
老大让我优化数据库,我上来就分库分表,他过来就是一jio。。。
记得,如果有人问你做数据库优化最有效的方式是什么?
SQL优化、分布式集群、分库分表!干就完了~
但上来就考虑分库分表真的合适么,你对分库分表又理解多少呢?什么时候分?有几种分法儿?
首先我们要知道分库、分表都是干啥的,本文主角还是我们的MySQL为第一视角。首先从字面意思来看:
分库:
由单个数据库实例拆分成多个数据库实例,将数据分布到多个数据库实例中。
分表:
由单张表拆分成多张表,将数据划分到多张表内。
要知道,对于大型互联网项目,数据量级可能不是我们能想到的,每日新增数据量过千万是常有的事儿,想靠单台MySQL服务器是不现实的。你项羽在牛B,也顶不住四个队友挂机啊!!项羽:???
随着业务数据量和网站QPS日益增高,对数据库压力也越来越大,单机版数据库很快会到达存储和并发瓶颈,就需要做数据库性能方面的优化,分库分表采取的是分而治之的策略,分库目的是减轻单台MySQL实例存储压力及可扩展性,而分表是解决单张表数据过大以后查询的瓶颈问题,坦白说,这些问题也是所有关系型数据库的“硬伤”。
今天我们就基于常见分库、分表的策略方式以及场景,来搞清楚我们到底啥时候用的到。常用策略包括:垂直分表、水平分表、垂直分库、水平分库。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
一、朴实无华的 - 分表
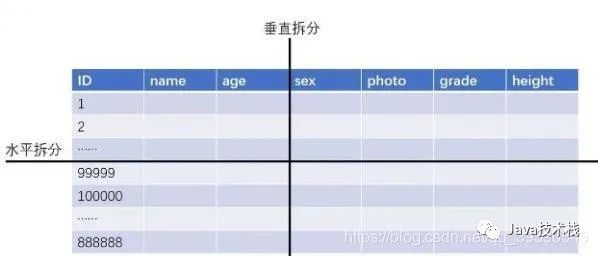
1、垂直分表
垂直分表,或者叫竖着切表,是不是感受到该策略是以字段为依据的!主要按照字段的活跃性、字段长度,将表中字段拆分到不同的表(主表和扩展表)中。
每个表的数据也不一样,有一个关联字段,一般是主键或外键,用于关联兄弟表数据;
有几个字段属于热点字段,更新频率很高,要把这些字段单独切到一张表里,不然innodb行锁很恶心的,锁死你呀,如用户表里的余额字段?不,我的余额就很稳定,一直是0。。
有大字段,如text,存储压力很大,毕竟innodb数据和索引是同一个文件;同时,我又喜欢用SELECT *,你懂得,这磁盘IO消耗的,跟玩儿似的,谁都扛不住的。
2、水平分表
水平分表,也叫“横着切”。。以行数据为依据进行切分,一般按照某列的自容进行切分。
如手机号表,我们可以通过前两位或前三位进行切分,如131、132、133 → phone_131、phone_132、phone_133,手机号有11位(100亿),量大是很正常的事儿,这年头谁家老头老太太每个手机呢是吧。这样切就把一张大表切成了好几十张小表,数据量不就下来了。
有同学就问了那我怎么知道我这手机号查哪个表呢?一看你就没认真看前两行标红的点,为啥标红嘞?比如我查13100001111,那我截取前三位,动态拼接到查询的表名上,就行了。
特点:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是该表的全量数据;
场景:
单表的数据量过大或增长速度很快,已经影响或即将会影响SQL查询效率,加重了CPU负担,提前到达瓶颈。记得水平分表越早越好,别问我为什么。。
二、花里胡哨的 - 分库
需要你注意的是,传统的分库和我们熟悉的集群、主从复制可不是一个事儿;多节点集群是将一个库复制成N个库,从而通过读写分离实现多个MySQL服务的负载均衡,实际是围绕一个库来搞的,这个库称为Master主库。
而分库就不同了,分库是将这个主库一分为N,比如一分为二,然后针对这两个主库,再配置2N个从库节点。
1、垂直分库
纵向切库,太经典的切分方式,基于表进行切分,通常是把新的业务模块或集成公共模块拆分出去,比如我们最熟悉的单点登录、鉴权模块。熟悉的味道,记得有一次我把一些没用的表切到一个性能很好的服务器中,这服务器我专门用来学习,后来也不知被哪个狗腿子告密了~
可以抽象出单独的业务模块时,可以抽象出公共区时(如字典、公共时间、公共配置等),或者想有一台属于自己的服务器时?
2、水平分库
以行数据为依据,将一个库中的数据拆分到多个库中。大型分表体验一下?坦白说这种策略并不实用,因为会对后台开发很不友好,有很多坑,不建议采用,理解即可。
特点:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
系统绝对并发量上来了,CPU内存压力大。分表难以根本上解决量的问题,并且还没有明显的业务归属来垂直分库,主库磁盘接近饱和。
总结
本文就到这里,希望你学废了!其实,在实际工作中,我们在选择分库分表策略前,想到的应该是从缓存、读写分离、SQL优化等方面,因为这些能够更直接、代价更小的解决问题。
要记住动表就是动根本,你永远不知道这张表后面会连带多少历史遗留问题,如果是个很大型的项目,遇到些问题你就跟经理提议要分库分表,小心被呼死~另外
原文链接:https://blog.csdn.net/qq_39390545/article/details/116248222
5、37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...