
MySQL 复杂 where 语句分析
点击上方"程序员历小冰",选择“置顶或者星标”
你的关注意义重大!
在《MySQL 常见语句加锁分析》一文中,我们详细讲解了 SQL 语句的加锁原理并具体分析了大部分的简单 SQL 语句,但是实际业务场景中 SQL 语句往往及其复杂,包含多个条件,此时就需要具体分析SQL 使用到的索引,并了解 where 条件的判断逻辑。
我们可以直接使用 explain 或者 optimizer_trace 来分析 SQL 语句执行使用了哪些索引,具体使用可以看本系列文章的前两篇文章。
但是我们也需要了解具体 Where 语句的条件的拆分和使用,即复杂 Where 条件是如何生效的,用何登成大神的原话,就是:
给定一条SQL,where条件中的每个子条件,在SQL执行的过程中有分别起着什么样的作用?
具体场景
我们使用下面这张 book 表作为实例,其中 id 为主键,ISBN(书号)为二级唯一索引,Author(作者)为二级非唯一索引,score(评分)无索引。
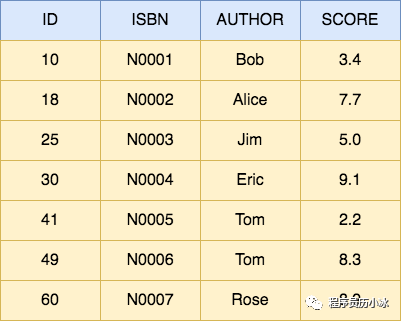
Index Key 和 Table Filter
基于上述表,我们具体分析一下如下拥有复杂 Where 条件的 SQL 语句。
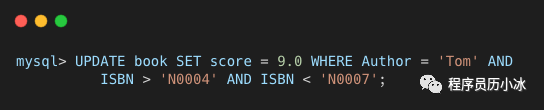
上述 SQL 语句的 Where 条件使用了两个索引,分别是二级唯一索引 ISBN 和二级非唯一索引 Author。
MySQL 会根据索引选择性等指标选择其中一个索引来使用,而另外一个没有被使用的 Where 条件就被当做普通的过滤条件,一般称被用到的索引称为 Index Key,而作为普通过滤的条件则被称为 Table Filter。
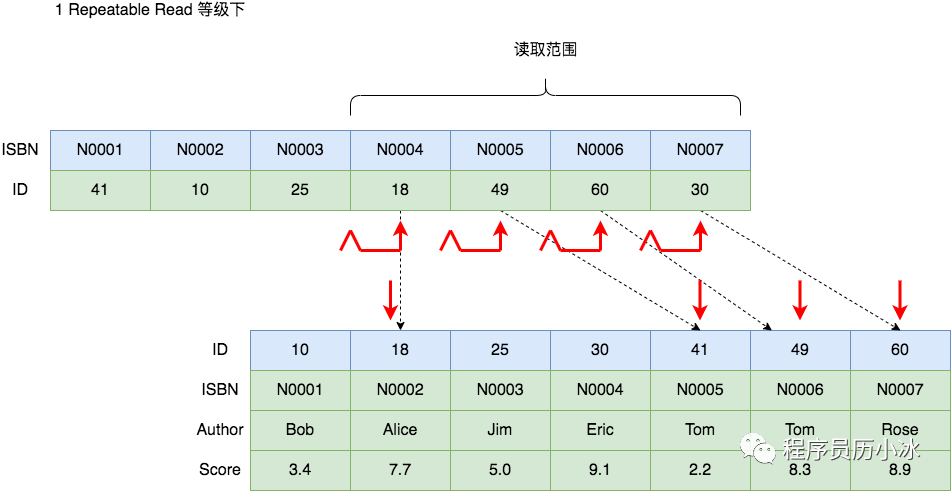
比如上面这条SQL 使用 ISBN索引来查询,则 ISBN 就是 Index Key,而 Author = 'Tom' 这个条件就是 Table Filter。
所以,该 SQL 执行的过程就是依次将 Index Key 范围内的索引记录读取,然后回表读取完整数据记录,然后返回给MySQL的服务层按照 Table Filter 进行过滤。至于加锁,如下图所示则需要将涉及的 Index Key 对应的索引记录都进行加锁。
但是当使用的索引是复合索引时,则还可能出现 Index Filter,利用它可以减少回表次数和返回给 MySQL 服务层的记录的数量,降低存储引擎和服务层的交互开销,提高 SQL 的执行效率。
Index Filter
假设我们在 book 表的 ISBN 和 Author 列上建立了联合索引,并且上述 SQL 执行时选择了该复合索引。
对于这个场景,MySQL 依然使用 ISBN > 'N0004' AND ISBN < 'N0007' 条件来确定 SQL 查询在索引中的连续位置,但是 Author = 'Tom' 可以用来直接过滤索引,即该条件可以使用复合索引来直接过滤条件,不需要读取所有数据后由MySQL 服务层根据 Table Filter 来过滤。
这就是传说中的 ICP(Index Condition Pushdown,索引下推)技术,使用 Index Filter 过滤不满足条件的记录,无需加锁。
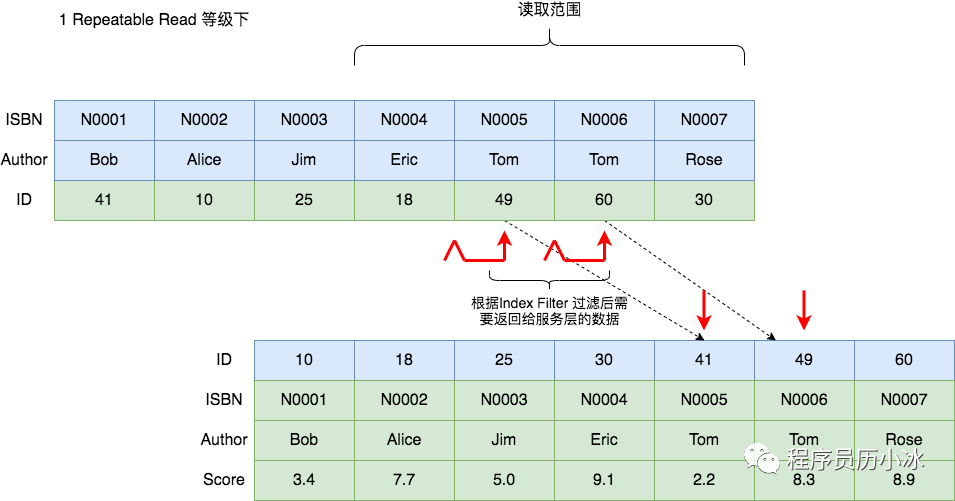
根据 Index Key 判断查询返回和根据 Index Filter 进行初步过滤后,存储引擎将剩下的数据记录返回给服务层,再由服务层根据 Table Filter 进行过滤。
ICP (索引下推)技术
MySQL 5.6 推出的 ICP 技术其实就是 Index Filter 技术,只不过是因为 MySQL 分为服务层和存储引擎层,而 Index Filter 将原本服务层做的过滤操作“下推”到存储引擎层处理。将原来的在服务层进行的Table Filter中可以进行Index Filter的部分,在引擎层面使用 Index Filter 进行处理,不再需要回表进行 Table Filter。
这样做的好处就是减少了加锁的记录数,减少了回表查询的数量,提高了 SQL 的执行效率。
终于要到系列的最后一篇了,下一篇,我们将讲解如何根据 MySQL 信息判断死锁和解决死锁。请大家关注,转发和点赞三连走起。
-关注我