
元数据存储系统管理演变升级
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


 前言
前言我们知道在一个存储系统中,不光光只有它所存储的数据文件重要,它的存储系统的元数据管理同样十分的重要。因为涉及到存储系统数据访问操作时,会经过存储系统元数据的查询或更新操作,如果元数据这边的操作出现性能瓶颈,同样会导致用户访问数据的行为出现缓慢的情况。本文我们来聊聊存储系统一般是如何做高效的元数据管理的,这里面会涉及到多种不同的元数据管理方式。
初代元数据管理首先我们来看最简单原始的初代存储系统元数据管理方式,此时元数据往往存储于外部db中,然后master服务和db进行数据的交互,如下图所示:
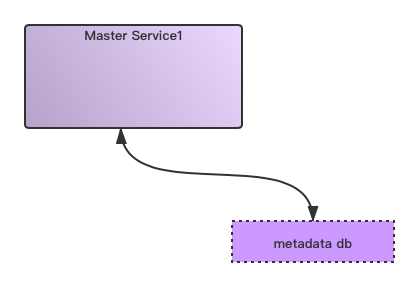 这个版本的存储系统需要保证的是操作流程的流畅性处理,与此同时整个系统所维护的元数据体量也不是很大。
这个版本的存储系统需要保证的是操作流程的流畅性处理,与此同时整个系统所维护的元数据体量也不是很大。内存式元数据管理当我们需要对元数据的访问操作有更高的要求时,我们会自然想到的一种做法是将元数据load到服务内存中,来加速元数据的访问。然后我们会看到如下内存管理式的元数据管理,master服务在初启动后加载外部元数据db文件到内存中。
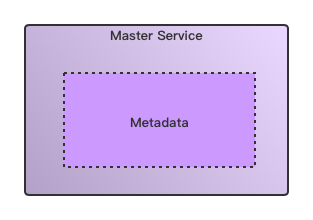 分区元数据管理一台机器的内存容量是有限的,但是元数据规模是可以随着业务不断扩张的,这时就会出现一个内存的bottleneck的问题。这个时候怎么来优化这个事情呢?答案很简单,一个字:拆!我们将元数据按照给定规则进行partition的分拆,然后启动多个master服务来管理各自的应该维护的元数据,效果图如下所示:
分区元数据管理一台机器的内存容量是有限的,但是元数据规模是可以随着业务不断扩张的,这时就会出现一个内存的bottleneck的问题。这个时候怎么来优化这个事情呢?答案很简单,一个字:拆!我们将元数据按照给定规则进行partition的分拆,然后启动多个master服务来管理各自的应该维护的元数据,效果图如下所示: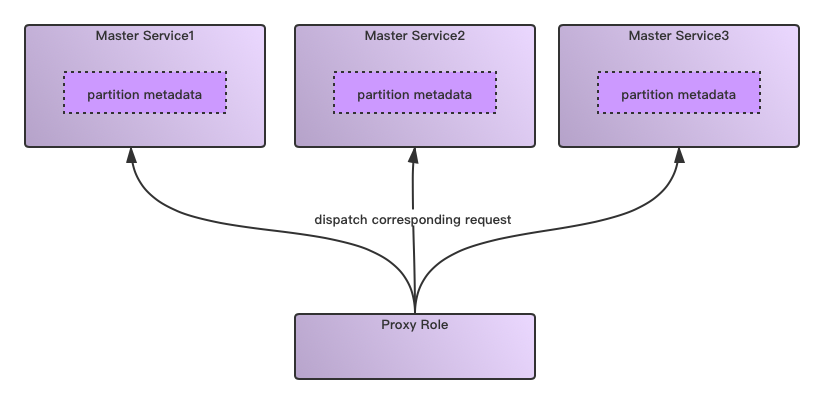 因为在这里实际服务的service变为了多个,对于属于不同partition的元数据操作,系统应让请求转发到对应所属的服务上面去,因此在service前面还需要一个Proxy Role这样的角色在请求的转发。这个设计一个比较典型的例子是HDFS的Federation方案,然后Proxy Role是client端的ViewFs,或者是HDFS RBF功能的Router角色。
因为在这里实际服务的service变为了多个,对于属于不同partition的元数据操作,系统应让请求转发到对应所属的服务上面去,因此在service前面还需要一个Proxy Role这样的角色在请求的转发。这个设计一个比较典型的例子是HDFS的Federation方案,然后Proxy Role是client端的ViewFs,或者是HDFS RBF功能的Router角色。分层级元数据管理当元数据管理再进一步加大的时候,我们还能如何拓展单个节点元数据管理能力的极限呢?比如从支持百万级别量级文件到数十亿级别体量文件。将数十亿级别量级文件元数据全部load到机器内存已经是一件不太靠谱的做法了。这个时候我们有一种新的元数据管理系统模式:分层级的元数据管理,官方术语的称呼叫做Tier layer的元数据管理。
这里主要分为两种layer:
最近访问的热点元数据,做内存缓存,叫做cached layer。
很久没有访问过的数据((也可称作冷数据),做持久化保存存,叫做persisted layer。
热点数据和冷数据根据用户的访问频率行为可以互相之间做转换,类似如下所示:
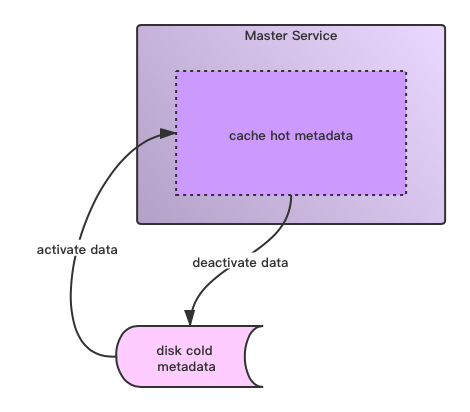 在此模式系统下,服务只cache当前active的数据,所以也就不会有内存瓶颈这样的问题。下图是一个此模式的样例系统Alluxio的元数据管理模型图:
在此模式系统下,服务只cache当前active的数据,所以也就不会有内存瓶颈这样的问题。下图是一个此模式的样例系统Alluxio的元数据管理模型图: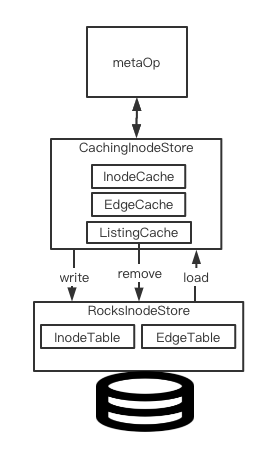 以上就是本文所要阐述的关于存储系统常见的元数据管理模式。
以上就是本文所要阐述的关于存储系统常见的元数据管理模式。文章不错?点个【在看】吧! ?
评论