
比拼 Kafka , 大数据分析新秀 Pulsar 到底好在哪

来源:大数据与机器学习文摘 本文约4000字,建议阅读10+分钟
本文介绍了大数据分析Pulsar的好用之处。
本文内容节选自InfoQ:
https://www.infoq.cn/article/1UaxFKWUhUKTY1t_5gPq
消息消费——如何发送和消费消息;
消息确认(ack)——如何确认消息;
消息保存——消息保留多长时间,触发消息删除的原因以及怎样删除;
消息消费模型
Pulsar 的消息消费模型
消费者被组合在一起以消费消息,每个消费组是一个订阅。
每个 Topic 可以有不同的消费组。
每组消费者都是对主题的一个订阅。
每组消费者可以拥有自己不同的消费方式:独占(Exclusive),故障切换(Failover)或共享(Shared)。
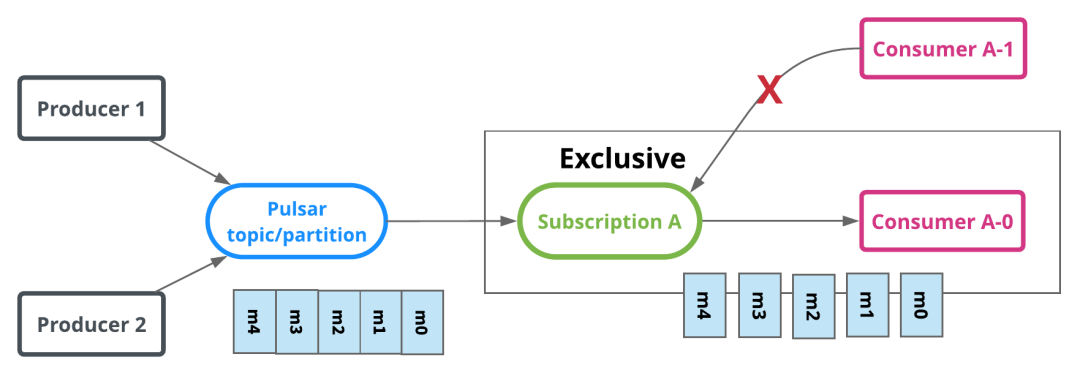
独占订阅(Stream 流模型)
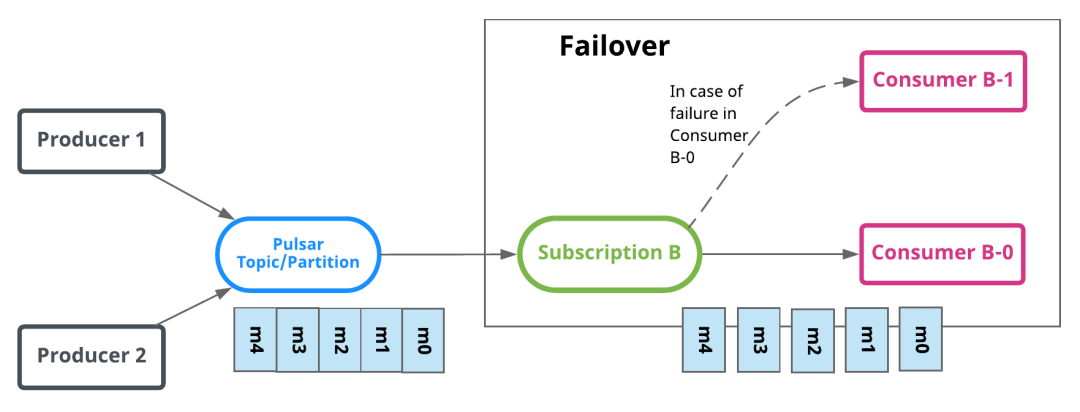
故障切换(Stream 流模型)
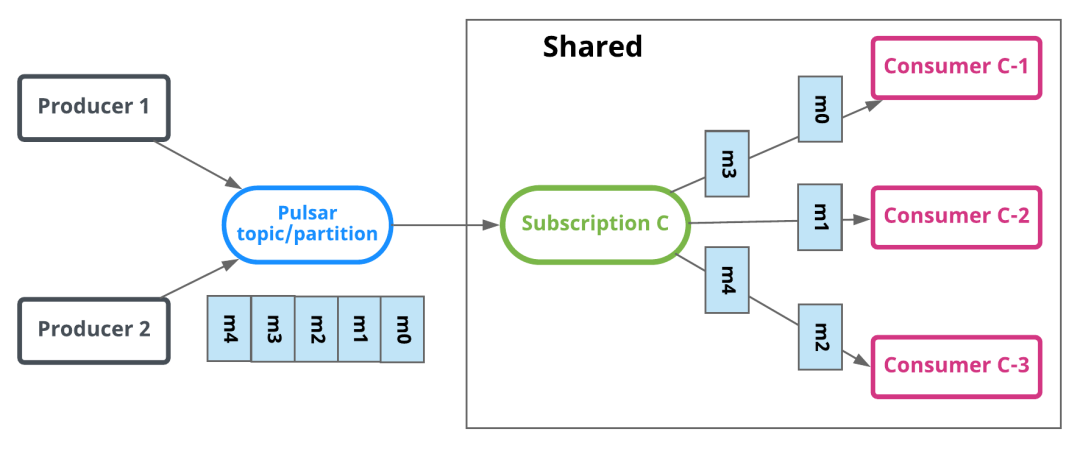
共享订阅(Queue 队列模型)
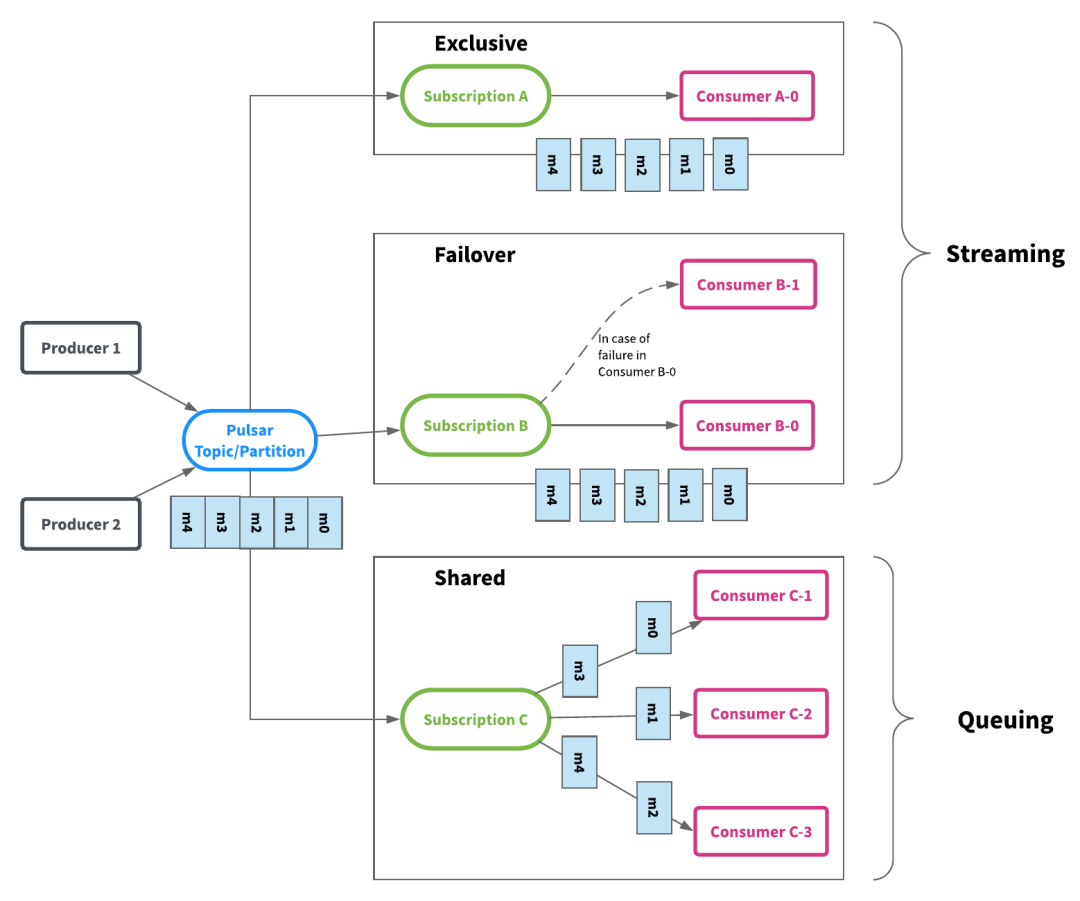
三种订阅模式的选择
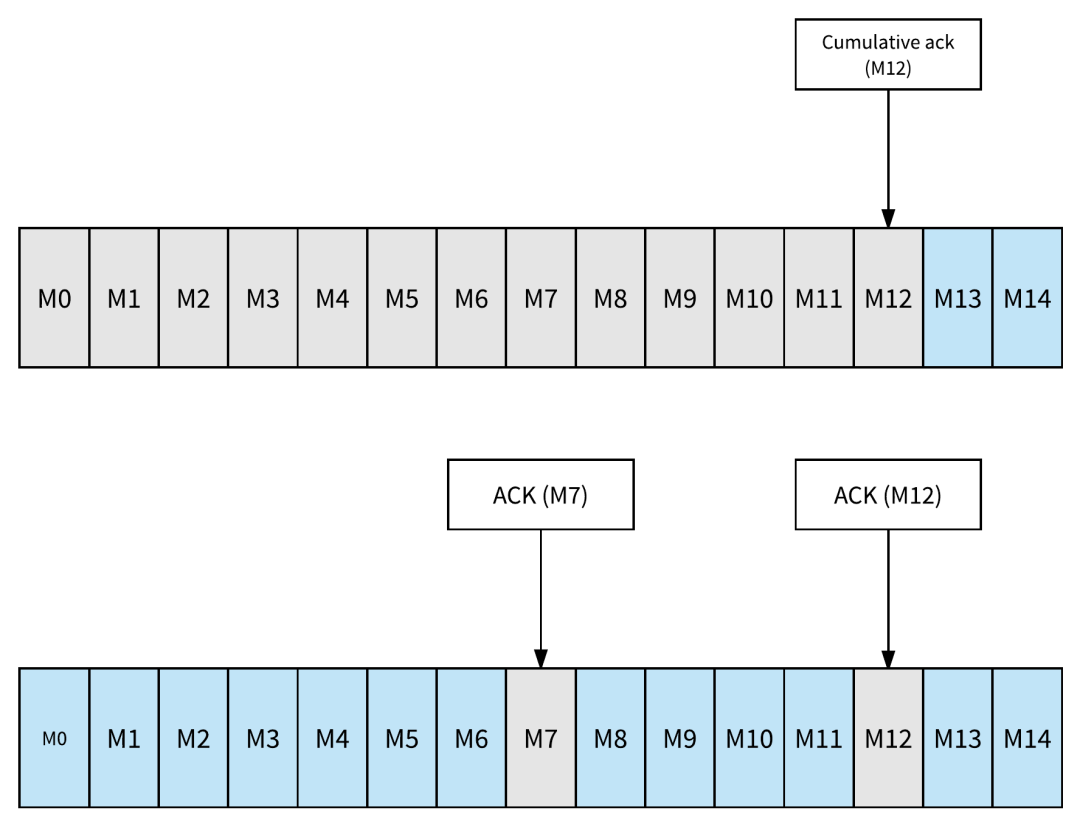
Pulsar 的消息确认(ACK)
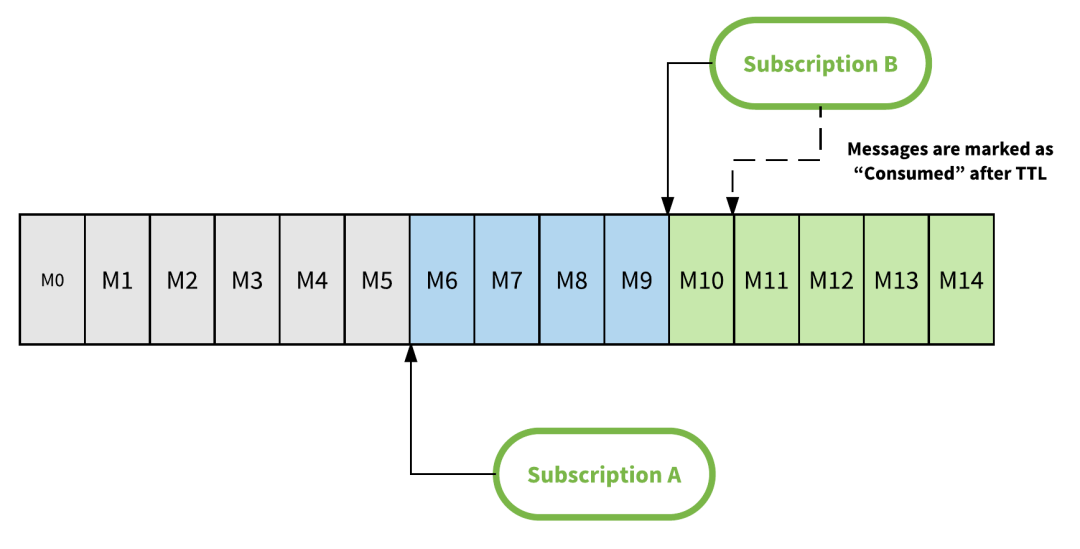
Pulsar 的消息保留(Retention)
Pulsar VS. Kafka
模型概念
消费模式
消息确认(Ack)
消息保留
对比总结
本文内容节选自InfoQ:
https://www.infoq.cn/article/1UaxFKWUhUKTY1t_5gPq
评论