以下是代码实现:
import (
"encoding/xml"
"os"
)
type document struct {
Title string `xml:"title"`
URL string `xml:"url"`
Text string `xml:"abstract"`
ID int
}
func loadDocuments(path string) ([]document, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
defer f.Close()
dec := xml.NewDecoder(f)
dump := struct {
Documents []document `xml:"doc"`
}{}
if err := dec.Decode(&dump); err != nil {
return nil, err
}
docs := dump.Documents
for i := range docs {
docs[i].ID = i
}
return docs, nil
}每一个加载后的文档都会分配一个唯一的 ID 标识。为了保持简单,第一个被加载的文档分配的 ID=0,第二个 ID=1,以此类推。
第一次尝试
搜索内容
现在我们已经将所有的文档加载到内存,那就可以开始尝试用最简单的方法去搜索包含 cat 的文档了。我们通过一个循环判断每一篇文档是否包含 cat:
func search(docs []document, term string) []document {
var r []document
for _, doc := range docs {
if strings.Contains(doc.Text, term) {
r = append(r, doc)
}
}
return r
}在我的笔记本电脑上,搜索耗时是 103ms,不算太差。如果你稍微仔细看一下搜索出来的结果的话,你会发现结构里面包含了一些 caterpillar 、 category 等匹配,而且并没有搜索到包含大写 Cat 的文档。以上并不是我想要的搜索行为。
接下来我们将修复以上的两个问题:
使得搜索引擎能够感知字母大小写
匹配完整的单词,而不是某个单词的一部分
使用正则表达式搜索
一种快速解决上述问题的解决方案是使用正则表达式。
比如搜索 cat 的正则表达式是 (?i)\bcat\b
(?i) 意思是使得搜索对大小写不敏感
\b 匹配单次的边界(边界意思是单词的前后是非字母)
func search(docs []document, term string) []document {
re := regexp.MustCompile(`(?i)\b` + term + `\b`) // Don't do this in production, it's a security risk. term needs to be sanitized.
var r []document
for _, doc := range docs {
if re.MatchString(doc.Text) {
r = append(r, doc)
}
}
return r
}糟糕的是,以上搜索耗时超过了 2 秒。正如你所看到的,在超过 60 万文档的情况下,搜索变得越来越慢,而简单的实现方案并不能拥有好的扩展性。随着数据集的不断扩大,我们将搜索越来越多的文档,而上述我们实现的算法的时间复杂度是 O(n) 的,意味着时间是和文档数成正比的。如果我们有 600 万文档要搜索的话,耗时会超过 20 秒,肯定是无法忍受的。
倒排索引
为了使搜索变得更快,我们需要提前做一些预处理并建立相应的索引加速搜索。
而这正是全文搜索(FTS)的核心数据机构,我们称之为倒排索引(Inverted Index,也有叫反向索引的)。默认我们知道一篇文档包含了哪些词,而倒排索引将建立词和文档的对应关系。示例如下:
documents = {
1: "a donut on a glass plate",
2: "only the donut",
3: "listen to the drum machine",
}
index = {
"a": [1],
"donut": [1, 2],
"on": [1],
"glass": [1],
"plate": [1],
"only": [2],
"the": [2, 3],
"listen": [3],
"to": [3],
"drum": [3],
"machine": [3],
}以下是一个真实世界的倒排索引,一本书的附录包含了词出现的所有页码。

文本分析
在我们开始建立索引之前,我们需要将文档中的词进行切分,方便后续的索引和查询。
一个文本分析器包含了一个分词器和多个过滤器。
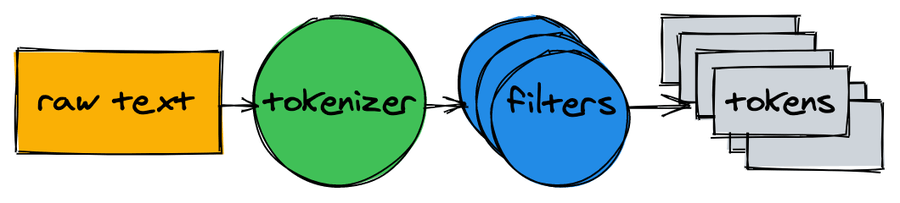
分词器
分词器是文本分析的第一步,它的任务是将文档切分为一系列的词。我们的实现是简单的将文本通过单词边界进行切分,同时移除相应的标点。
func tokenize(text string) []string {
return strings.FieldsFunc(text, func(r rune) bool {
// Split on any character that is not a letter or a number.
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
})
}
> tokenize("A donut on a glass plate. Only the donuts.")
["A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"]过滤器
在很多场景下,只是将文本进行切分并不够。为了使得后续的索引和查询更容易,我们需要做额外的标准化。
将单词统一小写
为了使得搜索对字母大小写不敏感,我们将所有词统一转化为小写。比如 cAt、Cat、caT 将统一转化为小写的 cat。当我们搜索的时候,我们也会把搜索词转化为小写的。
func lowercaseFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = strings.ToLower(token)
}
return r
}
> lowercaseFilter([]string{"A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"})
["a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"]去除通用词
任何英文文档中都包含了一些通用的词,比如 a、I、the、be。而这些词另外一个称呼是停用词。我们会将这些词删除不进行索引,因为任何的文档中都包含这些词,搜索这些词并没有任何意义。
但是并没有一个官方的停用词列表,我们将移除 OEC Rank 中排序前十的停用词,当然你也可以增加更多。
var stopwords = map[string]struct{}{ // I wish Go had built-in sets.
"a": {}, "and": {}, "be": {}, "have": {}, "i": {},
"in": {}, "of": {}, "that": {}, "the": {}, "to": {},
}
func stopwordFilter(tokens []string) []string {
r := make([]string, 0, len(tokens))
for _, token := range tokens {
if _, ok := stopwords[token]; !ok {
r = append(r, token)
}
}
return r
}
> stopwordFilter([]string{"a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"})
["donut", "on", "glass", "plate", "only", "donuts"]词干提取
因为英语中语法的不同,文档中可能包含同一个词的不同表现形式,而词干提取就是为了将这些词转化为词干。比如fishing、fished 、 fisher 都会转化为基础词干 fish。
实现一个词干提取器并没有那么容易,而这并不是本文的重点,所以我们使用了一个现成的开源模块。
import snowballeng "github.com/kljensen/snowball/english"
func stemmerFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = snowballeng.Stem(token, false)
}
return r
}
> stemmerFilter([]string{"donut", "on", "glass", "plate", "only", "donuts"})
["donut", "on", "glass", "plate", "only", "donut"]提示:词干有时候并不是一个有效的词,比如 airline 会转化成 airlin。
将所有的文本分析器进行集成
func analyze(text string) []string {
tokens := tokenize(text)
tokens = lowercaseFilter(tokens)
tokens = stopwordFilter(tokens)
tokens = stemmerFilter(tokens)
return tokens
}分词器和过滤器将文档转化为词的列表。
> analyze("A donut on a glass plate. Only the donuts.")
["donut", "on", "glass", "plate", "only", "donut"]现在以上词就可以开始索引了。
构建索引
回到倒排索引,它将词与其出现的文档列表进行关联。而 Go 内建的 map 就是一个很好的候选数据结构,键值 key 存储词,值 value 储存文档 ID 列表。
type index map[string][]int构建索引的步骤就是逐步的分析文档,并将文档 ID 增加到 map 映射中。
func (idx index) add(docs []document) {
for _, doc := range docs {
for _, token := range analyze(doc.Text) {
ids := idx[token]
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(ids, doc.ID)
}
}
}
func main() {
idx := make(index)
idx.add([]document{{ID: 1, Text: "A donut on a glass plate. Only the donuts."}})
idx.add([]document{{ID: 2, Text: "donut is a donut"}})
fmt.Println(idx)
}我们成功了,以上代码将词和文档列表进行了关联。
map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]]查询
要利用上述构建的倒排索引,我们需要对查询词也进行一致的文本分析(分词器和过滤器)。
func (idx index) search(text string) [][]int {
var r [][]int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
r = append(r, ids)
}
}
return r
}
> idx.search("Small wild cat")
[[24, 173, 303, ...], [98, 173, 765, ...], [[24, 51, 173, ...]]最后,我们可以从 60 万文档中搜索所有出现 cat 的文档,而耗时少于 1 毫秒(18 微妙)。
当我们利用倒排索引,搜索算法的时间复杂度是和搜索词的数量相当,这意味着算法时间复杂度是 O(1),并不会随着文档数量的增加而增加。
布尔查询
在前一部分我们的介绍中搜索的返回是每一个词的文档列表,并没有做相关的聚合。而我们期望的是能够搜索到同时包含 small、 wild 和 cat 的文档。下一步我们将会对以上文档列表进行聚合归并,这样就能得到包含所有词的文档列表。

幸运的是,我们的倒排索引的文档列表是升序的。这样我们去计算两个列表的相同元素的算法时间复杂度是线性的。
func intersection(a []int, b []int) []int {
maxLen := len(a)
if len(b) > maxLen {
maxLen = len(b)
}
r := make([]int, 0, maxLen)
var i, j int
for i < len(a) && j < len(b) {
if a[i] < b[j] {
i++
} else if a[i] > b[j] {
j++
} else {
r = append(r, a[i])
i++
j++
}
}
return r
}我们再将搜索结果聚合代码与之前的进行整合。
func (idx index) search(text string) []int {
var r []int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
if r == nil {
r = ids
} else {
r = intersection(r, ids)
}
} else {
// Token doesn't exist.
return nil
}
}
return r
}Wikipedia 的文档中最后只有两篇文档同时包含了 small、wild 和 cat。
> idx.search("Small wild cat")
130764 The wildcat is a species complex comprising two small wild cat species, the European wildcat (Felis silvestris) and the African wildcat (F. lybica).
131692 Catopuma is a genus containing two Asian small wild cat species, the Asian golden cat (C. temminckii) and the bay cat.
搜索结果是我们所期望的。同时,通过搜索结果我们也是第一次听说 catopuma(金猫), 以下图片就是。

总结
我们仅仅是实现了一个简单的全文搜索引擎,尽管它很简单,但是你依然可以基于此建立更多复杂的项目。
同时我们也没有过多的去介绍如何提高性能,以及使搜索引擎对用户使用更加的友好。以下是一些后续优化的方向仅供参考:
扩展布尔查询支持 OR 和 NOT
将倒排索引存储在磁盘
每次都重建索引会耗费一些时间
大的索引可能不能在内存全部存储
尝试去使用内存和 CPU 高效的索引数据存储方式,可以了解一下 Roaring Bitmaps
根据相关性对搜索结果进行排序
以上所有代码都可以从 GitHub 上获取到:
项目地址:https://github.com/akrylysov/simplefts
---特别推荐---
特别推荐:一个新的优质的推荐高效工具,软件,插件的公众号,每天给大家分享优秀的效率工具,「程序员掘金」,专门为程序员挖掘好东西的一个公众号,非常值得大家关注。