
提取中文地址描述中的省市区信息


实例描述
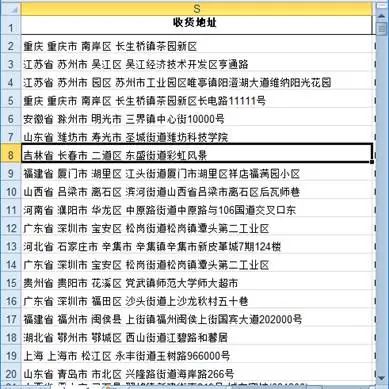
图 1 收货地址数据
本实例将提取地址中的省份,并按省份统计销售金额,效果如图 2 所示。 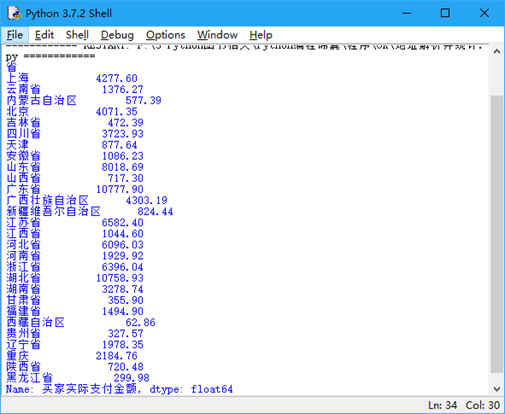
图 2 提取地址中的省份
技术要点
l 切分字符串,分开后存入一列里
series=data[ ' 列名 ' ].str.split( ' ' )
把 DataFrame 列中字符串以空格 ' ' 分隔开,每个元素分开后存入一列里。
l 切分字符串,分开后存入多列里
series=data[ ' 列名 ' ].str.split( ',' , expand = True )
参数 expand ,这个参数取 True 时,会把切分出来的内容分成多列。
如果只要第一列: series=data[' 列名 '].str.split(' ',expand=True)[0]
代码实现
程序代码如下:
import pandas as pd
aa = './data/TB2018.xlsx'
df = pd.DataFrame(pd.read_excel(aa))
series=df[ ' 收货地址 ' ].str.split( ' ' , expand = True )
df[ ' 省 ' ]=series[0]
#df[' 省 '],df[' 市 '],df[' 区 ']=series[0],series[1],series[2]
df1=df.groupby([ " 省 " ])[ " 买家实际支付金额 " ].sum()
print (df1)
df.to_excel( 'test.xlsx' )

评论