
超级嵌入式系统“性能/时间”工具箱
没有y
【开篇就白给?】
精确测量系统性能
精确测量函数执行时间
精确测量中断响应延迟
提供精确到us级的阻塞或非阻塞的延时服务
改善伪随机数的随机数特性
提供系统时间戳
……
使用了SysTick却不会占用SysTick;
或者说提供以上功能的同时,用户的原有的SysTick应用(比如RTOS调度器或是普通的应用延时)丝毫不会受到影响;
再直白点说:以上功能都是白送的,每个Cortex-M处理器都能立即享有,且不受到芯片型号的影响,
你是不是要直呼:“真就白给?”
是的!作为一个在Github上开源的C语言模块,它真就白给!
【请张嘴……啊~】
在确认了开原许可Apache 2.0的条款后,一路Next,直到单击Finish,完成整个安装过程:
一般来说,部署会非常顺利,但如果出现了安装错误,比如下面这种:
则很可能是您所使用的MDK版本太低导致的——是时候更新下MDK啦。关注【裸机思维】公众号后发送关键字"MDK",即可获得最新的MDK网盘链接。
当我们想在任何已有工程中部署perf_counter时,只需要单击MDK工具栏上如下图所示的图标:

打开RTE配置窗口:
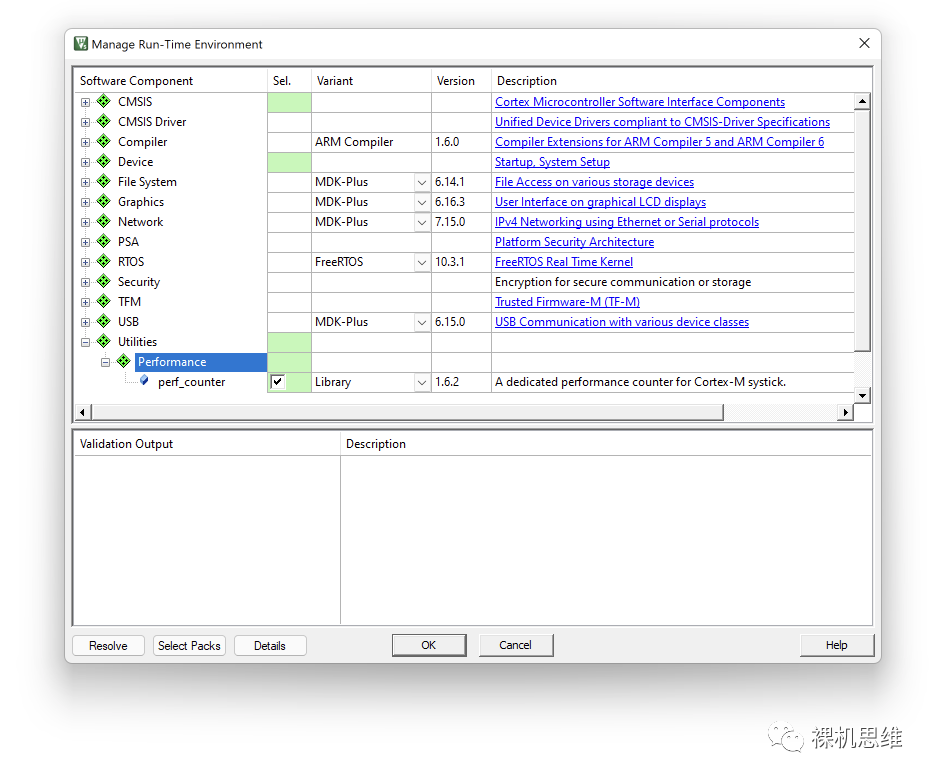
我们会注意到,在列表的末端出现了一个Utilities条目,依次展开后勾选Performance下的perf_counter——默认情况下系统会自动选择以库的形式来实现模块的部署——这也是我吐血推荐的方式,因为它省去了不必要的编译麻烦。
单击OK按钮后,我们会发现Utilities已经被加入到了工程管理器中,而perf_counter.lib也已经成功的部署到了目标工程中:
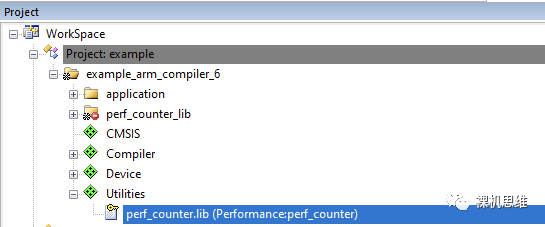
看过我往期文章《【教程】如何用GCC“零汇编”白嫖MDK》的小伙伴一定知道,MDK也可以使用GCC作为编译器。perf_counter也将这种情况考虑在内——当用户实际使用的是GCC时,对应的 libperf_counter_gcc.a(而不是arm compiler 5或arm compielr 6下的perf_counter.lib)会被加入到工程中。
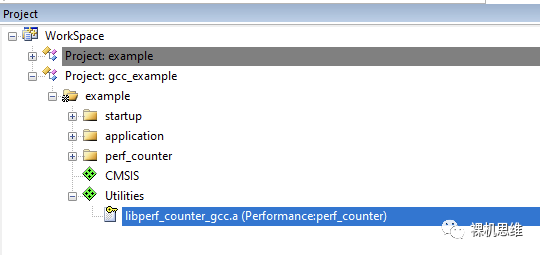
GCC环境下使用perf_counter略微有一些注意事项,由于在文章《【教程】如何用GCC“零汇编”白嫖MDK》的末尾已经有过非常详尽的介绍,这里就不再赘述了。
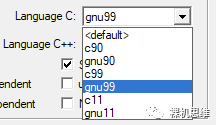
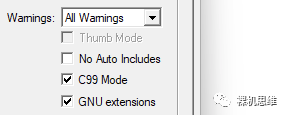
【一键终结甜咸之争?】

“……往往要親眼看着黃酒從罎子裏舀出,看過壺子底裏有水沒有,又親看將壺子放在熱水裏,然後放心……” https://zh.m.wikisource.org/zh/%E5%AD%94%E4%B9%99%E5%B7%B1


此时,相关的perf_counter.c和systick_wrapper_ual.s会取代原本的库文件加入到编译中:
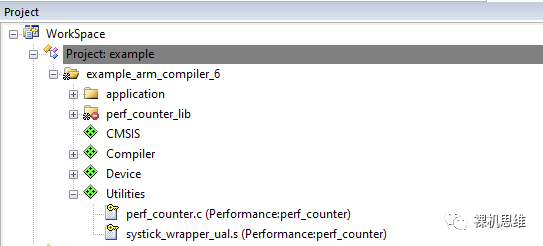
当然,使用Source方式来编译也是有代价的,即perf_counter的源代码对CMSIS有依赖——当你的工程中并未在RTE配置界面中勾选CMSIS-CORE,就会出现类似下图所示的黄色警告信息:“Additional software components required”。
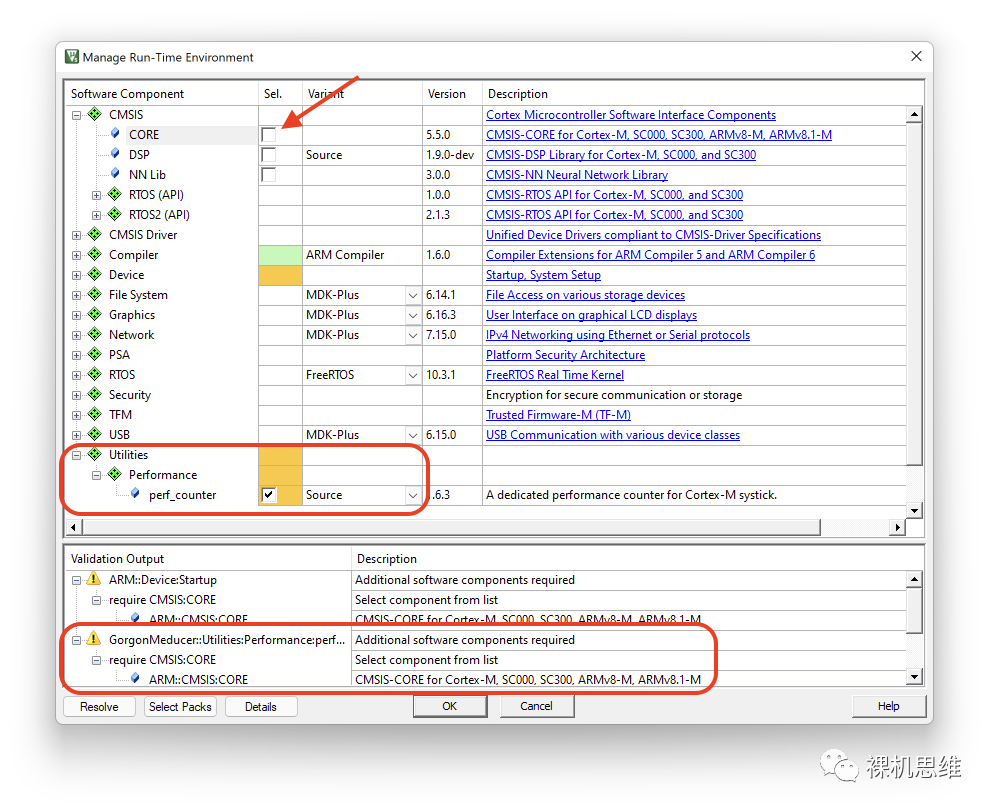
此时,你可以简单的单击Resolve按钮来解决问题——你会发现,所谓的解决方案就是RTE自动把Source模式依赖的CMSIS-CORE帮你勾选上了而已:
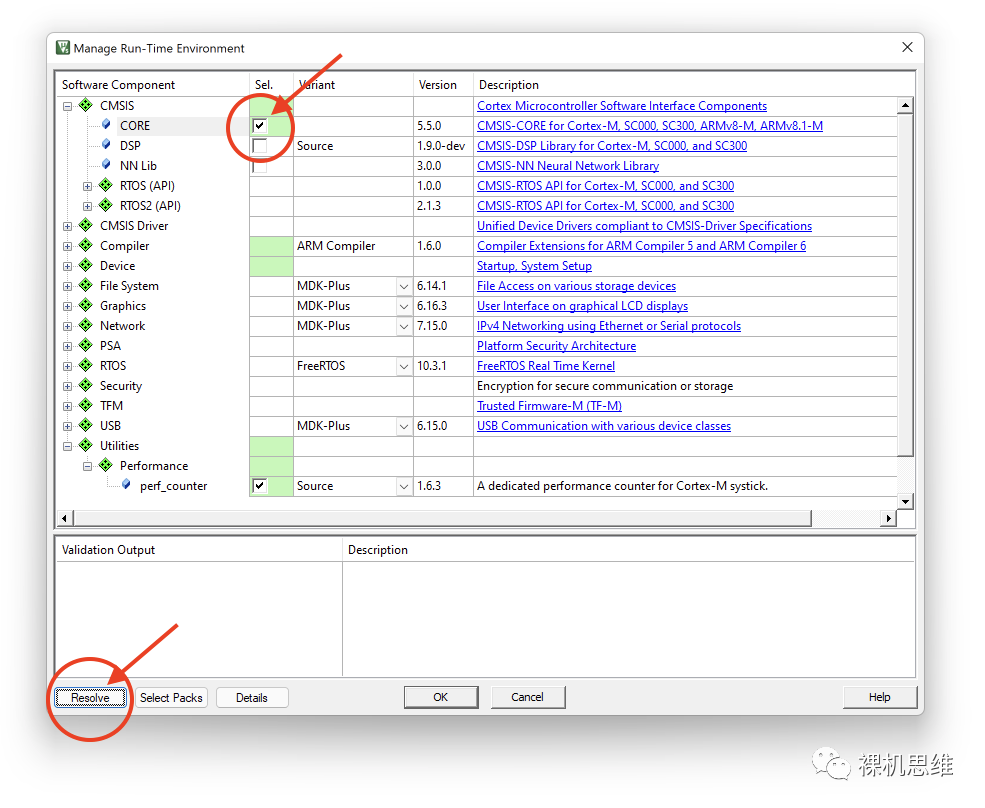
如果你对此并无异议,则问题圆满解决;如果你的系统中存在别的版本的CMSIS(比如很多正点原子、野火、以及CubeMX生成的工程都很可能会携带不经由RTE配置界面来管理的CMSIS),则很有可能出现CMSIS版本冲突——而关于冲突的解决方案,则稍微复杂一些——你可以参考我的文章《CMSIS玩家的“阴间成就”指南》来实现某种取舍……又或者……
【一键更新的……嵌入式软件模块?】
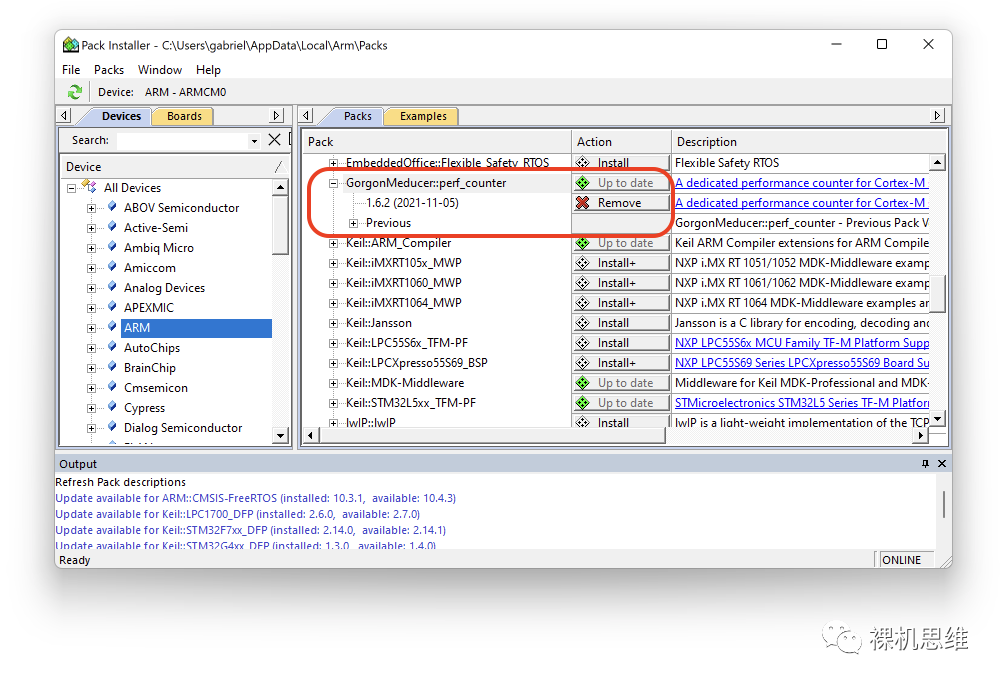
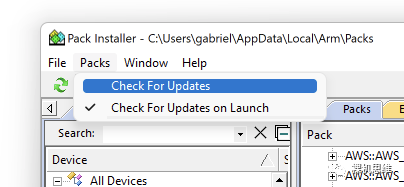
如果Pack-Installer真的从github上发现了更新,就会以黄色Update的图标来告知我们:
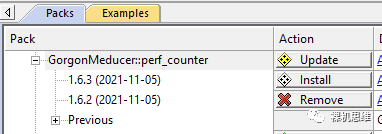
此时,单击Update按钮,即可安装最新版本:
那么,如何才能鼓励博主多多更新、加入更多更好的功能呢?
当然还是要靠有能力科学上网的小伙伴多多Star呀!
【库的初始化和注意事项】
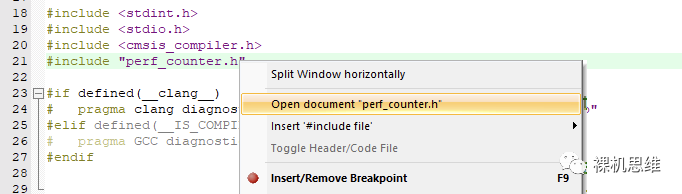
#include "perf_counter.h"需要注意的是,通过RTE方式部署的perf_counter并不会在工程管理器中引入 perf_counter.h 以供用户查看。想要查看perf_counter.h查找可用API的小伙伴,可以“简单的”在上述代码行上单击右键,从弹出菜单中选择“Open document 'perf_counter'” 来实现对头文件的访问。
extern uint32_t SystemCoreClock;void main(void){system_clock_update(); //! 更新CPU工作频率SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz...}
一般来说,你的芯片工程如果本身都是基于较新的CMSIS框架而创建的,你的启动文件中已经为你定义好了全局变量 SystemCoreClock——当然,凡事都有例外,如果你在编译的时候报告找不到变量 SystemCoreClock 或者说“Undefined symbol __SystemCoreClock” 之类的,你自己定义一下就好了,比如:
uint32_t SystemCoreClock;void main(void){system_clock_update(); //! 更新CPU工作频率SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz...}
在这以后,我们需要对 perf_counter 库进行初始化。这里分两种情况:
1、用户自己的应用里完全没有使用SysTick。此时,在编译时,我们多半会看到类似如下的错误提示:

Error: L6218E: Undefined symbol $Super$$SysTick_Handler (referred from systick_wrapper_ual.o).
对于这种情况,我们需要在任意的C文件中添加一个SysTick中断处理程序:
#include "perf_counter.h"...__attribute__((used)) //!< 避免下面的处理程序被编译器优化掉void SysTick_Handler(void){}
然后我们在 main() 函数里初始化 perf_counter 服务:
#include <stdbool.h>...void main(void){system_clock_update(); //! 更新CPU工作频率SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHzinit_cycle_counter(false);...}
需要特别注意的是:由于用户并没有自己初始化 SysTick,因此我们需要将这一情况告知 perf_counter 库——由它来完成对 SysTick 的初始化——这里传递 false 给函数 init_cycle_counter() 就是这个功能。如果由perf_counter 库自己来初始化SysTick,它会为了自己功能更可靠将 SysTick的溢出值(LOAD寄存器)设置为最大值(0x00FFFFFF)。
2、用户自己的应用里使用了SysTick,拥有自己的初始化过程。对于这种情况,我们需要确保一件事情:即,SysTick的CTRL寄存器的 BIT2(SysTick_CTRL_CLKSOURCE_Msk)是否被置位了——如果其值是1,说明SysTick使用了跟CPU一样的工作频率,那么SysTick的测量结果就是CPU的周期数;如果其值是0,说明SysTick使用了来自于别处的时钟源,这个时钟源具体频率是多少就只能看芯片手册了(比如STM32就喜欢将系统频率做 1/8 分频后提供给SysTick作为时钟源),此时SysTick测量出来的结果就不是CPU的周期数。
在确保了 CTRL 寄存器的 BIT2 被正确置位,并且SysTick中断被使能(置位 BIT1,SysTick_CTRL_TICKINT_Msk )后,我们可以简单的通过 init_cycle_counter() 函数告诉perf_counter模块:SysTick 被用户占用了——这里传递 true 就实现这一功能。
#...void main(void){system_clock_update(); //! 更新CPU工作频率SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHzinit_cycle_counter(true);...}
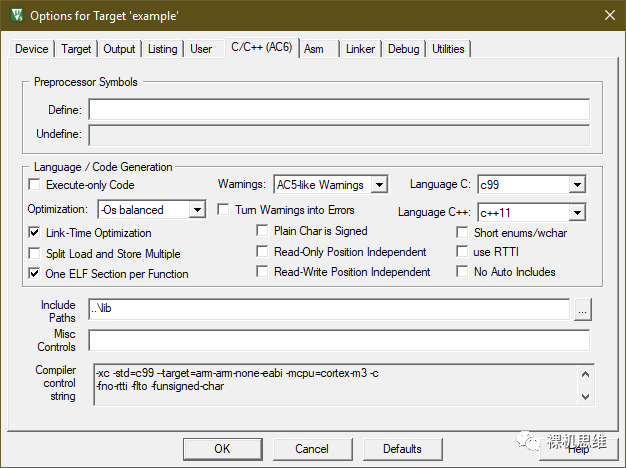
下图的工程配置中,没有勾选 "Short enums/wchar"
你一定会看到这样的编译错误:

.\Out\example.axf: Error: L6242E: Cannot link object perf_counter.o as its attributes are incompatible with the image attributes.... wchart-16 clashes with wchart-32.... packed-enum clashes with enum_is_int.
既然知道了原因,解决方法就很简单,要么在工程配置中勾选上这一选项;要么使用源代码编译的模式。
【时间类服务】
extern void delay_us(int32_t iUs);实际上,由于函数调用的开销,delay_us在时间判断上会存在一个“不积累”的误差——根据优化等级的不同,其具体CPU周期数存在差异,如果我们以Library方式进行部署时,这一误差大约在+/-25个CPU周期左右——这一信息实际上告诉我们:
在使用Library的情况下,当你的CPU频率超过50MHz时,delay_us() 可以提供最小<1us的延时误差;
当你的系统频率不满足上述条件时,以系统频率 12MHz为参考,则可以认为delay_us误差为不积累的 +/- 2us。
具体评估方法,请参考我往期的文章《【实时性迷思】CPU究竟跑的有多快?》,这里就不做赘述。
perf_counter提供了API函数get_system_ticks(),用于方便用户获取自 SysTick启动以来系统已经经历过的总周期数,其函数原型如下:
__attribute__((nothrow))extern int64_t get_system_ticks(void);
可以看到,其返回值是一个 64位的有符号整数,即便抛开符号位,也基本可以确信:无论芯片频率如何,在人类灭绝之前,不会发生溢出问题。

# get_system_ms() \(get_system_ticks() / (SystemCoreClock / 1000ul))# get_system_us() \(get_system_ticks() / (SystemCoreClock / 1000000ul))
机构控制的延时;
电路的时序控制;
通信协议的超时处理;
……
这里的核心思想是:
在延时的开始时刻,通过 get_system_ticks() 的衍生方法 get_system_ms() 来获取当前的系统时间戳;
计算目标时刻的系统时间戳并保存在状态机类中(保存在 iTargetTime里);
在随后的状态中以非阻塞的方式轮询 get_system_ms() 以检查约定的时间是否已经到来。
下面的状态图展示了如何在执行某些动作(或者子状态机)的同时,进行超时判断:
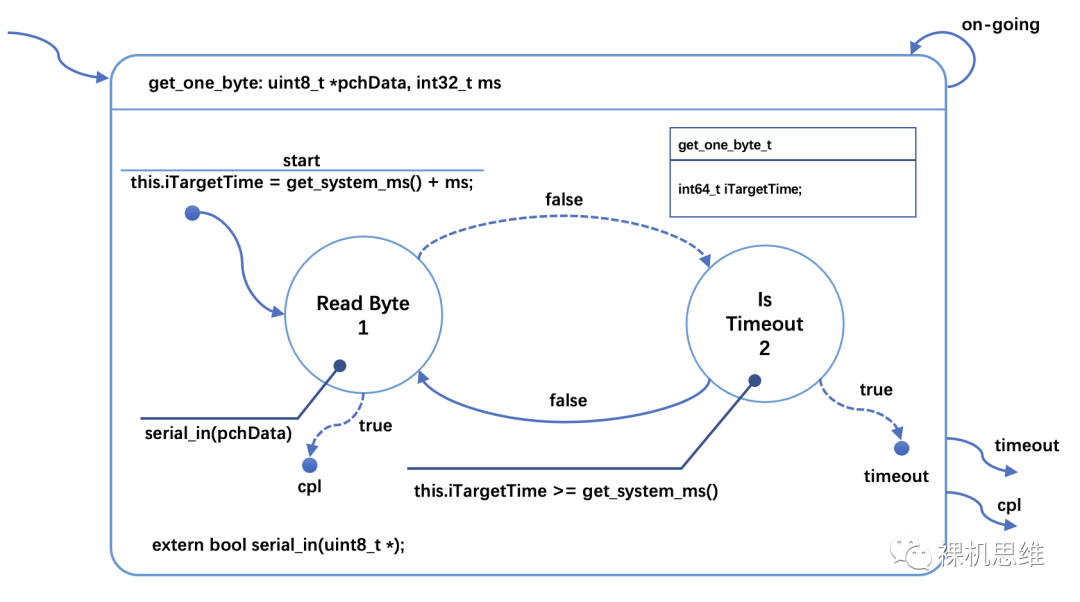
这里值得注意的细节是:
在延时的开始时刻,通过 get_system_ticks() 的衍生方法 get_system_ms() 来获取当前的系统时间戳;
计算目标时刻的系统时间戳并保存在状态机类中(保存在 iTargetTime里);
在读取字符失败时,通过对比当前的系统时间戳来判断是否超时。
几乎所有的C语言教程都在介绍过随机数的发生,比如:
#include <stdio.h>#include <stdlib.h>int main (void){int i, n;time_t t;n = 5;/* Intializes random number generator */srand((unsigned) time(&t));/* Print 5 random numbers from 0 to 49 */for( i = 0 ; i < n ; i++ ) {printf("%d\n", rand() % 50);}return(0);}
srand((unsigned)get_system_ticks());
【嵌入式C语言扩展】
//! 执行 紧随其后的printf语句时,暂时性的屏蔽全局中断__IRQ_SAFE printf("hellow world!");//! 执行花括号内的代码时,暂时性的屏蔽全局中断__IRQ_SAFE {...}//! 想提前结束时,可以用continue;__IRQ_SAFE {...if (某些条件) {//! 我们需要提前结束continue;}//! 条件性跳过的操作...}
__IRQ_SAFE在使用时,有以下注意事项:
它只能用于函数内部,不可以用来修饰函数或者变量;
它支持嵌套
有些小伙伴在进行软件开发时,可能会因为这样或者那样的原因,需要能够稳定可靠的检测出当前所使用的编译器,比如 Arm Compiler 5、Arm Compiler 6、GCC等等。
perf_counter 提供了一系列统一格式的宏,有效的解决了上述问题。它们是:
__IS_COMPILER_ARM_COMPILER_5____IS_COMPILER_ARM_COMPILER_6____IS_COMPILER_GCC____IS_COMPILER_LLVM____IS_COMPILER_IAR__
这些宏仅会在检测到对应编译器时被定义。一个典型的用法如下:
#if defined(__IS_COMPILER_IAR__)__attribute__((constructor))#else__attribute__((constructor(255)))#endifvoid __perf_counter_init(void){init_cycle_counter(true);}
这里,__attribute__((constructor)) 的作用在于告诉编译器“请在执行main函数前执行被它修饰的函数”。这是一个GCC扩展,为大部分编译器广泛接受和支持,但由于IAR的在语法上并不支持存在多个函数时排队用的序号,因此需要与其它编译器区别处理。
# TPASTE(a,b) a##b但这里其实存在一些问题,这类问题在我的文章《【为宏正名】本应写入教科书的“世界设定”》中有详细讲解,这里就不再赘述。单纯从功能上来讲,TPASTE只能完成2个名称的“粘合”,如果是多个呢?如果要粘合的名称数量不去定呢?perf_counter就提供了这样一个解决方案 CONNECT(),并具有以下优势:
黏合的数量可以是变化的
最大支持黏合9个片断
比如,我们想生成一个安全的临时名称,则可以试着将代码所在行号__LINE__、下划线以及用户指定的后缀黏合在一起:
#define __SAFE_NAME(__NAME) \CONNECT(__,__LINE__,_,__NAME)
比如,下面的代码:
# measure_time(...) \({ \int64_t __SAFE_NAME(StartTime) = get_system_ticks();\__VA_ARGS__; \get_system_ticks() - __SAFE_NAME(StartTime); \})int32_t iCycleUsed =measure_time(printf("Hello world!\r\n"););
假设measure_time所在的行号为123,则实际对应的代码为:
int32_t iCycleUsed =({= get_system_ticks();__VA_ARGS__;get_system_ticks() - __123_StartTime;});
该代码的作用是测量 measure_time()的圆括号内的代码块所用时间,并作为表达式的值返回。这里用到了GCC的一个被称为“Statements and Declarations in Expressions”的语法扩展,感兴趣的小伙伴可以参考下面的链接:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];int16_t get_average_voltage(void){int32_t nTotal = 0;for (int32_t n = 0; n < ADC_BUFFER_SIZE; n++) {n += s_iADCBuffer[n];}return nTotal / ADC_BUFFER_SIZE;}
在这个简单的例子中,for循环的作用就是枚举数组 s_iADCBuffer 中的每一个元素。很多高级语言(甚至是Linux内核代码),都引入了专门的 foreach 关键字来实现这样的数据枚举功能,perf_counter也不能免俗,其语法为:
foreach (<数组元素的类型>,<数组名称>) {...}
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];int16_t get_average_voltage(void){int32_t nTotal = 0;foreach (volatile int16_t, s_iADCBuffer) {nTotal += *_;}return nTotal / ADC_BUFFER_SIZE;}
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];int16_t get_average_voltage(void){int32_t nTotal = 0;foreach (volatile int16_t, s_iADCBuffer, piItem) {nTotal += *piItem;}return nTotal / ADC_BUFFER_SIZE;}
foreach (<数组元素的类型>,<数组名称>,<枚举元素名称>) {...}
换句话说,用户可以通过第三个参数指定枚举元素的变量名称了,是不是一下就清晰了很多?
【如何测量代码片断占用了多少CPU资源】
perf_counter 提供了一个非常简单的运算符:__cycleof__()。假设我们要测量的代码片断如下:
...my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();...
...__cycleof__("my algorithm") {my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}...

有的小伙伴很快会说,我的系统并不允许我调用printf,那我还可以使用 __cycleof__() 么?当然了!就继续以上述代码为例子:
int32_t nCycleUsed = 0;...__cycleof__("my algorithm", {nCycleUsed = _;}) {my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}...
测量了用户函数 my_algorithm_step_xxx() 所使用的周期数:
测量的结果被转存到了一个叫做 nCycleUsed 的变量中;
__cycleof__() 将不会调用 printf() 进行任何内容输出。

首先,为了方便大家观察,我们先忽略圆括号内的部分:
...__cycleof__(...) {my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}...
接下来,我们专门来看__cycleof__() 圆括号中的部分:
int32_t nCycleUsed = 0;...__cycleof__("my algorithm", {nCycleUsed = _;}){...}...
"my algorithm"{nCycleUsed = _;}你可以写任意数量的代码
你可以调用函数
你可以定义变量(当然这里定义变量肯定就是局部变量了)
但我们一般要做的事情其实是通过__cycleof__() 所定义的一个局部变量"_"来获取测量结果——这也是下面代码的本意:
nCycleUsed = _;int32_t nCycleUsed = 0;...__cycleof__("my algorithm", {nCycleUsed = _;}) {my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}printf("Cycle Used %d", _);
int32_t nCycleUsed = 0;...__cycleof__("my algorithm", {nCycleUsed = _;printf("Cycle Used %d", _);}) {my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}
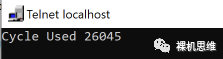
则会看到你心怡的输出结果:
int32_t nCycleUsed = 0;...do {int64_t _ = get_system_ticks();{my_algorithm_step_a();my_algorithm_step_b();...my_algorithm_step_c();}_ = get_system_ticks() - _;//! 我们添加的代码nCycleUsed = _;printf("Cycle Used %d", _);} while(0);
起核心作用的是一个叫做 get_system_ticks() 的函数。实际上它返回的是从复位后 SysTick被使能至今所经历的 CPU 周期数——由于它是int64_t 的类型,因此不用担心超过 SysTick 24位计数器的量程,也不用担心人类历史范围内会发生溢出的可能。 知道这一点后,聪明的小伙伴就可以自己整活儿了。
由于 "_" 是一个局部变量,因此可以判断 __cycleof__() 是支持嵌套的。
需要特别说明的是,get_system_tick() 函数自己也是有CPU时钟开销的,所以如果要获得较为精确的结果,推荐通过下面的方法来获取校准值:
static int64_t s_lPerfCalib;void calib_perf_counter(void) {int64_t lTemp = get_system_tick();s_lPerfCalib = get_system_tick() - lTemp;}int64_t get_perf_counter_calib(void){return s_lPerfCalib;}
int32_t nCycles = 0;start_cycle_counter(); //!< 开始总计时...nCycles = stop_cycle_counter(); //!< 第一次获取从开始以来的时间...nCycles = stop_cycle_counter(); //!< 第二次获取从开始以来的时间...nCycles = stop_cycle_counter(); //!< 第三次获取从开始以来的时间...
值得强调的是虽然 start_cycle_counter() 和 stop_cycle_counter() 有 start 和 stop 的字样,但这只有逻辑上的意义而并不会真正的干扰 SysTick 的功能(也就是不会开启或者关闭 SysTick)。这也是这个库敢于声称自己不会影响用户已有的 SysTick 功能的原因。
【说在后面的话】

如果你喜欢我的思维、觉得我的文章对你有所启发,
请务必 “点赞、收藏、转发” 三连,这对我很重要!谢谢!
欢迎订阅 裸机思维