
Tekton 压力测试及构建集群参数优化
1. 测试目的
调优构建集群的参数 探测 Tekton 并发流水线数量上限 给出单个集群最佳并发上限值
2. 相关组件及机器配置
Kubernetes 版本
v1.21.4
Tekton 版本
v0.24.1,与生产版本保持一致
OpenEBS 版本
localpv 3.3.0,与生产版本保持一致
集群节点配置,共五个节点,四个用于构建
node1 master,禁止调度 32C/125GB/4T SSD
node2 master,worker 40C/125GB/4T SSD
node3 master,worker 32C/125GB/4T SSD
node4 worker 40C/125GB/4T SSD
node5 worker 40C/125GB/4T SSD
3. 集群参数调优
测试的过程,其实也是不断调试各个组件参数的过程。因此整个测试过程中的参数是动态的,当我发现瓶颈时,就会去调整参数,然后再次执行测试用例。
3.1 kube-apiserver
--max-mutating-requests-inflight 调整为2000,默认值200
--max-requests-inflight 调整为 4000, 默认值为 400
放开组件的流量控制。
3.2 kube-controller-manager
--kube-api-qps 调整为 200,默认值为 20
--kube-api-burst 调整为 300,默认值为 30
放开组件的流量控制。
3.3 kube-scheduler-manager
percentageOfNodesToScore 节点少,无需调整。
通常需要保持 percentageOfNodesToScore * 总节点数 < 50
--kube-api-qps 调整为 500,默认值为 50
--kube-api-burst 调整为 1000,默认值为 100
放开组件的流量控制。
3.4 kubelet
–max-pods 调整为 1000,默认 110
节点数量少,配置高,单个节点的 Pod 密度会很大。
3.5 tekton controller
-kube-api-qps 调整为 200,默认值 5
-kube-api-burst 调整为 500,默认值 10
-threads-per-controller 调整为 100,默认值 2
Tekton Controller 采用单副本,多副本选主之后,还是单副本工作。多副本能提供更好的可用性,生产环境建议适当使用。
3.6 tekton webhook
副本上限调整为 20,默认值 5
kubectl -n tekton-pipelines edit hpa tekton-pipelines-webhook
webhook 主要用于校验提交的数据,足够的副本能缩短创建流水线接口校验数据的响应时间。
3.7 etcd
--quota-backend-bytes 调整为 8589934592 (8G),默认是 2G
放置 Pod、流水线太多,Etcd 存储不够。
3.8 docker
20.10.8 升级到 20.10.12
这个升级极其重要,因为构建时通常会挂载主机的 Docker socket,但是 Nodejs 类构建进行系统调用时会报错。错误信息如下:
[0m[91m 3: 0xb6fb7e [node]
[0m[91m 4: 0xb6fc46 node::NodePlatform::NodePlatform(int, v8::TracingController*) [node]
[0m[91m 5: 0xac7d64 node::InitializeOncePerProcess(int, char**, node::InitializationSettingsFlags, node::ProcessFlags::Flags) [node]
[0m[91m 6: 0xac8949 node::Start(int, char**) [node]
[0m[91m 7: 0x7f01da493d90 [/lib/x86_64-linux-gnu/libc.so.6]
8: 0x7f01da493e40 __libc_start_main [/lib/x86_64-linux-gnu/libc.so.6]
[0m[91m 9: 0xa3d03c [node]
[0m[91mAborted (core dumped)
此时,如果是运行容器,很简单加上 --security-opt seccomp=unconfined,但 docker build 不支持该参数。集群已经安装 20.10.8,只能将 20.10.12 版本的 docker、dockerd、docker-init、docker-proxy 拷贝覆盖旧版本,重启机器即可。
Docker 20.10.12 比较于 20.10.8 在安全上可能有较大调整。
4. 其他情况说明
开启了 Tekton Metrics 采集
获取 Tekton 内部的一些指标,运行数量等。
kube-state-metrics 开启了 label 、annotation 采集
很费资源,但能拿到很多元数据用于 Grafana 绘图。
开启以上采集方法,可以参考之前的文章。
5. 容量预估
CPU、内存资源
整个集群可用资源约为 152C 550GB,减去空载时,基础组件消耗,大约有 149C 535 GB。提前执行了一下测试流水线,CPU 约消耗几乎为 0,MEM 约消耗为 180 MB。
按此估算,集群能提供 535 * 1024/ 180 > 3000 >> 1000 条的流水线并发执行容量。
Pod 数量
Kubelet Pod 数量限制放开到 1000,总容量达到 4000 个 Pod
测试流水线,每条占用 4 个 Pod,一个 affinity-assistant + 三个 Pod (一共三个 Task)。
4000 个 Pod 减去系统组件之后不足,但 Pod 数量其实可以超过 Kubelet 的设置,因此也足以支撑 1000 条流水线并发执行。
6. 测试用例
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: testing-p
namespace: test
spec:
params:
tasks:
- name: echo-1
params:
- name: script
value: cnt1=1; while [[ $cnt1 -lt 60 ]]; do echo "1111111111"; sleep 1; cnt1=$(($cnt1+1)); done
taskRef:
kind: ClusterTask
name: script
- name: echo-2
params:
- name: script
value: cnt1=1; while [[ $cnt1 -lt 60 ]]; do echo "2222222222"; sleep 1; cnt1=$(($cnt1+1)); done
taskRef:
kind: ClusterTask
name: script
runAfter:
- echo-1
- name: echo-3
params:
- name: script
value: cnt1=1; while [[ $cnt1 -lt 60 ]]; do echo "3333333333"; sleep 1; cnt1=$(($cnt1+1)); done
taskRef:
kind: ClusterTask
name: script
runAfter:
- echo-2
这里选择这条流水线的原因在于:
生产环境的构建平均时长大约在 3m,通常 2-3 个 task 主要想测试的是 Tekton 及其基础设施的性能,为了提高集群的并发量,特地使用低功耗的流水线。否则加上外部依赖,场景会十分复杂,也不利于实验的重现。
7. 测试结果
7.1 并发-执行时长对照
| 并发数量 | 触发/执行成功率 | 平均执行时长 | 最短/最长执行时长 | Tekton Dashboard | 组件压力情况 |
|---|---|---|---|---|---|
| 1 | 100%/100% | 3m37s | 3m24s~3m53s | OK | 无 |
| 50 | 100%/100% | 4m20s | 4m~5m7s | OK | 无 |
| 100 | 100%/100% | 4m30s | 4m15s~5m22s | OK | kube-apiserver 、prometheus 的压力显著增加 |
| 200 | 100%/100% | 8m50s | 7m55s~9m25s | OK | 平均时长显著增加 |
| 400 | 100%/100% | 16m5s | 12m11s~17m04s | 不流畅 | 执行时间差异明显增加 |
| 800 | 100%/100% | 35m26s | 12m21s~42m21s | 很卡 | - |
| 1600 | 100%/100% | 50m12s | 12m58s~85m59 | 打不开 | - |
7.2 Tekton 创建流水线速度
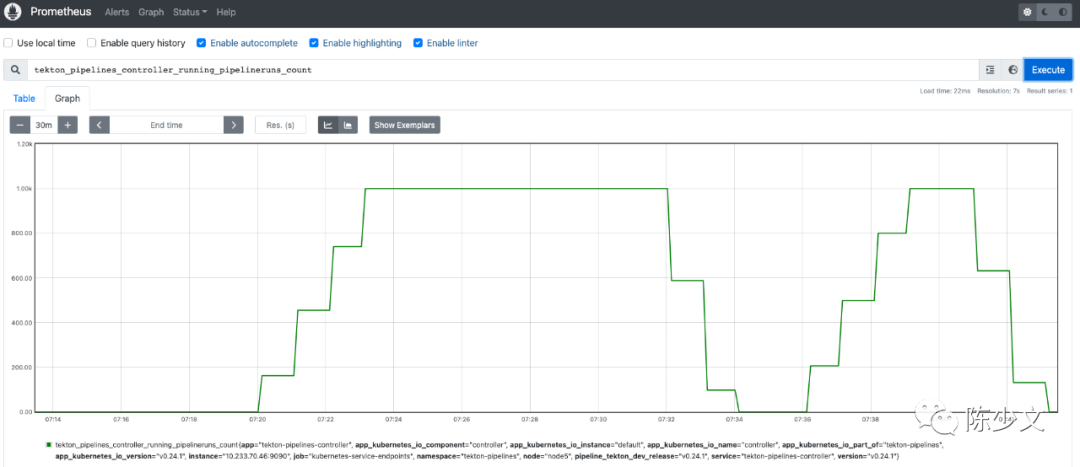
在以上集群参数下,1k 条流水线,需要约 200 秒全部创建完成,平均 5 条/秒的创建速度。
8. 总结
虽然真正的任务只执行 3m,但单条流水线平均执行时间 3m37s,其中就有 37s 用于创建 Pod。可以通过减少 task,增加 step 减少 Pod 数量,节省流水线执行时间。
并发时,流水线的执行完成顺序并不是触发的顺序。流水线执行每个 task 需要创建 Pod,导致流水线之间形成竞争,无法快速执行完成单个流水线中的全部 task。
从 100 并发开始,并发量每增加一倍,平均执行时间增加一倍。200 并发时,执行时间翻倍是不能接受的。因此单个集群的并发应该控制在 100 以内。
虽然数据只列到 1600,实际上测试到接近 1w 也能抗住,但流水线执行时间太长。原本只需要 3 m 执行完成的流水线,高并发下竟然需要几个小时,已经失去了实际意义。
9. 参考
https://tekton.dev/vault/pipelines-v0.24.3/tekton-controller-performance-configuration/