
Datapane 009 - API 参考手册
报告
在本机,在Datapane 托管服务器,创建、分享报告。
创建报告对象
报告对象由一系列组件组成。所有支持组件的完整内容请参阅参考手册的相关页面。
# 创建报告
import datapane as dp
# 创建 Markdown 组件
markdown = dp.Markdown("# My report")
# 创建报告对象
report = dp.Report(markdown)
保存报告
报告可以保存为本机 HTML 文件,使用的参数是 path。
report.save(path='file.html')
发布报告
登陆到 Datapane 虚拟机后,可以在线发布报告。name 参数是所有报告的必选参数 。open 参数设置设置为 True 时,将自动打开报告的 URL。如果没有登陆,这个方法会失败。
report.publish(name='my_report', open=True)
发布报告操作的标准输出是 URL,同时还会返回报告对象。
预览报告
在 Jupyter Notebook 里,可以预览内联式报告。
report.preview()
这项操作把本机文件当做 iframe 嵌入到 Notebook 对话里。
API - 报告 - 组件
所有可用于开发与布局的报告组件。
概览
组件用于创建报告。组件与 pandas 的 DataFrame、可视图、Markdown 等 Python 对象兼容。我们还在不断添加新的组件,如果您想在报告里添加新的组件,请在Github 上提交 issue。
可视图
可视图组件支持可视图对象,并在报告里渲染可视图。
目前,Datapane 支持以下可视化支持库:
Matplotlib 与 Seaborn
Plotly
Bokeh
Altair
Folium
文件与图片
Altair
Altair 是基于 Vega 与 Vega-Light 的声明式 Python 统计可视图支持库。Altair 的 API 基于强大的 Vega-Light 语法,简单、友好、一致性强。这种优雅、简洁的特性,使得 Altair 只需最少的代码,即可生成美观、高效的可视图。
使用 Altair 生成可视图,请参阅 Altair 的文档。
import altair as alt
import datapane as dp
from vega_datasets import data as vega_data
gap = pd.read_json(vega_data.gapminder.url)
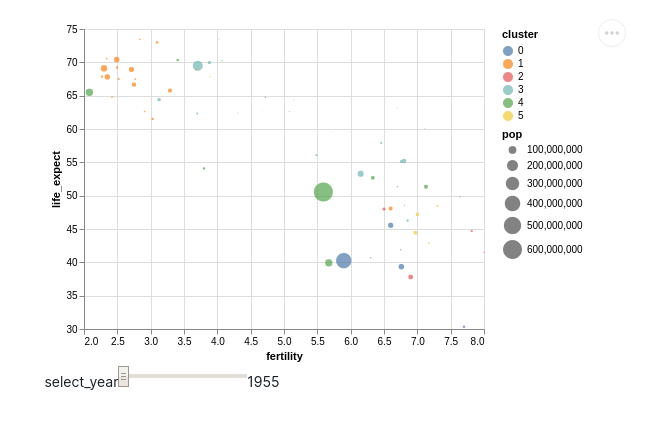
select_year = alt.selection_single(
name='select', fields=['year'], init={'year': 1955},
bind=alt.binding_range(min=1955, max=2005, step=5)
)
alt_chart = alt.Chart(gap).mark_point(filled=True).encode(
alt.X('fertility', scale=alt.Scale(zero=False)),
alt.Y('life_expect', scale=alt.Scale(zero=False)),
alt.Size('pop:Q'),
alt.Color('cluster:N'),
alt.Order('pop:Q', sort='descending'),
).add_selection(select_year).transform_filter(select_year)
dp.Report(dp.Plot(alt_chart)).publish(name='time_interval')
Bokeh
Bokeh 是一个交互式可视化支持库,它的图形优雅、简洁,可创建多种多样的图形,并且它为实现大型数据集的高效交互下了很大功夫。
使用 Bokeh 生成可视图,请参阅 Bokeh 的用户文档.
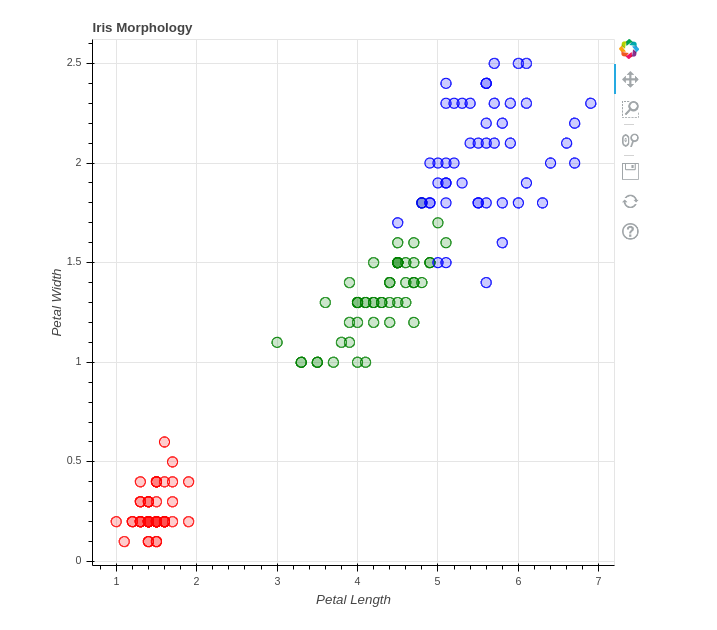
from bokeh.plotting import figure, output_file, show
from bokeh.sampledata.iris import flowers
import datapane as dp
# 用 Bokeh 创建散点图
colormap = {'setosa': 'red', 'versicolor': 'green', 'virginica': 'blue'}
colors = [colormap[x] for x in flowers['species']]
bohek_chart = figure(title = "Iris Morphology")
bokeh_chart.xaxis.axis_label = 'Petal Length'
bokeh_chart.yaxis.axis_label = 'Petal Width'
bokeh_chart.circle(flowers["petal_length"], flowers["petal_width"],
color=colors, fill_alpha=0.2, size=10)
output_file("iris.html", title="iris.py example")
# 查看可视图
dp.Report(dp.Plot(bokeh_chart)).preview()
# 发布报告
dp.Report(dp.Plot(bokeh_chart)).publish(name='bokeh_plot')
Plotly
Plotly 的 Python 图形支持库 可生成交互式、印刷质量的图形。
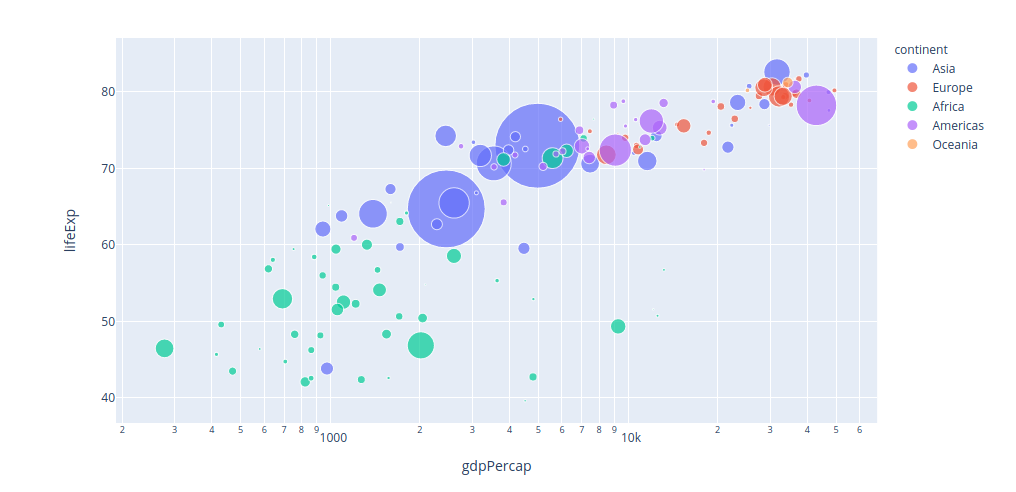
import plotly.express as px
import datapane as dp
df = px.data.gapminder()
plotly_chart = px.scatter(df.query("year==2007"), x="gdpPercap", y="lifeExp",
size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
plotly_chart.show()
dp.Report(dp.Plot(plotly_chart)).publish(name='bubble')
Folium
[Folium] 可在 Python 中轻易实现数据可视化,生成 Leaflet 地图。它可以把数据以分级统计 的形式与地图绑定在一起,还可以在地图上显示多种矢量、光栅、HTML 可视图标记。
该支持库内置一批从 OpenStreet、Mapbox、Stamen 引用的 tileset,还支持调用 Mapbox 或 Cloudmade 的 API 密钥自定义 tileset。
import folium
import datapane as dp
m = folium.Map(location=[45.5236, -122.6750])
dp.Report(dp.Plot(m)).publish(name='folium_map')

Markdown
Markdown 是一款轻量级标记语言,用于在报告中嵌入文本。
import datapane as dp
dp.Report(dp.Markdown("My awesome markdown"))
要嵌入多行语句和带格式的文字,请使用 “”“这里是文字”“”。
import datapane as dp
report = dp.Report(dp.Markdown( "# Altair"),
dp.Plot(alt_chart),
dp.Markdown("""
* There is a negative relation between life expectanty and fertility
* The number of population with high life expactancy increases as time increase
""")
report.publish(name = 'results')

点击这里了解如何使用 Markdown 格式化文本。
代码
参照下例,用 dp.Markdown 分享代码。
code = dp.Markdown(f'''
df = data.reset_index().melt('Date', var_name='symbol', value_name='price')
base_chart = alt.Chart(df).encode(x='Date:T', y='price:Q', color='symbol').interactive()
chart = base_chart.mark_line() if plot_type == 'line' else base_chart.mark_bar()''')
dp.Report(code).publish(name='report_with_code')
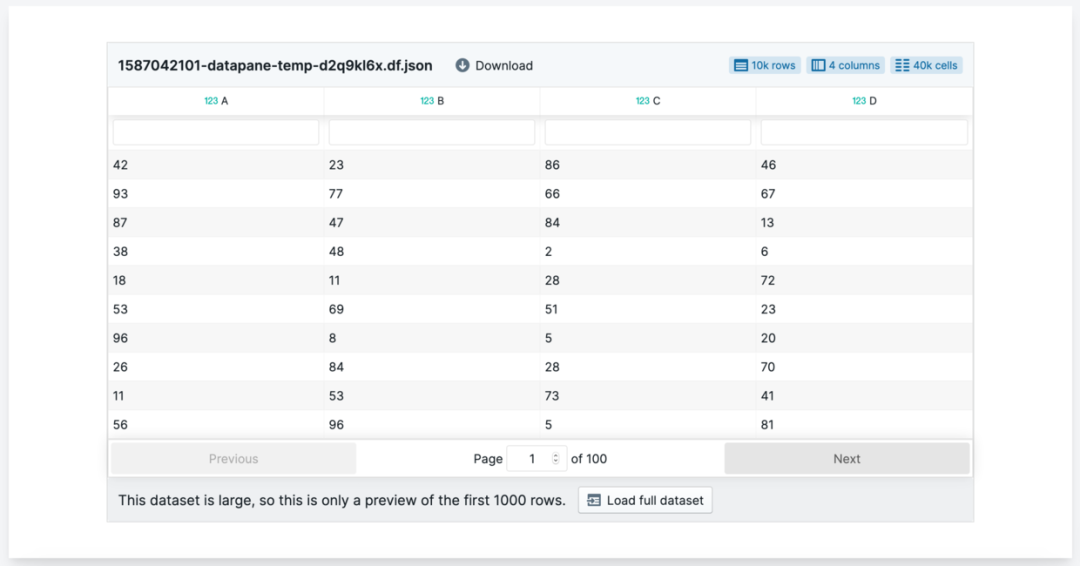
表格
表格组件使用 pandas 的 DataFrame,并可在 Datapane 报告里渲染支持交互、排序、搜索的表格。用户还可以从网页下载表格。一般情况下,表格组件可以渲染 200至 300 万个单元格,而且不会性能不足的问题。
默认情况下,表格组件只显示前 1000 行数据。修改设置选项,可以显示完整数据集。
import datapane as dp
import pandas as pd
df = pd.DataFrame({
'A': np.random.normal(-1, 1, 5000),
'B': np.random.normal(1, 2, 5000),
})
table = dp.Table(df)
report = dp.Report(table)
report.publish(name='sample_table')
文件与图片
Datapane 还支持分享文件与图片。比如,调用 dp.file 就可以分享图片。
dp.File(file=dp.Path('./image.png'))
图片会自动显示在 Datapane 报告里!
查询组件
概览
报告里通常会包含多种组件,但可能只需要嵌入或分享其中某些内容。不必创建包含每种组件的报告,只要指定报告 URL(blocksquery)的查询条件,就可以提取相关组件。
这里使用 XPath 实现查询报告的内容。除下列查询示例之外,还可以使用任何有效的 XPath 查询条件。
组件类型
在链接中指定以下四种组件类型,即可访问对不同组件:
Table:提取 DataFramePlot:提取可视图Text:提取 Markdown 文本File:提取文件或图片
查询特定的组件类型
假设报告中使用了 Markdown 文本与可视图组件。如需分享报告里的可视图,只需在报告链接的末尾添加 /?blocksquery=//Plot。
比如,要提取这个报告中的可视图:
https://datapane.com/ryancahildebrandt/reports/movies_dashboard_3496f91c/
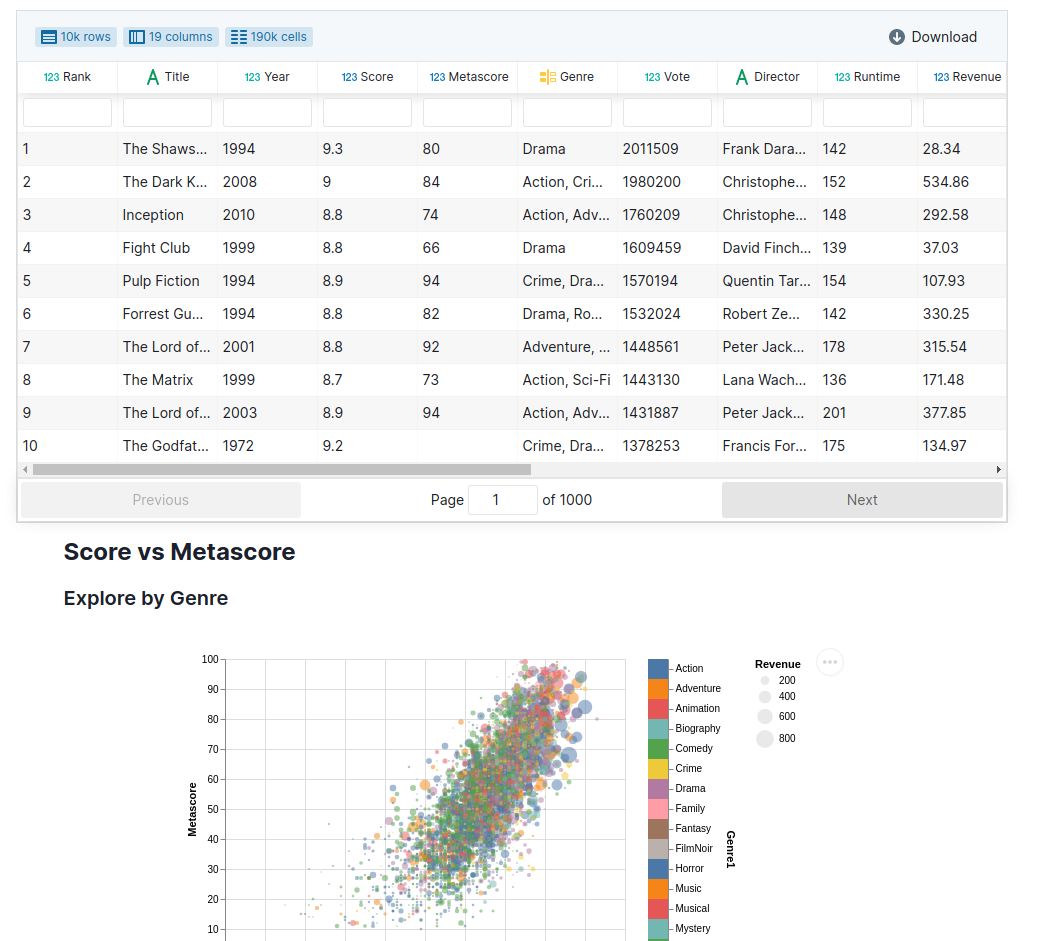
只需要在链接末尾添加 /?blocksquery=//Plot:
https://datapane.com/ryancahildebrandt/reports/movies_dashboard_3496f91c/embed/?blocksquery=//Plot
只显示可视图组件:
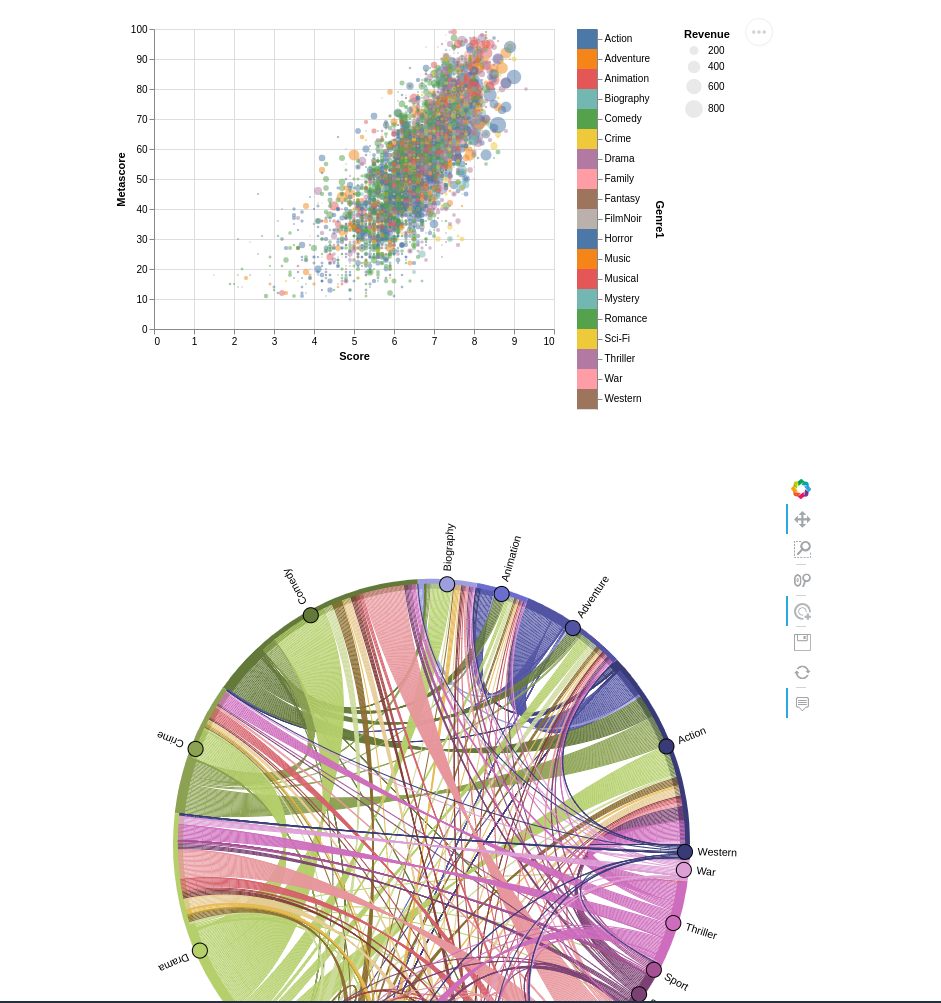
访问指定组件
假如只想显示报告里的第一张可视图,只要在链接末尾添加 /?blocksquery=//Plot[1]。比如,这个链接就只显示第一张可视图。
https://datapane.com/ryancahildebrandt/reports/movies_dashboard_3496f91c/embed/?blocksquery=//Plot[1]
下面这个链接显示第二张可视图。https://datapane.com/ryancahildebrandt/reports/movies_dashboard_3496f91c/embed/?blocksquery=//Plot[2]
脚本 - 配置
配置 Datapane 的 Python 脚本
在 datapane.yaml 文件里,可以设置下列选项:
script
值
相对路径。
说明
Python 脚本或 Jupyter Notebook 的路径,是脚本的基础内容。默认为 dp_script.py。
name
值
字符串(支持的字符串为 [a-z0-9_])
说明
脚本的名称,显示在网页界面上。
部署多个同名的脚本将自动递增生成不同版本。
pre_commands
值
bash 命令列表。
说明
脚本执行前运行的 bash 命令列表。该项操作常用于部署时安装 include 项下的本机文件夹中的 pip 依赖项,或从 git 提取数据。
include
值
文件或文件夹的相对路径列表。
说明
脚本中包含的本机文件或文件夹。脚本运行时,这些内容在当前工作文件夹生效,因此可用于上传本地支持库、源文件、SQL 脚本等。
对于大型文件与二进制对象,建议使用 Blob API。
exclude
值
文件或文件夹的相对路径列表。
说明
部署时明确要排除的文件(在 include 中指定的文件或文件夹除外)。
parameters
值
对象列表。
说明
转换为网页表单并在运行时传递给代码的参数列表。由对象列表组成,如下:
parameters:
- name: my_param
type: string
default: foo
requirements
值
与 pip 兼容的安装包列表
说明
脚本运行前需要安装的支持库列表。与平时在 requirements.txt 文件里的内容一样。
每次脚本运行时,都会安装这些参数,因此,如果这里的参数很多,在执行脚本时会产生延迟。如需不断复用同样的参数,或使用更复杂的需求项,建议在 Docker 镜像中添加需求项,并指定
container_image_name。
container_image_name
值
Docker URL
说明
运行脚本的公开 Docker 镜像。关于创建镜像的说明,请参阅下列教程。
支持库与依赖项
repo
值
URL
说明
GitHub 库或文件的链接。这里的内容在网页界面以引用的形式显示,不影响代码执行。
Blob 对象
Blob 对象是可以存储到 Datapane 或在脚本中使用的文件和对象。
生成报告经常需要数据集、模型、文件等非代码类的资源。很多情况下,和脚本一起部署这些资源并不是什么好主意。
部署节奏与脚本不同。例如,模型每日都要进行训练,但脚本代码却是静态不变的。
部署环境与脚本不同。例如,要在脚本中使用在 Segemaker 上训练的模型。
Blob 对象一般很大,每次部署时重新上传都麻烦。
对于这些用例,Datapane 提供了 Blob API,可以从任何 Python 或 CLI 环境上传文件,并在脚本内部或通过 CLI 访问这些对象。
CLI
上传 upload
上传文件,并返回提取 Blob 对象的 id 和 URL。
datapane blob upload
下载 download
下载 Blob 对象,并保存为文件。
datapane blob download [--version=version]
Python
上传 DataFrame、文件、对象 `upload_df,upload_file,upload_obj`
参数
所有上传方法的第一个参数都是要上传的对象。针对以上三种方法,该参数可以是 DataFrame、文件路径、Python 对象。
上述三种方法都支持以下参数:
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | 变量的值 | 是 |
version | 可见权限设置(ORG、PRIVATE、PUBLIC) | 否 |
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | 变量的值 | 是 |
version | 可见权限设置(ORG、PRIVATE、PUBLIC) | 否 |
团队其他成员在他们的脚本里调用您创建的 Blob 对象时,必须将该对象的可见权限设置为
ORG
import datapane as dp
# 上传 DataFrame
b = dp.Blob.upload_df(df, name='my_df')
# 上传文件
b = dp.Blob.upload_file("~/my_dataset.csv", name='my_ds')
# 上传对象
b = dp.Blob.upload_obj([1,2,3], name='my_list')
下载文件、DataFrame、对象 `download_df、download_file、download_obj`
下载 DataFrame、文件、对象。所有下载操作都需要以下参数:
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | Blob 对象的名称 | 是 |
version | Blob 对象的版本 | 否 |
owner | Blob 对象的所有权人 | 否 |
团队其他成员要运行您的脚本,访问您创建的 Blob 对象,则必须在此方法中指定您自己作为
owner。他人运行您的脚本时,是以他们的账户名运行的,如果没有明确地指定owner, 脚本会在他们名下查找 Blob 对象,这将导致运行失败。dp.Blob.get(name='foo', owner='linus')
import datapane as dp
# 下载 DataFrame
blob = dp.Blob.get(name="blob_id")
# 下载 DataFrame
b = blob.download_df()
# 下载文件
b = blob.download_file("~/my_dataset.csv")
# 下载对象
b = blob.download_obj()
分享 Blob 对象
有时要把 Blob 对象分享给团队其他成员,以便整个团队使用同一个 DataFrame、对象、文件开展工作。
向外部公众分享 Blob 对象,在上传 DataFrame、文件、对象时,要将可见权限设置为 visibility=PUBLIC。
dp.Blob.upload_df(df, name='myblob', visibility='PUBLIC')
他人想访问您的 Blob 对象时,只需指定的 Blob 对象的名称,并在 owner 参数中注明您的账户名即可。
blob = dp.Blob.get(name='myblob', owner='khuyentran')
# 提取 Blob 对象
b = blob.download_df() # 或 download_file(),download_obj()
现在,他们就可以在自己的代码中使用您的 Blob 对象了!在团队内部分享 Blob 对象,也可以用相同流程,但要把 Blob 对象的可见权限设置为 ORG。
变量
变量是可在不同脚本之间共享,且经过加密的私密值。
概览
脚本里通常都含有数据库密钥、密码等变量,这些变量不宜嵌入源代码,也不宜让外界公众看到。Datapane 的 Variable 对象提供了一种安全的方式,用于创建、存储、提取脚本所需的值。
添加变量 `add`
参数
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | 变量名 | 是 |
value | 变量值 | 是 |
visibility | 可见权限设置(ORG、PRIVATE、PUBLIC) | 否 |
返回对象
变量对象
说明与示例
创建新的用户变量。变量名相同,但变量值不同时,此命令将创建新版本的变量。
默认情况下,变量是创建者账户私有的内容,但也能在团队内部分享。可以设置可见权限,把 --visibility 标签(或 Python 里的 visibility 项)设置为 OWNER_ONLY 或 ORG。
团队其他成员运行您发布的脚本时,要把变量的可见权限设置为
ORG, 这样才能在他们的账户下运行您的脚本。
# CLI
~/> datapane variable add
Created variable:
# Python
import datapane as dp
v = dp.Variable.add(name, value, visibility='ORG')
列出变量 `list`
参数
无
返回对象
变量名与变量版本的列表
说明与示例
# CLI
~/> datapane variable list
Available Variables:
name versions
-- ------ ----------
0 foo 1
提取变量 `get`
参数
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | 变量名 | 是 |
version | 提取的变量版本 | 否 |
owner | 变量的所有者。默认为运行脚本的人。因此,如需他人运行您创建的变量,要显式设置可见权限 | 否 |
返回对象
单个变量对象
说明与示例
默认情况下,get 提取变量的最新版本。
如需团队其他成员运行脚本时调用您创建的变量,在本方法中,必须指定您自己为
owner。他人运行您的脚本时,该脚本在他们自己的账户名下运行,如果没有明确地指定owner,Datapane 将在他们的账户名下查找变量,这将导致程序运行失败。foo = dp.Variable.get(name='foo', owner='linus')
# CLI
~/> datapane variable get foo
Available Variable:
name value visibility
-- ------- ------- ------------
0 foo bar OWNER_ONLY
# Python
import datapane as dp
v = dp.Variable.get(name='foo')
提取值
用以下命令提取存在 foo 里的值:
foo_value = foo.value
删除变量 `delete`
参数
| 参数 | 说明 | 是否必选 |
|---|---|---|
name | 变量名 | 是 |
返回对象
无
说明与示例
# CLI
~/> datapane variable delete foo
Deleted variable foo