
实战 | keras-yolov3 + Kalman-Filter 进行人体多目标追踪(含代码)
共 2830字,需浏览 6分钟
· 2021-10-26
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|计算机视觉联盟

今天给大家分享一个非常棒非常炫酷的github项目,基于yolov3+Kalman-Filter 的人体多目标跟踪算法。
先看一些效果图,先睹为快,亲测简单好用,大家可以基于这个项目进行优化。
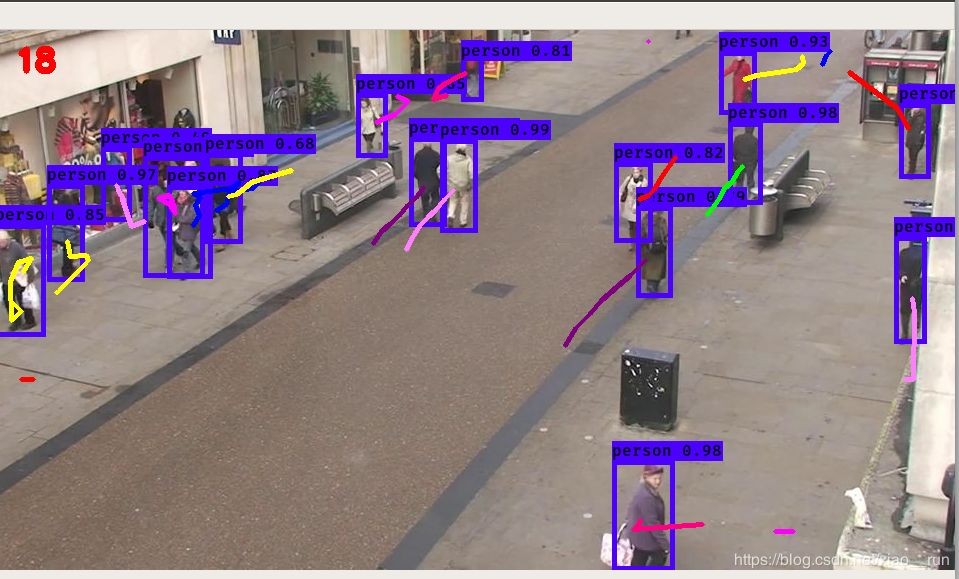
蓝色的框为检测到的人,每个框后面的线为移动轨迹。

原理大概就是 先定位到人,然后对人进行跟踪。
其中一种简单的多目标跟踪方式:detector+tracker,两者其实是相对独立的。
大致原理图如下所示:
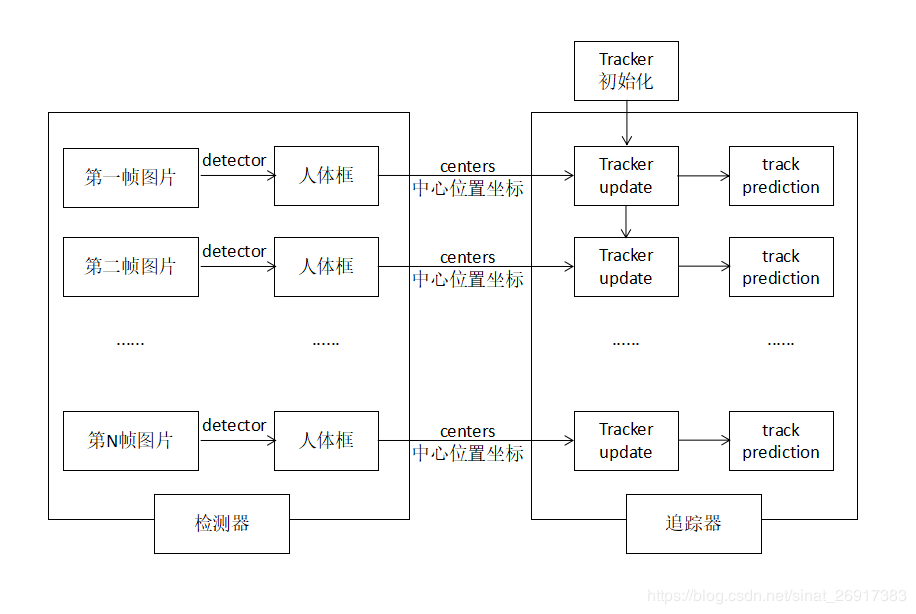
这是原作者画的一个草图,这里的流程就是,图片经过detector,得到人体坐标框,然后计算中心点位置centers(x0,y0),将该centers(x0,y0)输入给追踪器,追踪器去学习(Update)并给出预测。
其中每一帧的图,tracker都会给出多条轨迹,每条轨迹都可能由若干个点组成。
新的一帧物体中心点centers给入之后,tracker与给出预测值prediction ,同时预测值与实际detections的距离去迭代匈牙利算法匹配(linear_sum_assignment)。
好处:可以任意组合比较好的detector/tracker算法
但是这一整套方法论有非常多的问题:
问题一:
在刚刚检测到新人的时候,第一次轨迹预测的时候容易飘逸(如上面白色框所示)
问题二:
one-stage算法的缺陷是不够稳定,笔者本项目尝试的是keras-yolov3,在开阔场景没问题,但是在一切人密度较大,遮挡物较多,像素不够高清的视频上发现检测器容易遗漏物体,前两帧可以检测,后面几帧断了,然后又续上了。这个时候,detector都出现问题,tracker当然会出现loss丢失掉之前的物体。
一些网友也提出过很多解决方案:
(1)多帧融合;
(2)在第一帧有物体的时候就用快速跟踪的手段取代检测器,雷达与物体bbox匹配。
那先从该项目的KF算法Tracker开始,项目中预设了几个调节选项:
dist_thresh: distance threshold. When exceeds the threshold, track will be deleted and new track is created,距离阈值:超过阈值时,将删除轨迹并创建新轨迹
max_frames_to_skip: maximum allowed frames to be skipped forthe track object undetected,超过多少帧没有识别,就放弃该物体,未检测到的跟踪对象允许跳过的最大帧数,可以设置小一些
max_trace_lenght: trace path history length
trackIdCount: identification of each track object,每个跟踪对象的标识基数(在此之上累加)

来看看修复问题的点是,红框标出的,首次检测的飘逸轨迹,那么飘逸轨迹的特点是首尾两点距离较远,那么通过计算两个端点欧式距离,并通过设定阈值来屏蔽掉一些飘逸轨迹。一开始可能使用简单些的方法,诸如使用Harris Corners之类的算法提取关键点。然后,我们可以尝试根据欧几里德距离之类的相似度量来匹配相应的关键点。我们知道,角点(corner)有一个很好的属性:它们对旋转是不变的。 这意味着,一旦我们检测到一个角点,如果我们旋转图像,那个角点仍将存在。
用keras-yolov3训练yolov3模型,该项目也是有预训练模型,但是分类有80分类,不仅仅是定位到人的。所以,简单的只挑出人物框,计算中心值给入tracker即可。
当然,这里其他物体框还是保留的,只是对图像中的人物进行多目标跟踪。
详细代码和参考链接如下:
https://blog.csdn.net/sinat_26917383/article/details/86557399 https://github.com/mattzheng/keras-yolov3-KF-objectTracking https://github.com/Smorodov/Multitarget-tracker https://github.com/srianant/kalman_filter_multi_object_tracking
如果仅对人体检测,只需修改 yolo_matt.py中的 第134行部分修改成如下内容即可:
for i, c in reversed(list(enumerate(out_classes))):predicted_class = self.class_names[c]# 修改内容,添加一个label的判断,只显示人if predicted_class != 'person':continuebox = out_boxes[i]score = out_scores[i]
END
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~