
探秘前端 CRDT 实时协作库 Yjs 工程实现
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
作为近年来分布式系统领域算法研究的新成果,CRDT[1] 基础库为前端应用带来了奇妙的可能性:只需要一个 API 与 backbone 几乎一样简单的 model 层,你的应用就能自然地获得对多人协作场景下并发更新的支持。这背后隐藏着怎样的黑魔法呢?本文希望以当下代表前端 CRDT 库性能巅峰的 Yjs[2] 为例,向大家直观地展示 how CRDT works。
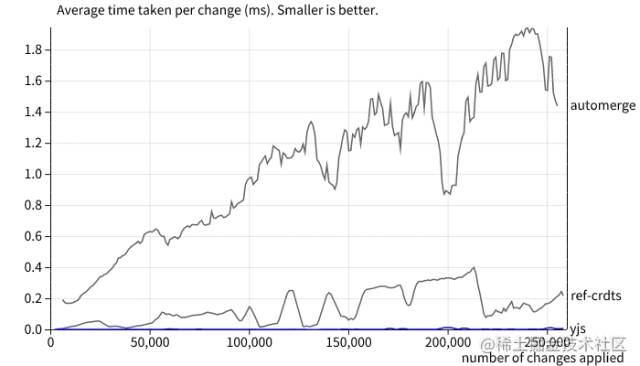 (图为 Yjs 和其他前端主流 CRDT 库的性能对比,Yjs 对应底部的蓝线)
(图为 Yjs 和其他前端主流 CRDT 库的性能对比,Yjs 对应底部的蓝线)
本文会从 Yjs 的工程实现出发,介绍一个典型的工业级 CRDT 库是如何实现以下能力的:
建模数据结构 解决并发冲突 回溯历史记录 同步网络状态
作为一份科普性的介绍,本文不会动辄甩出大段晦涩的源码,也不会涉及多少抽象的数学知识。阅读时只需了解数据结构方面的计算机基础即可。
在实际介绍 Yjs 内部概念前,我们该如何直观地了解 CRDT 库的使用方式呢?Yjs 对使用者提供了如 YText[3]、YArray[4] 和 YMap[5] 等常用数据类型(即所谓的 Shared Types[6],这里把它们统称为 YModel),可以直接作为应用的 model 层使用:
import * as Y from 'yjs'
// 应用中的全部协作状态均可在单个 YDoc 容器中承载
// 将该实例传入 WebSocket 等协议的 provider 后即可支持网络同步
const doc = new Y.Doc()
// 在 YDoc 上可以创建不同类型的顶层 YModel 实例
// 这里创建了一个顶层名为 root 的 YMap
const yRoot = doc.getMap('root')
// 也可以用 class 构造器来实例化独立的 YMap 等 YModel
// 可直接用 get set delete 等常见 API 对 YModel 增删改查
const yPoint = new Y.Map()
yPoint.set('x', 0)
yPoint.set('y', 0)
// YMap 的值也可以是 YMap,从而构造出嵌套的数据类型
yRoot.set('point', yPoint)
// YMap 中还可以存入 YText 等其他 YModel,形成复合的数据类型
const yName = new Y.Text()
yName.insert(0, 'Wilson Edwards')
yRoot.set('name', yName)
复制代码
这套 API 表面看起来平淡无奇,但它真正的强大之处在于 Conflict-free,亦即对上层而言,并发更新时潜在的状态冲突已经被 Yjs 自动解决了:
// 可以用 2 份独立的 YDoc 实例来模拟 2 个客户端
const doc1 = new Y.Doc()
const doc2 = new Y.Doc()
const yText1 = doc1.getText()
const yText2 = doc2.getText()
// 在某份 YDoc 更新时,应用二进制的 update 数据到另一份 YDoc 上
doc1.on('update', (update) => Y.applyUpdate(doc2, update))
doc2.on('update', (update) => Y.applyUpdate(doc1, update))
// 制造两次存在潜在冲突的更新
yText1.insert(0, 'Edwards')
yText2.insert(0, 'Wilson')
// CRDT 算法可保证两份客户端中的状态始终一致
yText1.toJSON() // WilsonEdwards
yText2.toJSON() // WilsonEdwards
复制代码
透过这些 Yjs 表层 API 的例子,我们应该已经可以认识到 CRDT 的威力所在了。下面真正有趣的问题来了:Yjs 内部是如何实现这一能力的呢?
建模数据结构
提到「底层原理」,很多同学可能会立刻会开始想象某种精妙的冲突解决算法。但在介绍这一算法前,我们最好先熟悉一下 Yjs 在工程上建模 CRDT 时所用的基础数据结构:双向链表。
在 Yjs 中,不论是 YText、YArray 还是 YMap,这些 YModel 实例中的数据都存储在一条双向链表里。粗略地说,这条链表中的每一项(或者说每个 item)都唯一地记录了某次用户操作所修改的数据,某种程度上和区块链有些异曲同工。可以认为上面例子中对 YModel 的操作,最后都会转为对这条链表的 append、insert、split、merge 等结构变换。链表中每个 item[7] 会被序列化编码后分发,而基于 CRDT 算法的保证,只要每个客户端最终都能接收到全部的 item,那么不论客户端以何种顺序接收到这些 item,它们都能重建出完全一致的文档状态。
基于上述手段实现的 CRDT 结构是 CRDT 流派中的一种,可以将其称为 operation-based CRDT[8]、list CRDT 或 sequence CRDT。
显然, 在多人实时协作这种无法保证 item 接收时序的场景下,每个 item 都需要携带某种标识,供系统唯一确定其在逻辑时间轴上的位置。Yjs 会为每个 item 分配一个唯一 ID,其结构为 ID(clientID, clock),如下所示:
// Yjs 中的 ID 源码,这样的朴素实现有利于引擎的 hidden class 优化
class ID {
constructor (client: number, clock: number) {
// 客户端的唯一 ID
this.client = client
// 逻辑时间戳
this.clock = clock
}
}
复制代码
这里的 clientID 和 clock 都是整数,前者用于唯一标识某个 YDoc 对应的客户端,而后者则属于一种名为 Lamport timestamp[9] 的逻辑时间戳,可以认为这就是个从零开始递增的计数器。它的更新规则非常简单:
发生本地事件时, localClock += 1。在接收到远程事件时, localClock = max(remoteClock, localClock) + 1。
这种机制看似简单,但实际上使我们获得了数学上性质良好的全序结构。这意味着只要再配合比较 clientID 的大小,即可令任意两个 item 之间均可对比获得逻辑上的先后关系,这对保证 CRDT 算法的正确性相当重要。但相关数学理论并非本文重点,在此不再展开。
我们可以借助文本编辑的例子来理解这种 list CRDT 的工作方式。在未经任何优化的朴素情况下,这种结构要求我们把每个字符插入操作都建模为一个 item,也就是每个字符都携带了一个逻辑时间戳 ID:
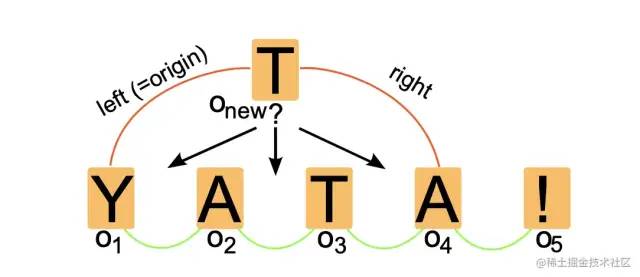
在上面的例子中,Y A T A ! 这几个字符每个都对应一个 item(或者说一次字符插入的 operation)。它们通过 left 和 right 字段连接在一起。在插入新字符 T 的时候,Yjs 就会根据 item 的 ID 在链表中查找合适的插入位置,将新字符对应的 item 接入链表中。另外同个用户持续追加的文字也会被合并成 length 很长的单个 item,避免大量碎片化对象的性能问题。
注意,在文档的高频增删过程中,并不是所有 item 都会持续存在于链表中。但由于 CRDT 的冲突解决需要依赖历史 item 的元数据,我们并不能直接将历史上的 item 硬删除,至多只能移除掉该 item 对应的 YModel 内容(为此 Yjs 特别设计了 GC[10] 对象来将废弃的 YModel 替换为空结构,相当于一种墓碑机制)。这就带来了下一个问题:该使用怎样的数据结构来存储文档内所有的 item 呢?
由于任意 item 均可用 ID 来排序,因此一种选择是使用 B 树这样具备对数级优良插入和删除时间复杂度的数据结构,将所有的 item 维护在一棵平衡二叉树中。但实践中 Yjs 选择了一种更简单直接的方案,即为每个 client 分配一个扁平的 item 数组,相应的结构被称为 StructStore[11]:
// 实践中可以用 doc.store.clients.get(doc.clientID) 查看
doc.store.clients: {
114514: [Item, Item, Item], // ...
1919810: [Item, Item, Item] // ...
}
复制代码
在上面的结构中,每个 item 数组都是按 clock 字段的值来排序的。这样只需要做一次二分查找,就能快速找到某个 ID 对应的 item。而在接收到远程 item 时,Yjs 除了将 item 插入链表,也会将它插入 StructStore 中的相应位置。
因此我们可以认为,Yjs 中存在两种索引数据的方式:
依据文档结构顺序(即 document order)建模的双向链表。 依据逻辑时序(即 insertion order)建模的 StructStore。
理解这个心智模型,会很有利于我们调试 Yjs 的内部状态。比如下面的代码就会产生 3 个 item:
const yPoint = new Y.Map()
yRoot.set('a', yPoint) // item 1
yPoint.set('x', 0) // item 2
yPoint.set('y', 0) // item 3
复制代码
注意 item 相当于一个携带 left / right / ID 等 CRDT 字段的容器,其中具体的 YModel(或者说 AbstractType)数据会存储在 item.content 字段中,另外还有 parent 和 parentSub 字段会用于辅助表达 YMap 等嵌套结构的父子关系。其整体结构如下所示:
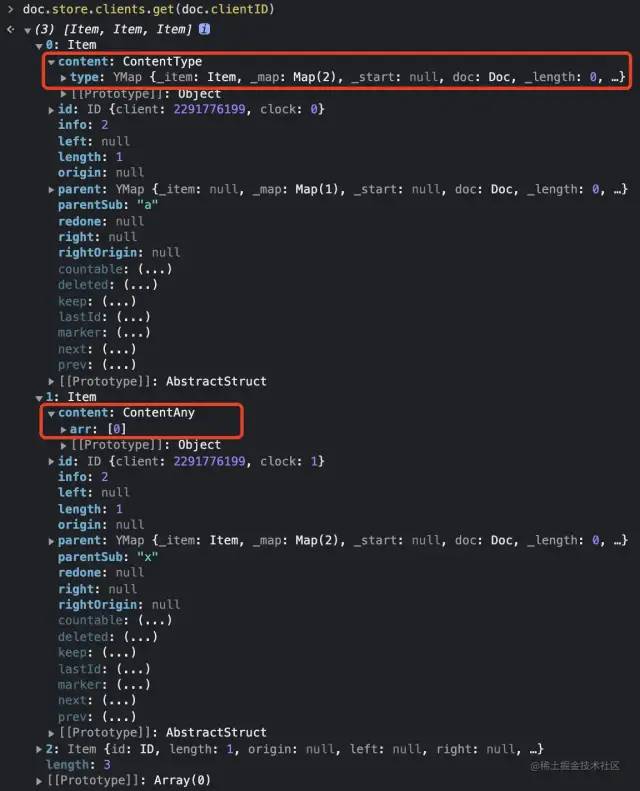
由于 item.content 也能携带任意的 YMap 等 AbstractType 数据,这样就自然地支持了数据的嵌套。基于这种链式结构,此时一份 YMap 就对应于一系列的 entry,其中每个 key 都使用逻辑时间轴上最新的数据为当前状态,而这个 key 下其他更早的状态所对应的 item 都会被标记为删除。
为了优化本地插入的速度,Yjs 还设计了额外的缓存机制。如果在文档中任意位置随机插入新字符,这时新字符对应的 item 理论上需要 O(N) 的时间复杂度才能插入链表中。但实际上,大多数插入操作都会跟随在用户最后编辑的光标位置。因此 Yjs 默认会缓存 10 个最近的插入位置供快速匹配,在内部实现中这被称为 skip list(作者认为这一缓存机制是受到了跳表的启发)或 fast search marker。
在熟悉了基本的数据结构设计后,我们就可以进一步理解 Yjs 所设计的冲突解决机制了。
解决并发冲突
CRDT 库是以怎样的策略来解决冲突的呢?其实在上面出现冲突的案例中,不管 Wilson 和 Edwards 这两段文本到底该怎么排列组合,都可以认为属于一种乌龙。这时候到底什么才是「正确的」其实已经不太重要,只要保证所有接收到消息的节点都能自觉地衍生出同样的状态就足够了——这就是所谓的 convergence(最终状态一致性)概念。
Yjs 中的 item 会组成一条双向链表。但为了妥善地解决冲突,它的实现并不仅包含 left 和 right 字段,还有这两个字段:
origin字段存储 item 在插入时的左侧节点。rightOrigin字段存储 item 在插入时的右侧节点。
每个 item 在插入文档时都需要执行其 integrate 方法,核心的冲突解决算法就在这里用到了上述这些字段,一共仅有约 20 行:
while (o !== null && o !== this.right) {
itemsBeforeOrigin.add(o)
conflictingItems.add(o)
if (compareIDs(this.origin, o.origin)) {
if (o.id.client < this.id.client) {
left = o
conflictingItems.clear()
} else if (compareIDs(this.rightOrigin, o.rightOrigin)) {
break
}
} else if (o.origin !== null && itemsBeforeOrigin.has(getItem(transaction.doc.store, o.origin))) {
if (!conflictingItems.has(getItem(transaction.doc.store, o.origin))) {
left = o
conflictingItems.clear()
}
} else {
break
}
o = o.right
}
复制代码
根据 Yjs 所用 YATA 算法的论文,上述代码的核心思想是保证新潜在插入 item 的左右连线(即下图中的红线)不形成交叉:

不过,为什么只要避免了交叉就能保证算法的正确性呢?这需要数学上的证明,在 YATA 算法的论文中有更多具体细节,对本文而言已经超纲了。
有趣的是,冲突在实际应用中其实很罕见。因此虽然上面这段代码属于 CRDT 库的算法核心,但一般却很少会执行,也可以理解为一种保证数据不会因并发更新而损坏的保障性机制。
回溯历史记录
从上面的介绍中我们可以发现,实际上一份文档中所有的 item 结构都可以被持续存储下来,这显然对历史记录有很大的价值。为此 Yjs 也自带了 UndoManager[12] 来提供开箱即用的历史记录管理功能。在个人之前的知乎回答中,也介绍过协作场景下历史记录模块的设计准则[13]。但这个回答中提到的思维模型主要还是利于在高层面上推演出一些产品操作所应获得的效果,而不是工程细节层面的实现。为了追求极致性能,Yjs 的实现其实还做了更多优化,这里做一个简单的总结。
在讨论 UndoManager 的实现方式前,我们需要了解 Yjs 对删除操作所做的特殊处理。在 Yjs 中,每个 item 均可以被标记为删除(可以通过 item.deleted 的 getter 来检查),但 item 中并没有记录关于删除操作的更多信息:
在 item 中不会记录它时何时被删除,或是被哪个用户删除了。 在 StructStore 中也不会记录删除操作。 在删除发生后,本地的 clock 不会递增。
那么,删除操作的信息是在哪里建模的呢?Yjs 引入了 DeleteSet[14] 的概念,可以记录逻辑时间轴上某段时间内(或者说某次 transaction 中)所有被删除的 item,这份数据也会独立于 item 分发。换句话说,Yjs 中的删除操作被设计成了独立于双向链表的结构。在前面关于 item 双向链表的介绍中,我们讨论的还是一个 operation-based CRDT。但在处理删除操作时,Yjs 的设计则相当于一种更简单的 state-based CRDT[15]。
所谓的 state-based CRDT 会将本地状态全量发送到每一个客户端,在各个客户端独立做合并计算。对于计数器一类的轻量状态,这类 CRDT 往往有更高的实用性。可以认为 Yjs 对删除操作的建模就符合这一概念。
在上面的介绍中我们提到了 transaction[16] 的概念,这是 Yjs 中用于构建事件系统的抽象。每次更新对应的 transaction 都包括两份数据:
这次更新所插入的 item。 这次更新所删除 item 的 DeleteSet。
在网络上实际分发的二进制增量更新数据,就是序列化编码后的 transaction。可以认为 transaction 既会用于编码更新,也是撤销重做操作对应的粒度。基于上述数据结构,可以发现只要做两件事就可以撤销掉一次 transaction:
将这次 transaction 所插入的 item 标记为删除。 将这次更新所删除的 item 标记为恢复。
由于这个过程并不需要新增新的 item,因此这样一来,连续的撤销重做操作在理论上就相当于只需持续分发轻量级 DeleteSet 即可。由于 DeleteSet 的结构非常轻(例如在记录了真实用户 LaTeX 论文编辑过程的 B4[17] benchmark 数据集中,18.2 万次插入和 7.7 万次删除后仅生成了 4.5KB 的 DeleteSet),这种设计就进一步贴近了「零开销抽象」,因为撤销重做时并没有创造出任何未知的新数据。
不过,个人认为这种设计虽然能起到更极致的优化效果,但也让维护变得更加困难了。如 UndoManager 之前一个难以修复的问题就是「连续撤销 3 次内可重做返回原始状态,4 次以上则可能丢失字段」。这一问题的根源在于当时的实现对 item 复原的逻辑有问题,可能无法连续右移找到应被恢复的正确 item 位置。虽然针对该问题个人已经提交修复 PR[18],但其排查过程也有不少坎坷。如果有同学希望实现自己的试验性 CRDT 库,基于 DeleteSet 的优化应当并不属于第一个原型中就需要实现的能力。
同步网络状态
虽然 CRDT 库本身与具体的网络协议无关,但作为一整套渐进的解决方案,Yjs 也设计了配套的网络协议。这部分与 Yjs 内部实现相关的重点包括这些:
整份 Yjs 文档可以被编码为 Uint8Array 形式的 update 数据,Yjs 也可以从二进制数据中反序列化出 YDoc 的对象结构。每次文档更新的 transaction 也会计算出增量的更新以供同步,其中包含 item 和 DeleteSet,如前所述。 Yjs 通过 state vector 的概念来定位逻辑时间轴,这种数据结构实际上就是一组记录了某时刻全部客户端 (client, clock)的 tuple。
在同步文档状态时,Yjs 划分了两个阶段:
阶段一:某个客户端可以发送自己本地的 state vector,向远程客户端获取缺失的文档 update 数据。 阶段二:远程客户端可以使用各自的本地 clock 计算出该客户端所需的 item 对象,并进一步编码生成包含了所有未同步状态的最小 update 数据。
理论上,我们可以为 Yjs 配套支持 WebSocket 之外的更多网络协议,当前 Yjs 也已经支持了 Dat[19] 这样面向分布式 Web 的新协议。但与网络协议相关的内容并不在 Yjs 主仓库中,可以参见 y-protocols[20] 项目。
总结
到此为止,我们已经介绍了 Yjs 主要的内部特点:
基于双向链表和 StructStore 的基础数据结构 基于 YATA 算法的并发冲突解决机制 基于 DeleteSet 和 Transaction 机制的撤销重做 基于两阶段划分的同步机制
受个人能力所限,还有许多技术细节无法在本文逐一覆盖。最后列出一些有价值的参考资料:
YATA[21] 论文介绍了 Yjs 的算法设计与正确性证明。 Yjs Internals[22] 记录了 Yjs 的关键内部结构,其中很多内容对本文有帮助。 Are CRDTs suitable for shared editing[23] 由 Yjs 作者 Kevin Jahns 介绍了他实现的若干关键优化。 5000x fater CRDTs: An Adventure in Optimization[24] 是 OT 库 ShareDB 作者 Seph Gentle 撰写的博文,深度剖析了 CRDT 工程性能改进的历程。 How Yjs works from the inside out[25] 是 Seph 为了解 Yjs 而邀请 Kevin 做的视频访谈,虽然很长但相当有启发。 个人的 D2[26] 分享介绍了 Yjs 的项目接入实践。
由于 Yjs 背后 CRDT 极佳的去中心化性质,它在 Web 3.0 时代或许有机会成为某种形式的前端基础设施。从它的案例中我们可以感受到,学术研究成果的实用化并非一蹴而就,更有赖于大量具体的工程细节处理与针对性优化,这背后仍然绕不开基础的数据结构和算法等计算机基础知识。并且相对于经典的 OT,近年来 CRDT 的流行或许也属于一次潜在的范式转移(paradigm shift),这对前端开发者们意味着全新的机遇。希望本文对感兴趣的同学能有所帮助。
关于本文
来源:doodlewind
https://juejin.cn/post/7049148428609126414
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章 2. 订阅官方博客 www.inode.club 让我们一起成长 点赞和在看就是最大的支持❤️