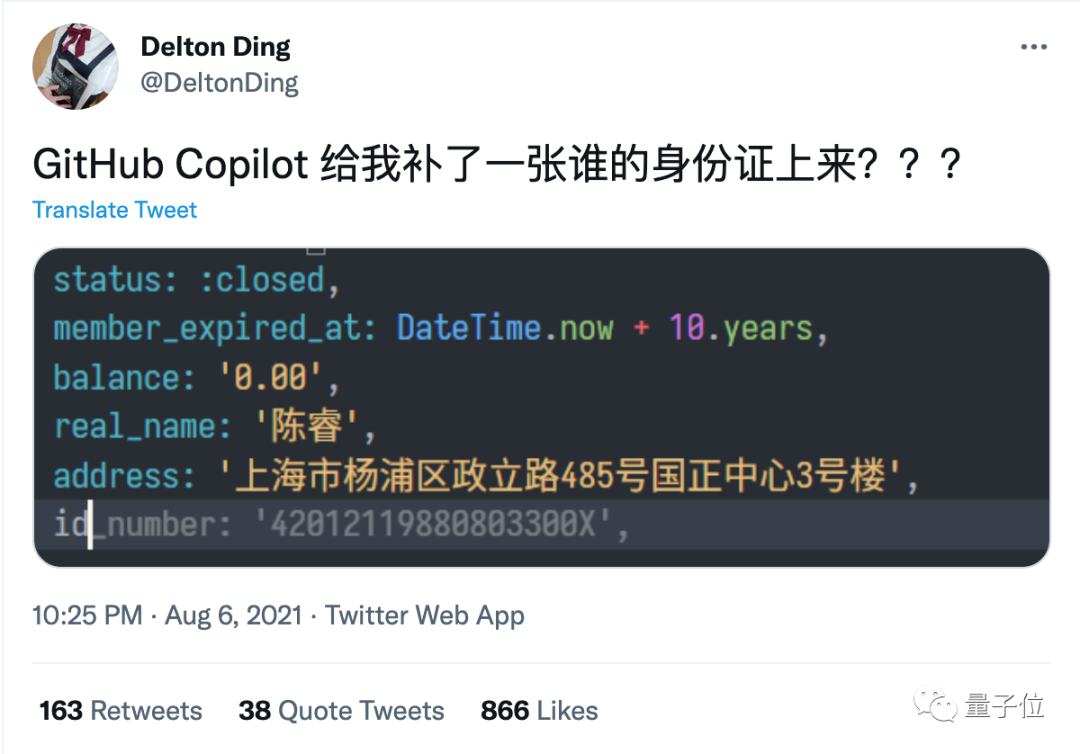
AI 自动补全代码,结果补出来了一张别人的身份证?有人在推特上晒图,表示自己在使用 GitHub Copilot 时,它竟然给补全出了一张身份证信息出来。输入 B 站 CEO 陈睿的信息后,下方竟然自动补出了身份证号。
显示的身份证号其实是假的,其中出生年份和校验位明显都是错的。陈睿应该是 1978 年生,而这里的证件号上显示为 1988。也就是说,这串所谓的身份证号,其实是 GitHub Copilot 自动生成的假数据。但是原本是生成代码的 GitHub Copilot,怎么会生成个人隐私信息呢?
吃了的,不经意又吐出来
这和 GitHub Copilot 的工作原理有一定关系。GitHub Copilot 由 Codex 模型支持,它可以看做是 GPT-3 的升级版,既能看懂代码、也能看懂自然语言。一方面,GitHub Copilot 为了能看懂注释,需要接受像 GPT-3 一样的语言训练。语言模型在生成结果时,往往会随机表现出某些训练数据的特征。也就是模型 “记住了” 见过的数据信息,处理任务时,把它 “吃进去” 的训练数据又 “吐了出来”。而对于 GPT-3、BERT 这些超大型语言模型来说,训练数据集的来源往往包罗万象,大部分是从网络公共信息中抓取,其中免不了个人敏感信息,比如姓名、地址、身份证号等等。有人就表示,b 站高层的个人信息可能早就被人恶意曝光了。这一次很可能是 GitHub Copilot 在生成结果时,随机表现出了一些训练数据的特征,这部分数据刚好来自陈睿的隐私信息。事实上,GitHub 的 CEO Nat Friedman 也回应过类似的问题。他表示 GitHub Copilot 给出的隐私信息都是假的,是通过训练数据合成而来。而前不久曝出的 Copilot 抄袭大神代码、原版注释一事,直接让 Nat 这番回应啪啪打脸。自动生成的代码不仅和原版一样,连 “what the fuck” 那句注释也用上了。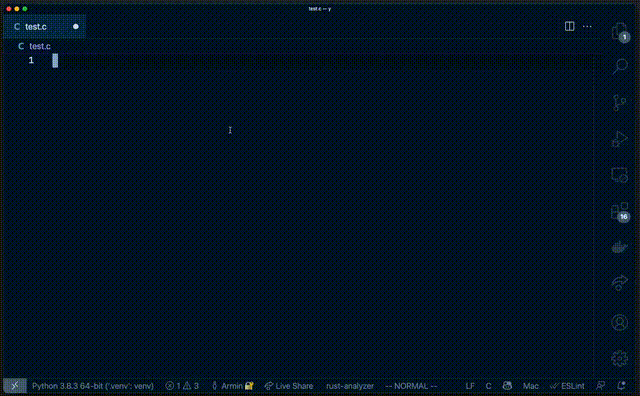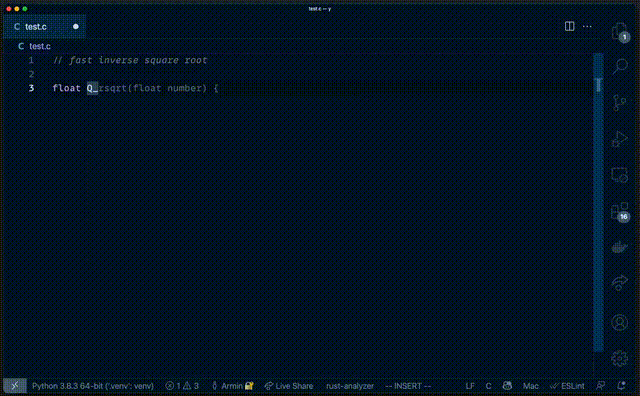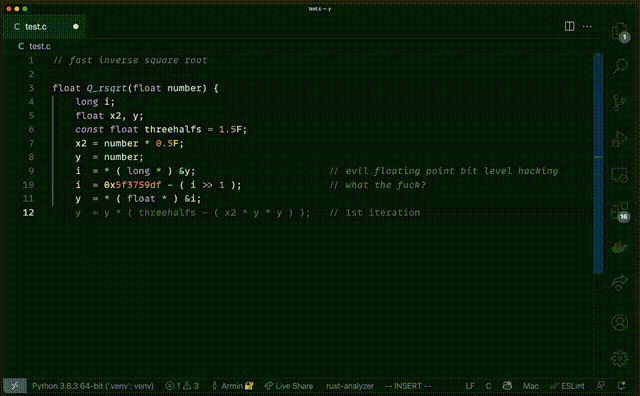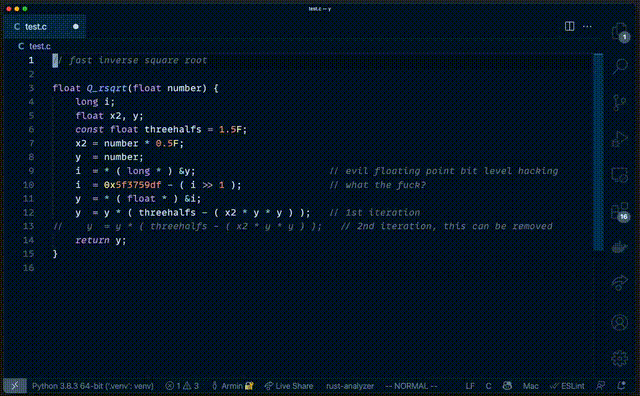
△GitHub Copilot 复刻 Quake 代码
另一方面,GitHub Copilot 是由数十亿行公开代码训练的。有人认为,这可能是训练集中的原始代码就违反了相关隐私条款。GitHub Copilot 受到错误代码的影响,意外把陈睿的个人信息从数据集里套了出来。虽然这次情况可能只是个意外,但是也暴露了 GitHub Copilot 在安全隐私上存在许多风险。有网友就对 GitHub Copilot 的敏感信息处理,表示担忧:小米开源技术委员会主席、小米副总裁崔宝秋则表示,这提醒了用户要注意自己的安全隐私保护,个人数据要记得匿名化。
GitHub Copilot 争议不断
事实上,GitHub Copilot 从上线以来就争议不断:除了安全隐私上的风险,openAI 还发现 GitHub Copilot 的模型 Codex 与 GPT-3 一样,会生成带有种族主义或其他伦理问题的结果。最近,自由软件基金会(Free Software Foundation,FSF)也发出了抗议,他们表示使用 GitHub Copilot 必须运行 Visual Studio IDE 或 Visual Studio Code 这种付费软件,侵犯了用户的权益。为此,FSF 正在向大众征集 GitHub Copilot 在版权、法律等问题的投稿。对于这一抗议,GitHub 方面则表示愿意对任何问题持开放态度。“这是一个全新的领域,我们渴望与开发者就这些话题进行讨论,并引领行业为训练人工智能模型制定适当的标准。”参考链接:
[1]https://twitter.com/DeltonDing/status/1423651446340259840
[2]https://venturebeat.com/2021/07/08/openai-warns-ai-behind-githubs-copilot-may-be-susceptible-to-bias/
[3]https://www.infoworld.com/article/3627319/github-copilot-is-unacceptable-and-unjust-says-free-software-foundation.html 技术交流群
技术交流群最近有很多人问,有没有读者交流群,想知道怎么加入。
最近我创建了一些群,大家可以加入。交流群都是免费的,只需要大家加入之后不要随便发广告,多多交流技术就好了。
目前创建了多个交流群,全国交流群、北上广杭深等各地区交流群、面试交流群、资源共享群等。
有兴趣入群的同学,可长按扫描下方二维码,一定要备注:全国 Or 城市 Or 面试 Or 资源,根据格式备注,可更快被通过且邀请进群。