
敖丙怎么连Flink的背压都不懂,太菜了吧?
三歪第402篇原创文章
作者:三歪
本文已收录至我的GitHub
最近一直在迁移Flink相关的工程,期间也踩了些坑,checkpoint和反压是其中的一个。
敖丙太菜了,Flink都不会,只能我自己来了。
看敖丙只能图一乐,学技术还是得看三歪
平时敖丙黑我都没啥水平,拿点简单的东西来就说我不会,麻烦专业点@敖丙。
今天来分享一下 Flink的checkpoint机制和背压原理,我相信通过这篇文章,大家在玩Flink的时候可以更加深刻地了解Checkpoint是怎么实现的,并且在设置相关参数以及使用的时候可以更加地得心应手。
上一篇已经写过Flink的入门教程了,如果还不了解Flink的同学可以先去看看:《Flink入门教程》
前排提醒,本文基于Flink 1.7
《浅入浅出学习Flink的背压知识》
开胃菜
在讲解Flink的checkPoint和背压机制之前,我们先来看下checkpoint和背压的相关基础,有助于后面的理解。
作为用户,我们写好Flink的程序,上管理平台提交,Flink就跑起来了(只要程序代码没有问题),细节对用户都是屏蔽的。
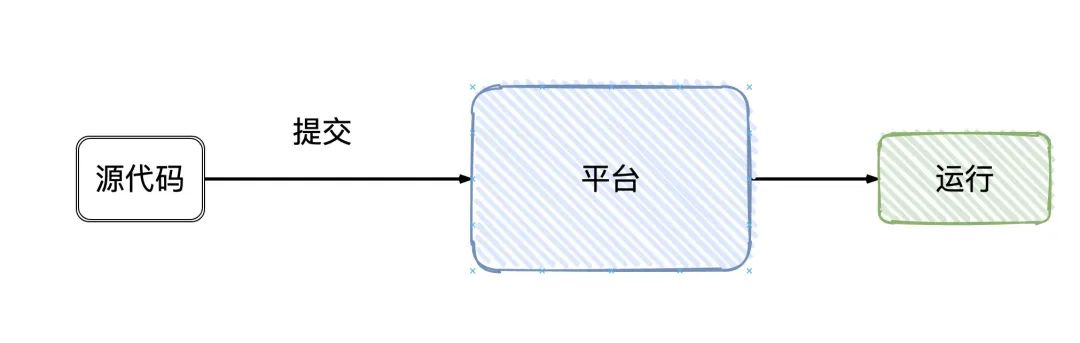
实际上大致的流程是这样的:
Flink会根据我们所写代码,会生成一个StreamGraph的图出来,来代表我们所写程序的拓扑结构。然后在提交的之前会将 StreamGraph这个图优化一把(可以合并的任务进行合并),变成JobGraph将 JobGraph提交给JobManagerJobManager收到之后JobGraph之后会根据JobGraph生成ExecutionGraph(ExecutionGraph是JobGraph的并行化版本)TaskManager接收到任务之后会将ExecutionGraph生成为真正的物理执行图
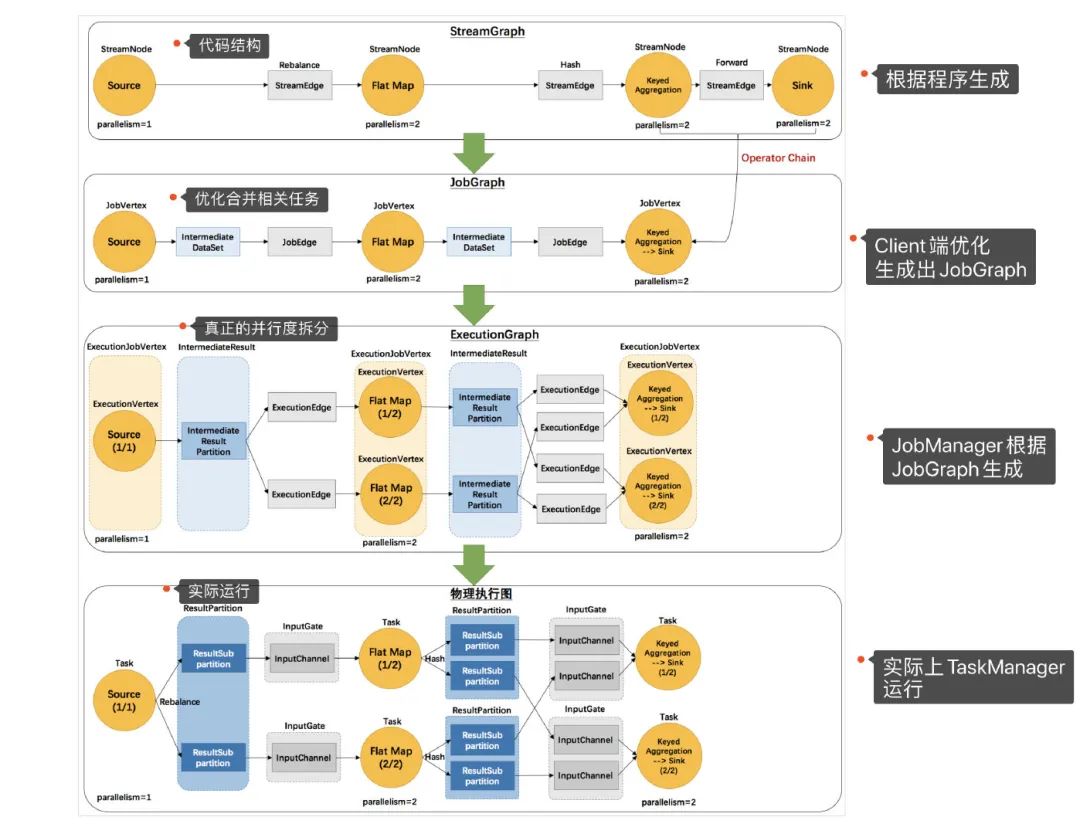
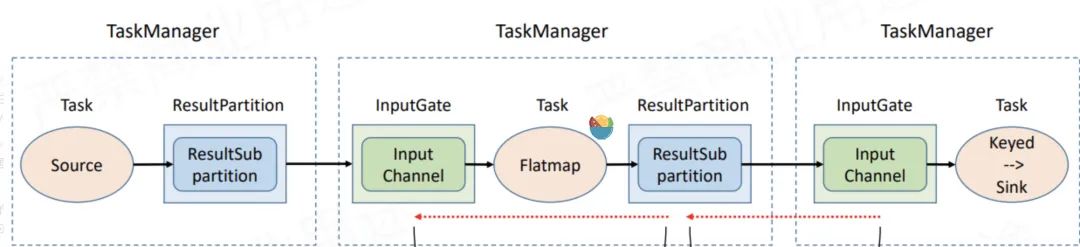
可以看到物理执行图真正运行在TaskManager上Transform和Sink之间都会有ResultPartition和InputGate这俩个组件,ResultPartition用来发送数据,而InputGate用来接收数据。
屏蔽掉这些Graph,可以发现Flink的架构是:Client->JobManager->TaskManager

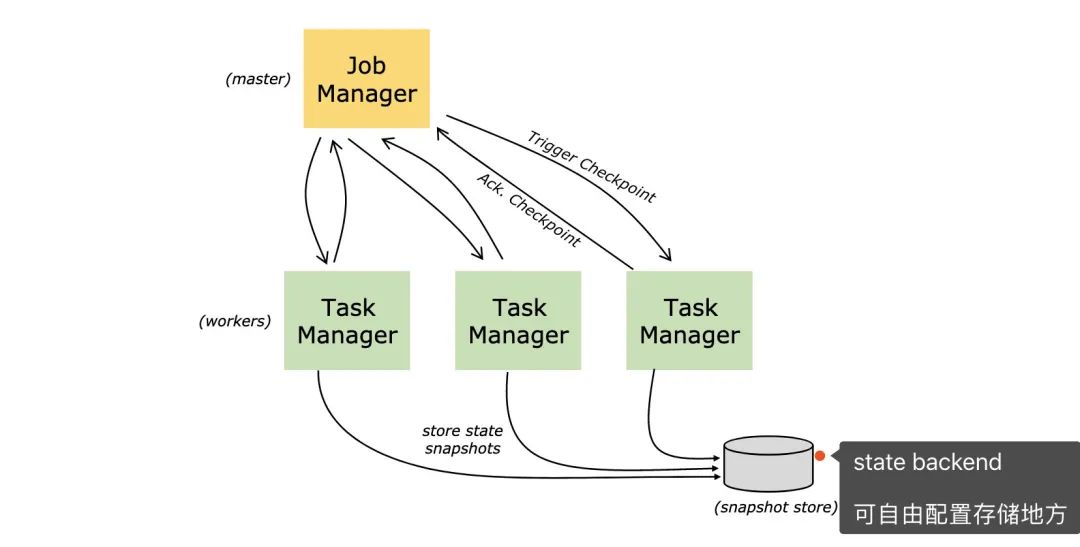
从名字就可以看出,JobManager是干「管理」,而TaskManager是真正干活的。回到我们今天的主题,checkpoint就是由JobManager发出。
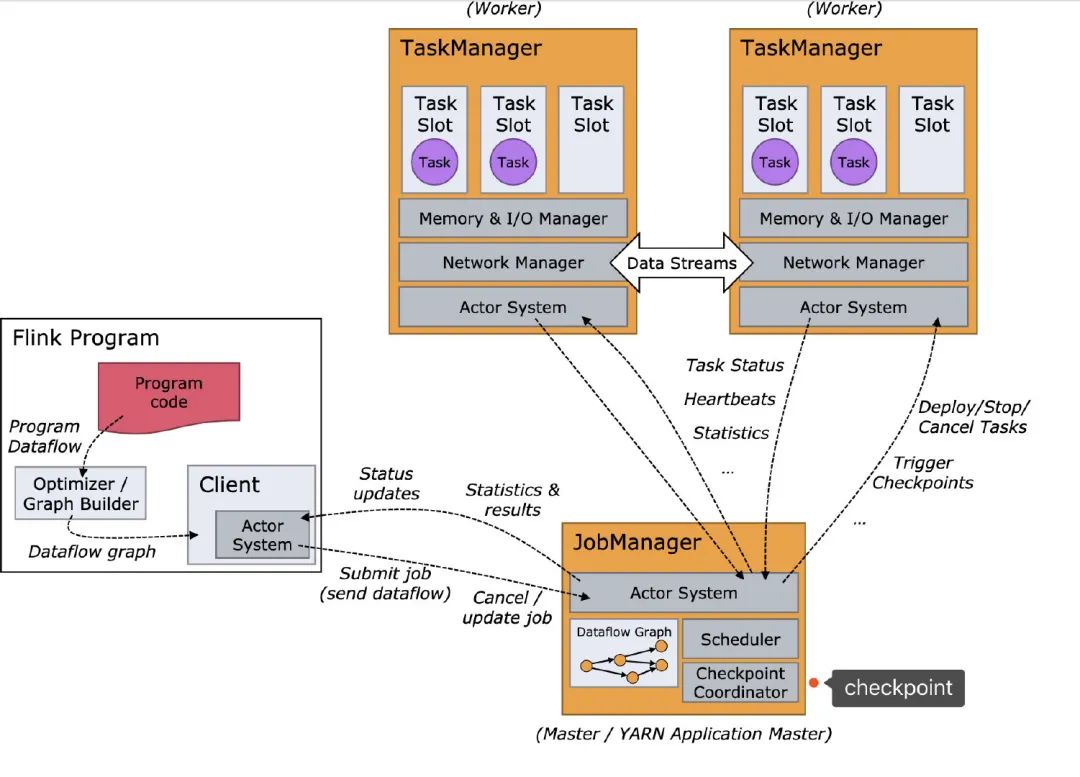
而Flink本身就是有状态的,Flink可以让你选择执行过程中的数据保存在哪里,目前有三个地方,在Flink的角度称作State Backends:
MemoryStateBackend(内存) FsStateBackend(文件系统,一般是HSFS) RocksDBStateBackend(RocksDB数据库)
同样的,checkpoint信息也是保存在State Backends上
耗子屎
最近在Storm迁移Flink的时候遇到个问题,我来简单描述一下背景。
我们从各个数据源从清洗出数据,借助Flink清洗,组装成一个宽模型,最后交由kylin做近实时数据统计和展示,供运营实时查看。
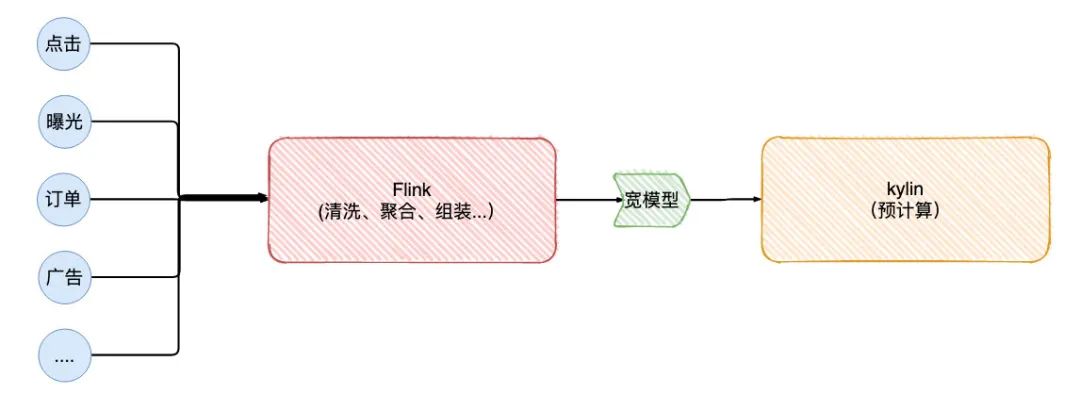
迁移的过程中,发现订单的topic消费延迟了好久,初步怀疑是因为订单上游的并发度不够所影响的,所以调整了两端的并行度重新发布一把。
发布的过程中,系统起来以后,再去看topic 消费延迟的监控,就懵逼了。什么?怎么这么久了啊?丝毫没有降下去的意思。
这时候只能找组内的大神去寻求帮忙了,他排查一番后表示:这checkpoint一直没做上,都堵住了,重新发布的时候只会在上一次checkpoint开始,由于checkpoint长时间没完成掉,所以重新发布数据量会很大。这没啥好办法了,只能在这个堵住的环节下扔掉吧,估计是业务逻辑出了问题。
画外音:接收到订单的数据,会去溯源点击,判断该订单从哪个业务来,经过了哪些的业务,最终是哪块业务致使该订单成交。
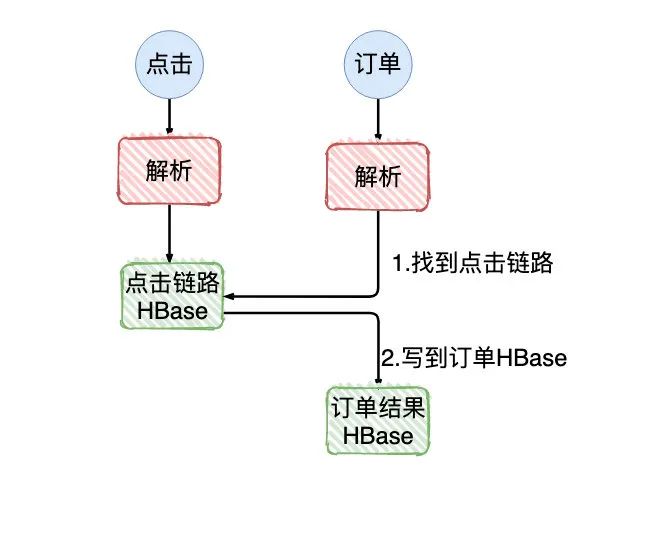
画外音:外部真正使用时,依赖「订单结果HBase」数据
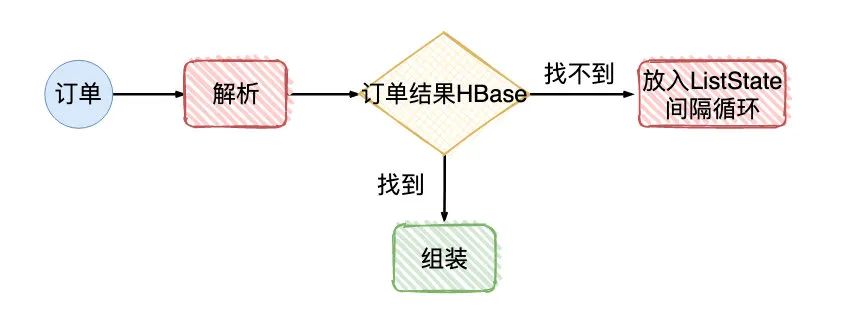
我们认为点击的数据有可能会比订单的数据处理要慢一会,所以找不到的数据会间隔一段时间轮询,又因为Flink提供State「状态」 和checkpoint机制,我们把找不到的数据放入ListState按一定的时间轮询就好了(即便系统由于重启或其他原因挂了,也不会把数据丢了)。
理论上只要没问题,这套方案是可行的。但现在结果告诉我们:订单数据报来了以后,一小批量数据一直在「订单结果HBase」没找到数据,就放置到ListState上,然后来一条数据就去遍历ListState。导致的后果就是:
数据消费不过来,形成反压 checkpoint一直没成功
当时处理的方式就是把ListState清空掉,暂时丢掉这一部分的数据,让数据追上进度。
后来排查后发现是上游在消息报字段上做了「手脚」,解析失败导致点击丢失,造成这一连锁的后果。
排查问题的关键是理解Flink的反压和checkpoint的原理是什么样的,下面我来讲述一下。
反压
反压backpressure是流式计算中很常见的问题。它意味着数据管道中某个节点成为瓶颈,处理速率跟不上「上游」发送数据的速率,上游需要进行限速
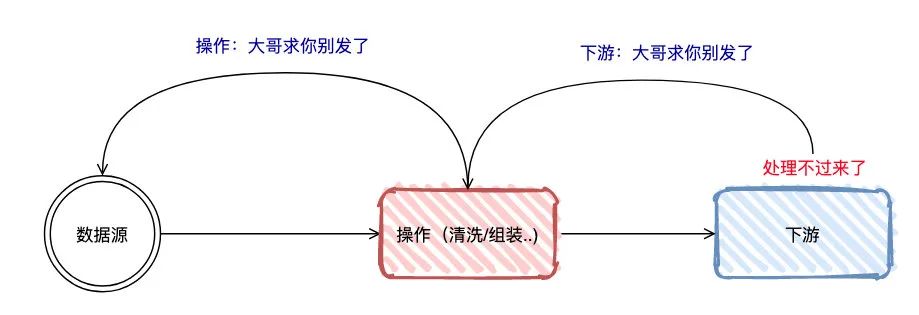
上面的图代表了是反压极简的状态,说白了就是:下游处理不过来了,上游得慢点,要堵了!
最令人好奇的是:“下游是怎么通知上游要发慢点的呢?”
在前面Flink的基础知识讲解,我们可以看到ResultPartition用来发送数据,InputGate用来接收数据。
而Flink在一个TaskManager内部读写数据的时候,会有一个BufferPool(缓冲池)供该TaskManager读写使用(一个TaskManager共用一个BufferPool),每个读写ResultPartition/InputGate都会去申请自己的LocalBuffer
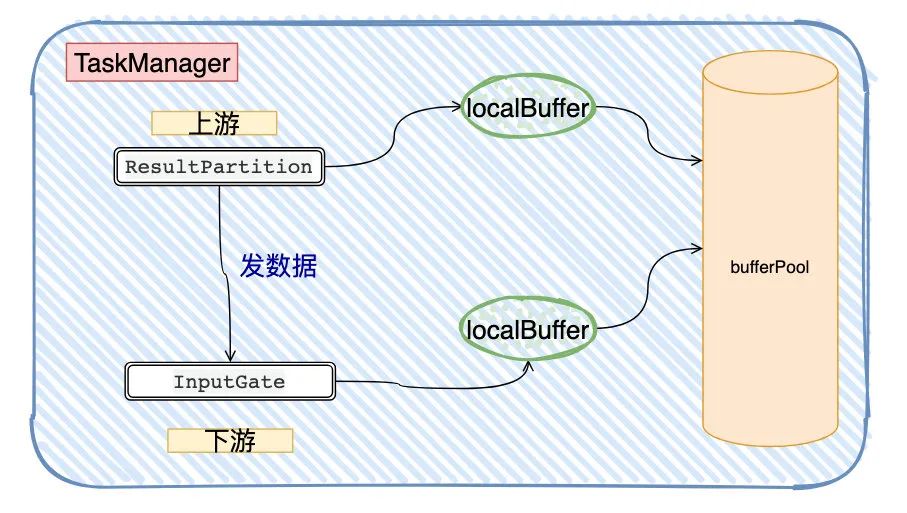
以上图为例,假设下游处理不过来,那InputGate的LocalBuffer是不是被填满了?填满了以后,ResultPartition是不是没办法往InputGate发了?而ResultPartition没法发的话,它自己本身的LocalBuffer 也迟早被填满,那是不是依照这个逻辑,一直到Source就不会拉数据了...
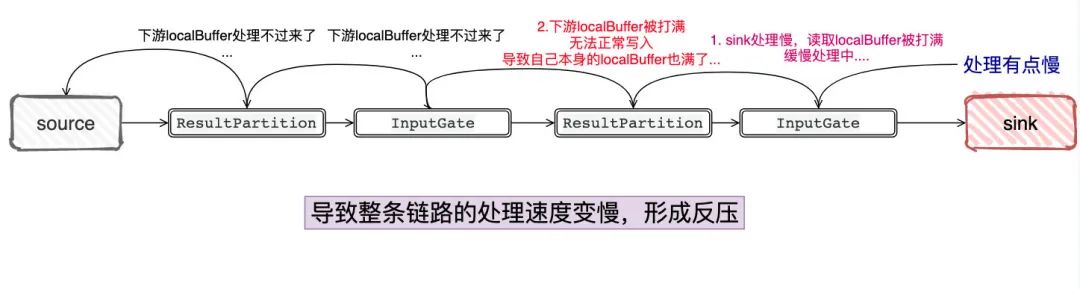
这个过程就犹如InputGate/ResultPartition都开了自己的有界阻塞队列,反正“我”就只能处理这么多,往我这里发,我满了就堵住呗,形成连锁反应一直堵到源头上...
上面是只有一个TaskManager的情况下的反压,那多个TaskManager呢?(毕竟我们很多时候都是有多个TaskManager在为我们工作的)
我们再看回Flink通信的总体数据流向架构图:
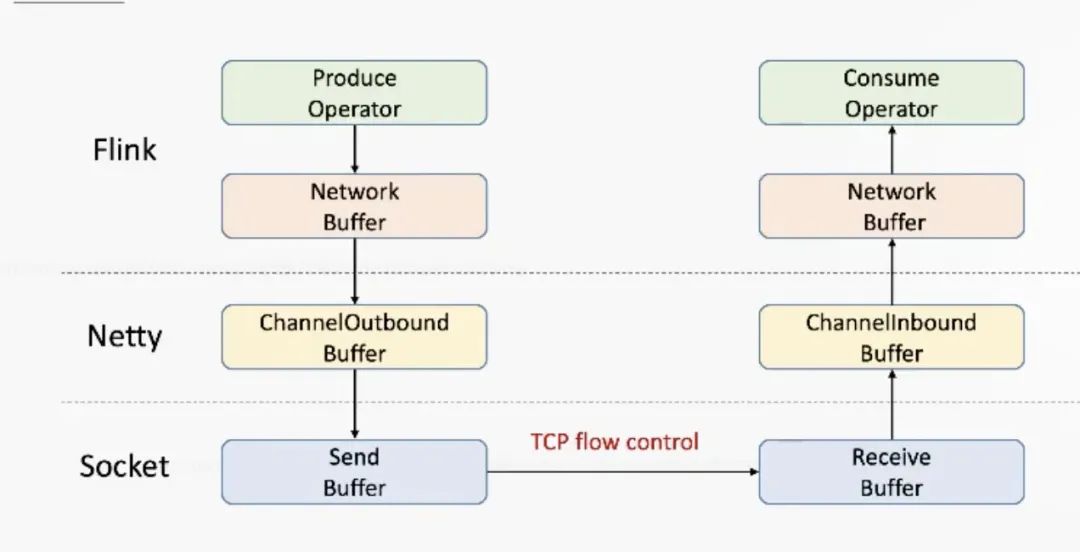
从图上可以清洗地发现:远程通信用的Netty,底层是TCP Socket来实现的。
所以,从宏观的角度看,多个TaskManager只不过多了两个Buffer(缓冲区)。
按照上面的思路,只要InputGate的LocalBuffer被打满,Netty Buffer也迟早被打满,而Socket Buffer同样迟早也会被打满(TCP 本身就带有流量控制),再反馈到ResultPartition上,数据又又又发不出去了...导致整条数据链路都存在反压的现象。
现在问题又来了,一个TaskManager的task可是有很多的,它们都共用一个TCP Buffer/Buffer Pool,那只要其中一个task的链路存在问题,那不导致整个TaskManager跟着遭殃?
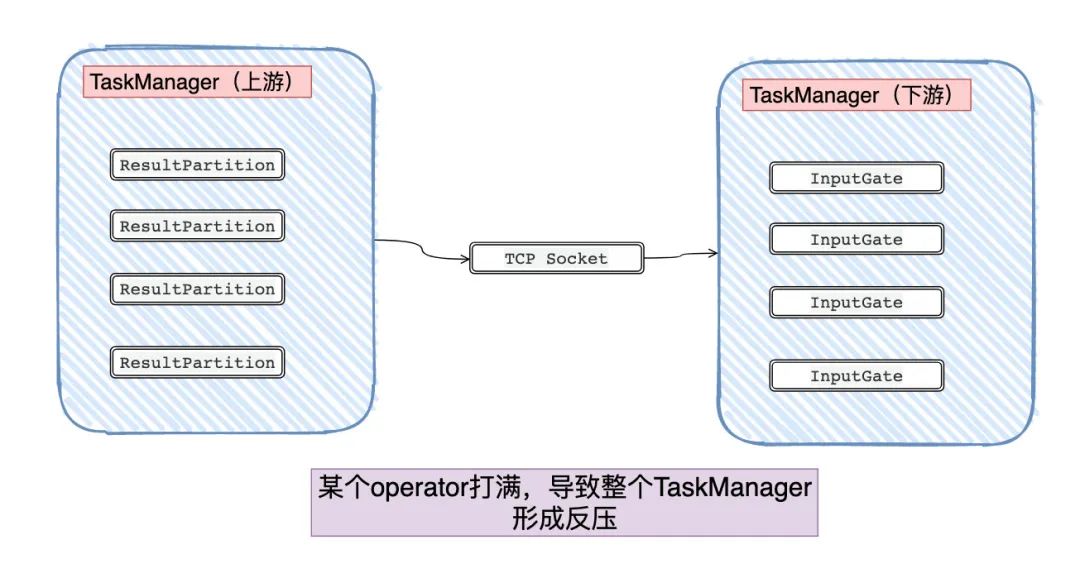
在Flink 1.5版本之前,确实会有这个问题。而在Flink 1.5版本之后则引入了credit机制。
从上面我们看到的Flink所实现的反压,宏观上就是直接依赖各个Buffer是否满了,如果满了则无法写入/读取导致连锁反应,直至Source端。
而credit机制,实际上可以简单理解为以「更细粒度」去做流量控制:每次InputGate会告诉ResultPartition自己还有多少的空闲量可以接收,让ResultPartition看着发。如果InputGate告诉ResultPartition已经没有空闲量了,那ResultPartition就不发了。
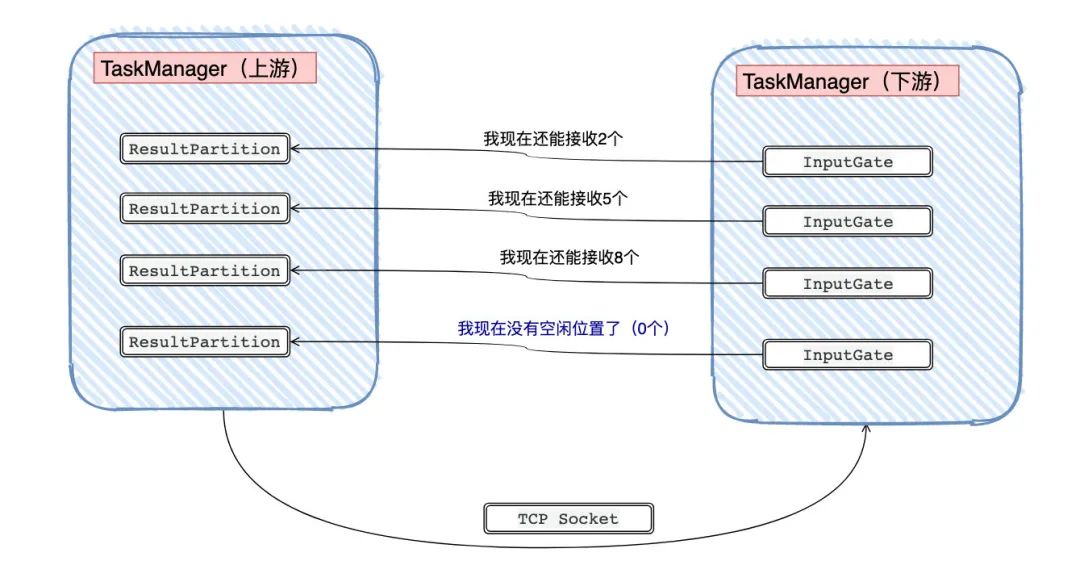
那实际上是怎么实现的呢?撸源码!
在撸源码之前,我们再来看看下面物理执行图:实际上InPutGate下是InputChannel,ResultPartition下是ResultSubpartition(这些在源码中都有体现)。
InputGate(接收端处理反压)
我们先从接收端看起吧。Flink接收数据的方法在org.apache.flink.streaming.runtime.io.StreamInputProcessor#processInput
随后定位到处理反压的逻辑:
final BufferOrEvent bufferOrEvent = barrierHandler.getNextNonBlocked();
进去getNextNonBlocked()方法看(选择的是BarrierBuffer实现):

我们就直接看null的情况,看下从初始化阶段开始是怎么搞的,进去getNextBufferOrEvent()
进去方法里面看到两个比较重要的调用:
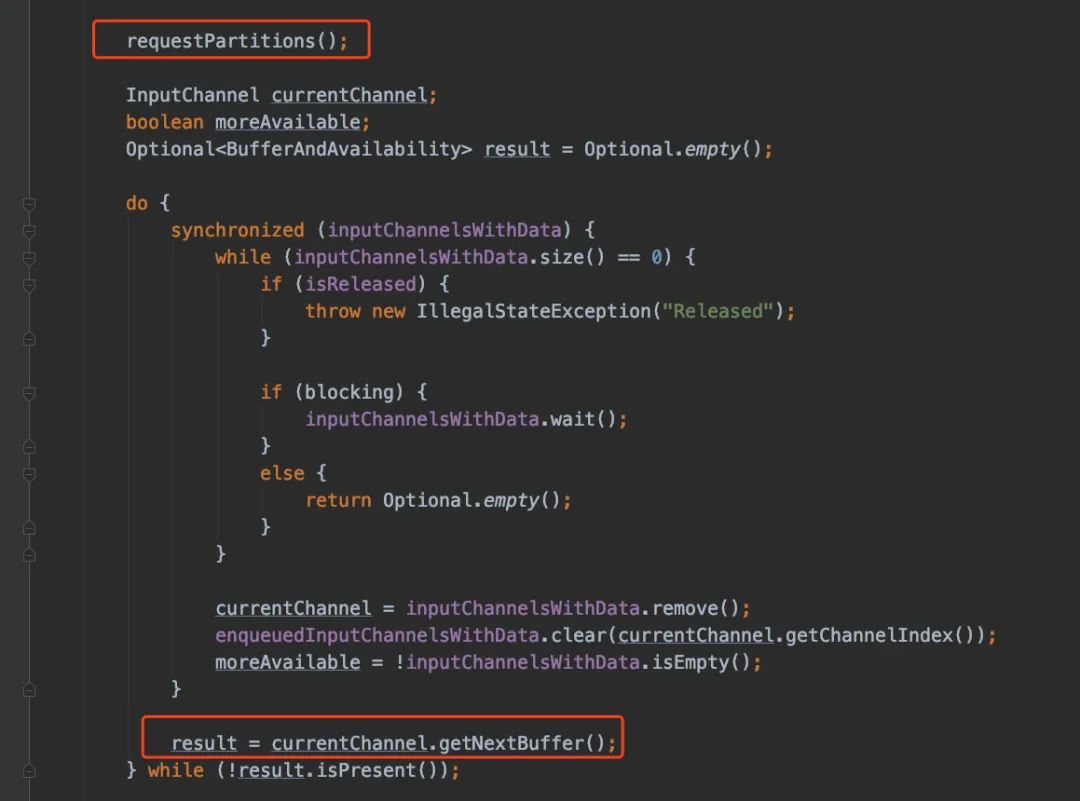
requestPartitions();
result = currentChannel.getNextBuffer();
先从requestPartitions()看起吧,发现里边套了一层(从InputChannel下获取到subPartition):
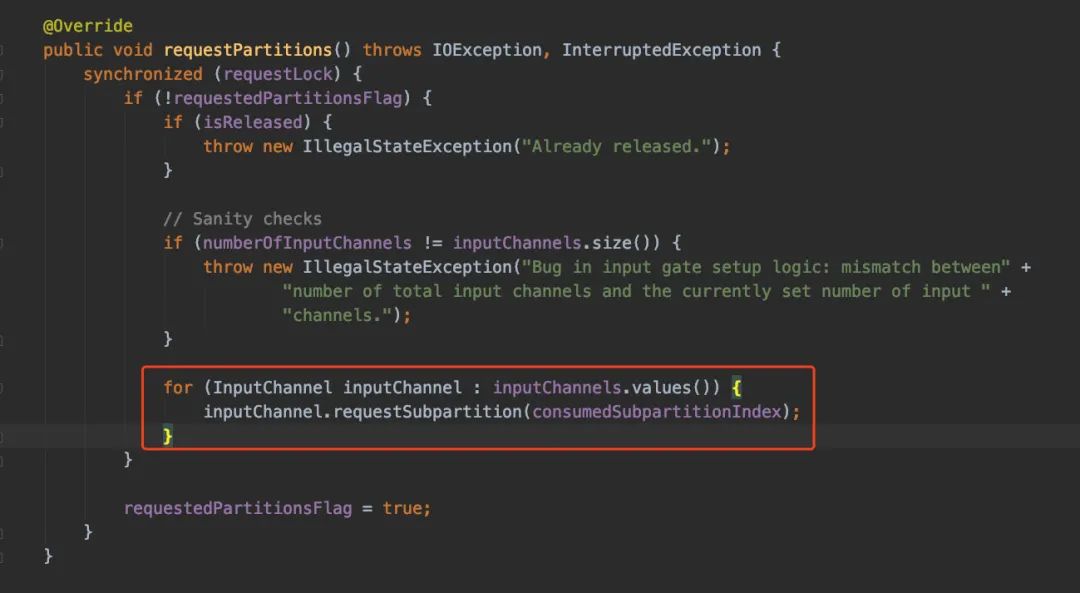
于是再进requestSubpartition()(看RemoteInputChannel的实现吧)
在这里看起来就是创建Client端,然后接收上游发送过来的数据:
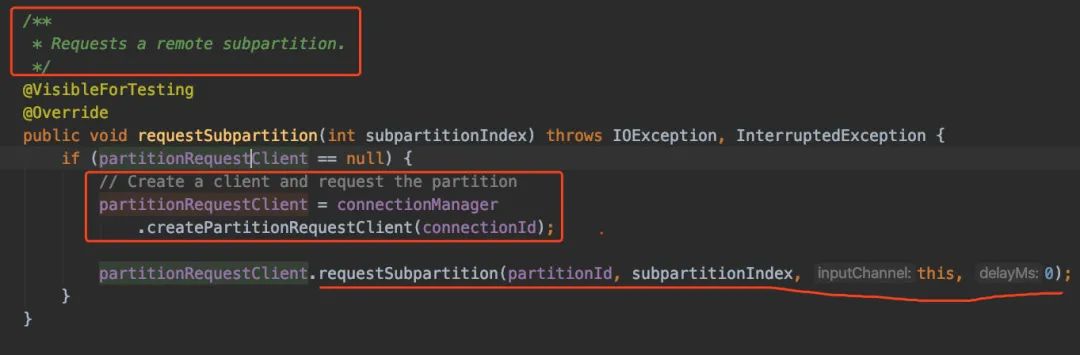
先看看client端的创建姿势吧,进createPartitionRequestClient()方法看看(我们看Netty的实现)。
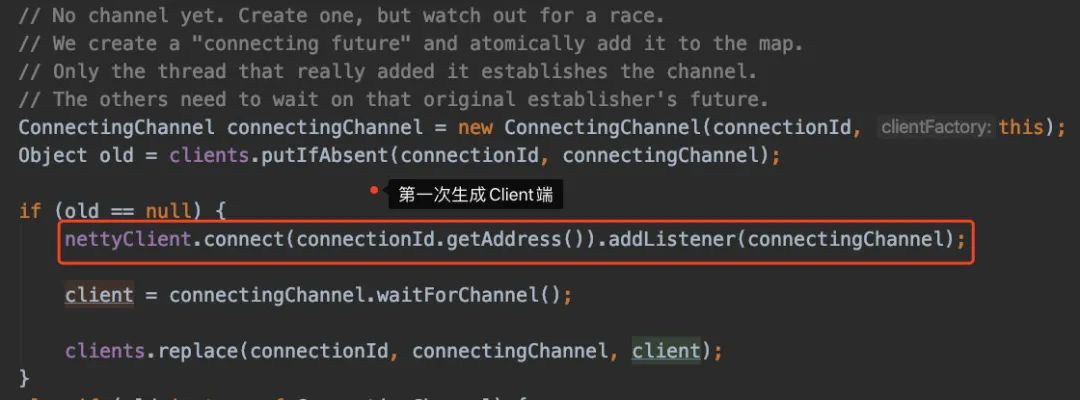
点了两层,我们会进到createPartitionRequestClient()方法,看源码注释就可以清晰发现,这会创建TCP连接并且创建出Client供我们使用

我们还是看null的情况,于是定位到这里:
进去connect()方法看看:
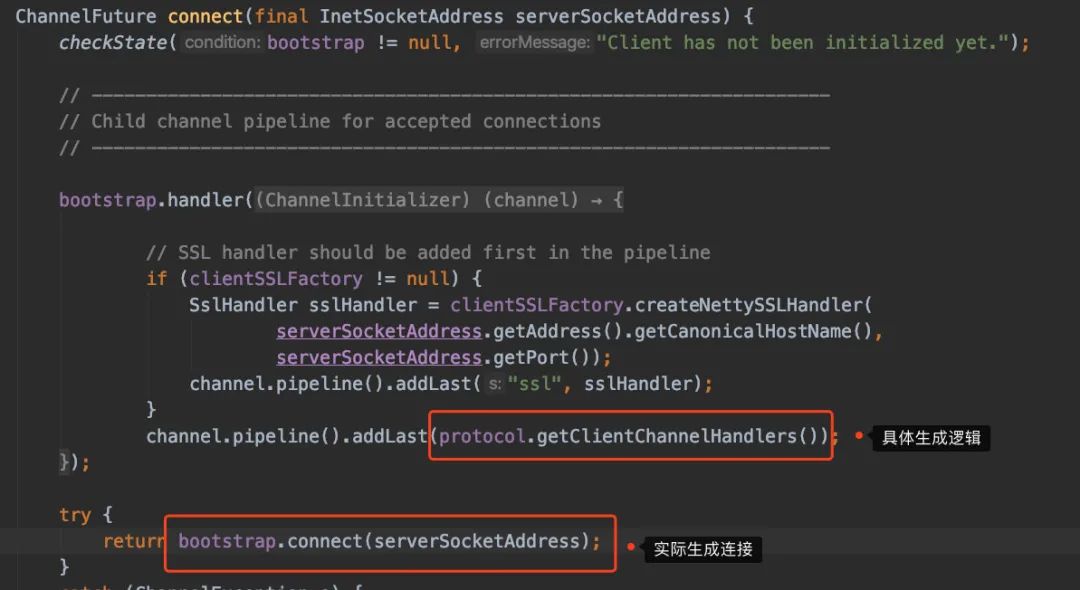
我们就看看具体生成逻辑的实现吧,所以进到getClientChannelHandlers上
意外发现源码还有个通信简要流程图给我们看(哈哈哈):
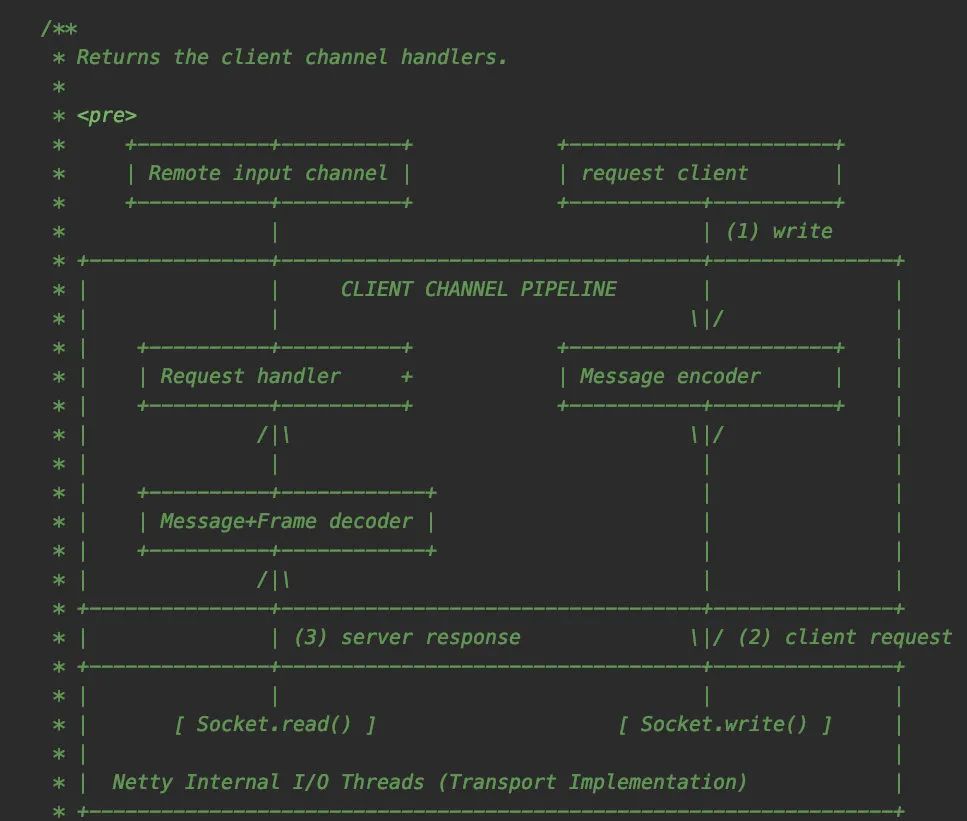
好了,来看看getClientChannelHandlers方法吧,这个方法不长,主要判断了下要生成的client是否开启creditBased机制:
public ChannelHandler[] getClientChannelHandlers() {
NetworkClientHandler networkClientHandler =
creditBasedEnabled ? new CreditBasedPartitionRequestClientHandler() :
new PartitionRequestClientHandler();
return new ChannelHandler[] {
messageEncoder,
new NettyMessage.NettyMessageDecoder(!creditBasedEnabled),
networkClientHandler};
}
于是我们的networkClientHandler实例是CreditBasedPartitionRequestClientHandler
到这里,我们暂且就认为Client端已经生成完了,再退回去getNextBufferOrEvent()这个方法,requestPartitions()方法是生成接收数据的Client端,具体的实例是CreditBasedPartitionRequestClientHandler
下面我们进getNextBuffer()看看接收数据具体是怎么处理的:
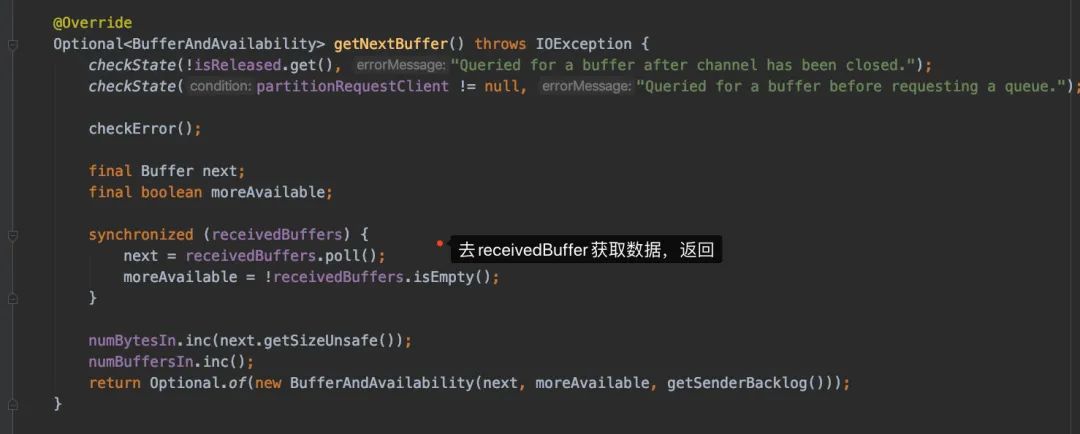
拿到数据后,就会开始执行我们用户的代码了调用process方法了(这里我们先不看了)。还是回到反压的逻辑上,我们好像还没看到反压的逻辑在哪里。重点就是receivedBuffers这里,是谁塞进去的呢?
于是我们回看到Client具体的实例CreditBasedPartitionRequestClientHandler,打开方法列表一看,感觉就是ChannelRead()没错了:
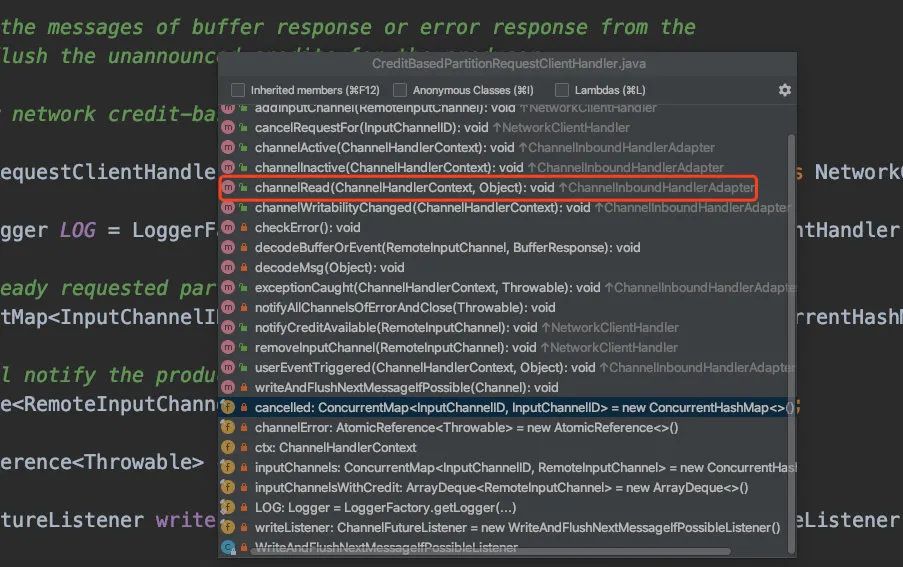
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
try {
decodeMsg(msg);
} catch (Throwable t) {
notifyAllChannelsOfErrorAndClose(t);
}
}
跟着decodeMsg继续往下走吧:
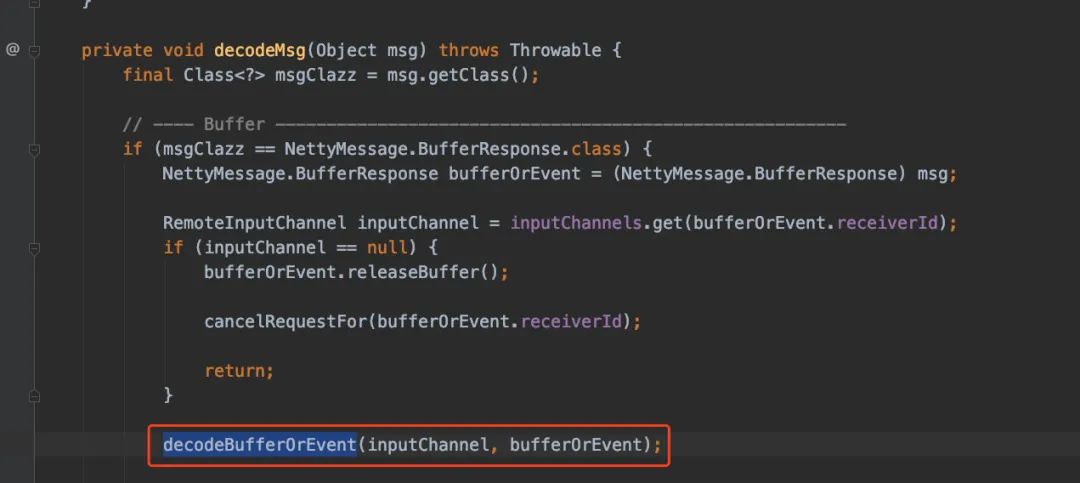
继续下到decodeBufferOrEvent()
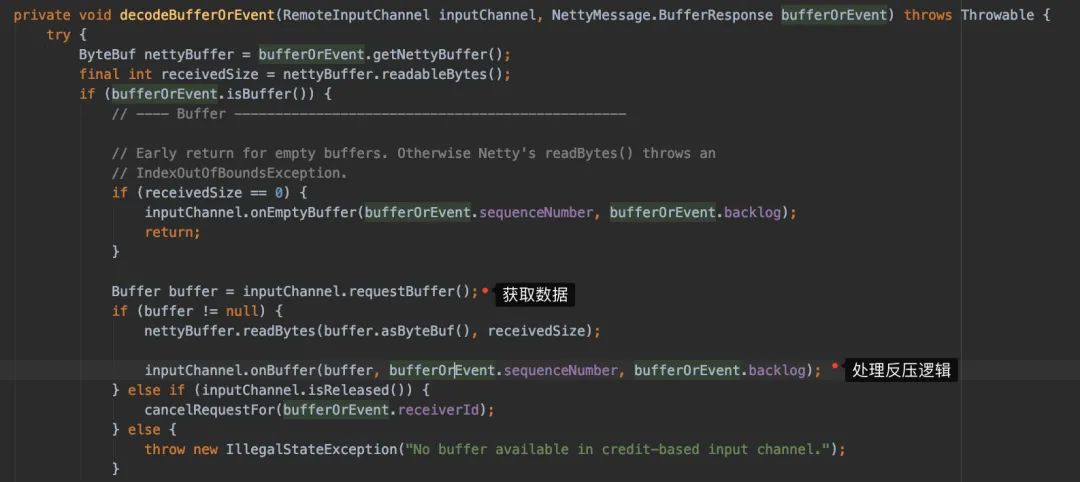
继续下到onBuffer:
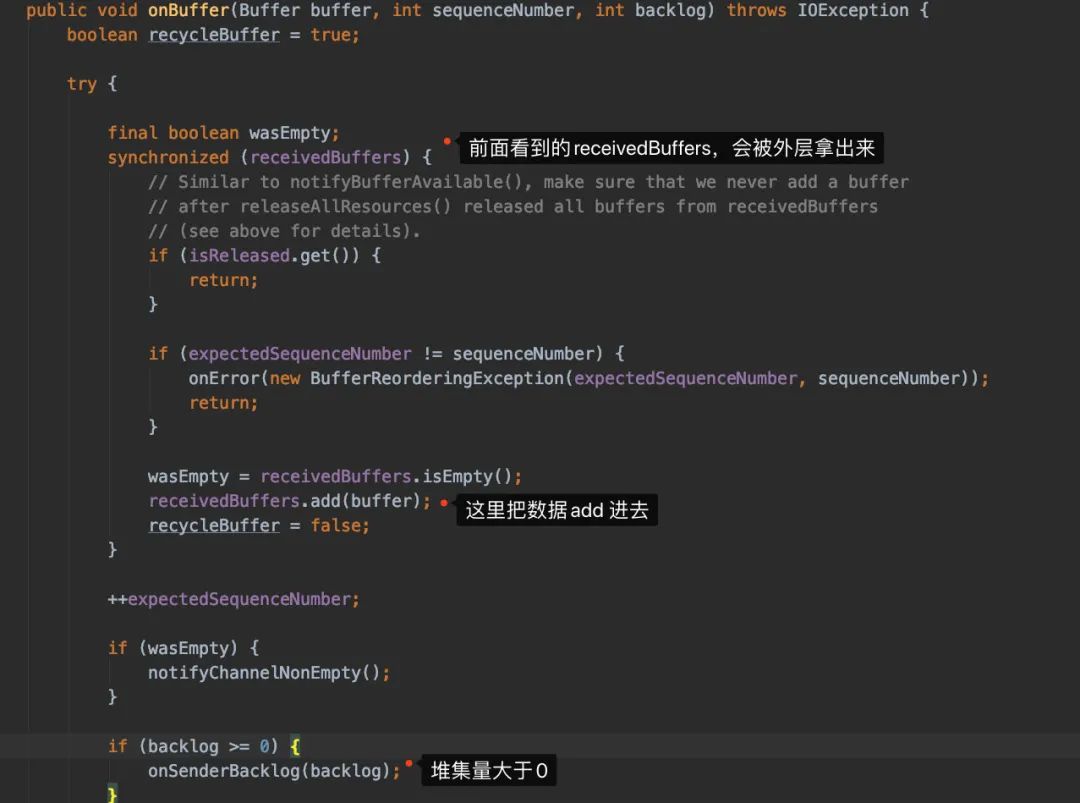
所以我们往onSenderBacklog上看看:

最后调用notifyCreditAvailable将Credit往上游发送:
public void notifyCreditAvailable(final RemoteInputChannel inputChannel) {
ctx.executor().execute(() -> ctx.pipeline().fireUserEventTriggered(inputChannel));
}
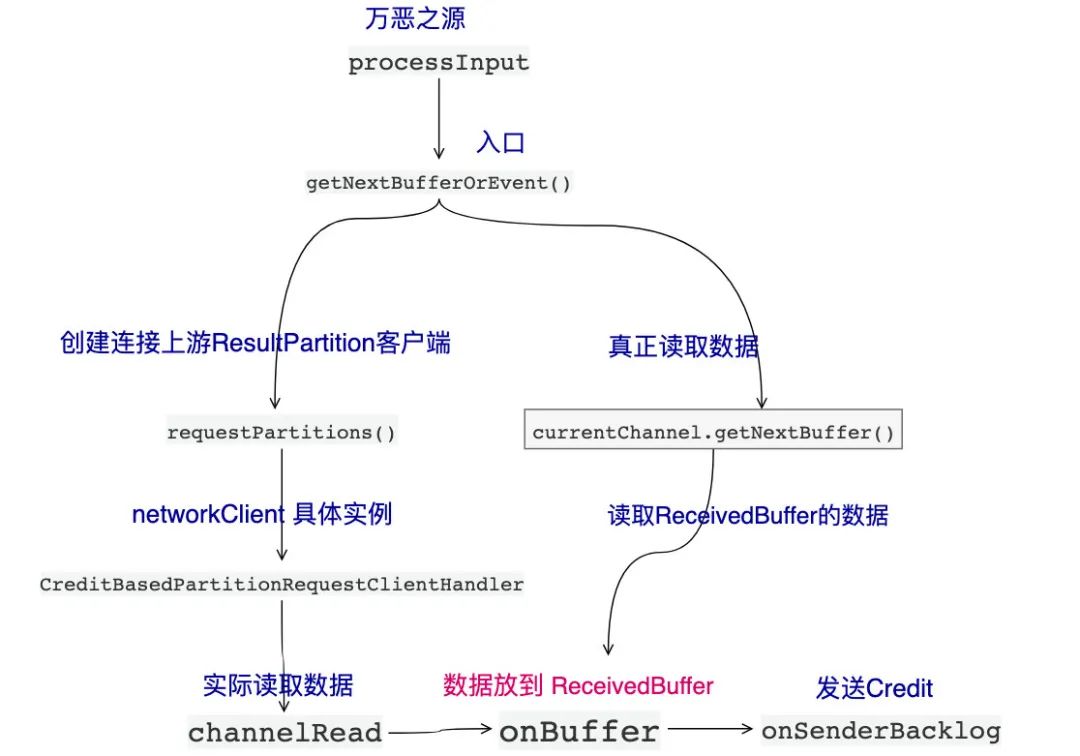
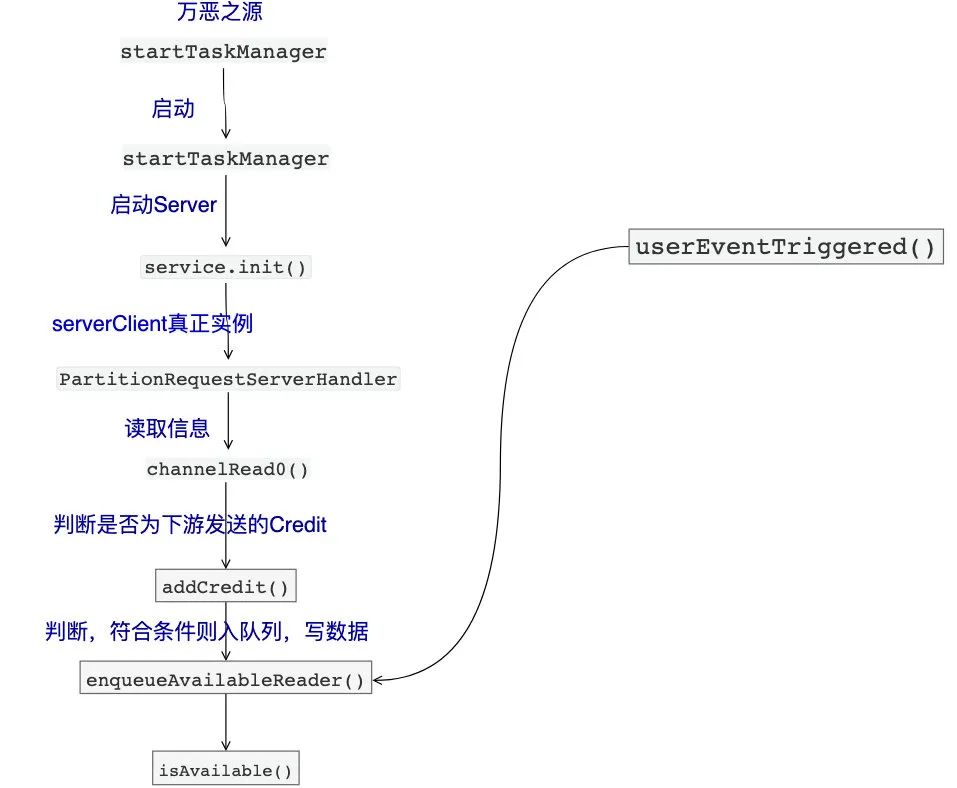
最后再画张图来理解一把(关键链路):
ResultPartition(发送端处理反压)
发送端我们从org.apache.flink.runtime.taskexecutor.TaskManagerRunner#startTaskManager开始看起
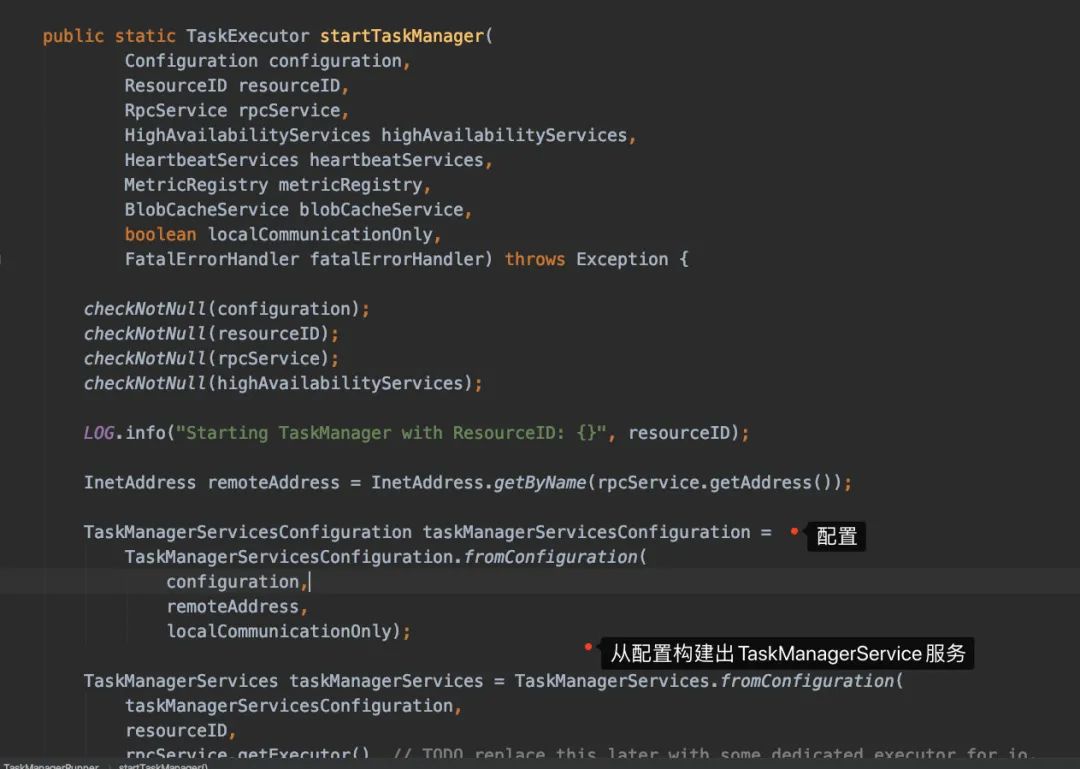
于是我们进去看fromConfiguration()
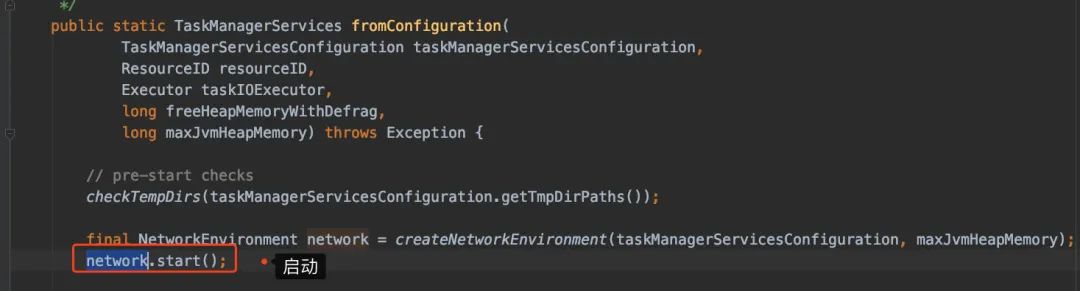
进去start()去看,随后进入connectionManager.start()(还是看Netty的实例):
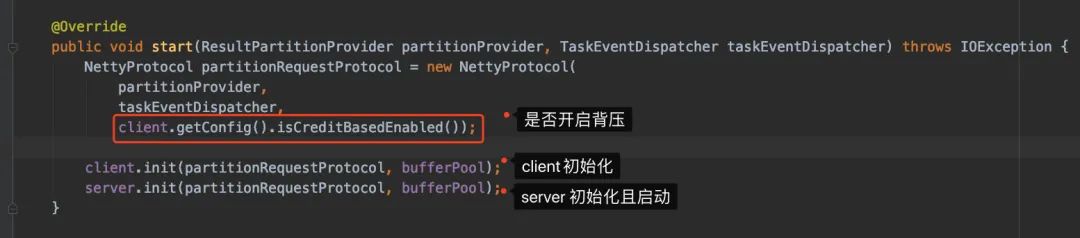
进去看service.init()方法做了什么(又看到熟悉的身影):
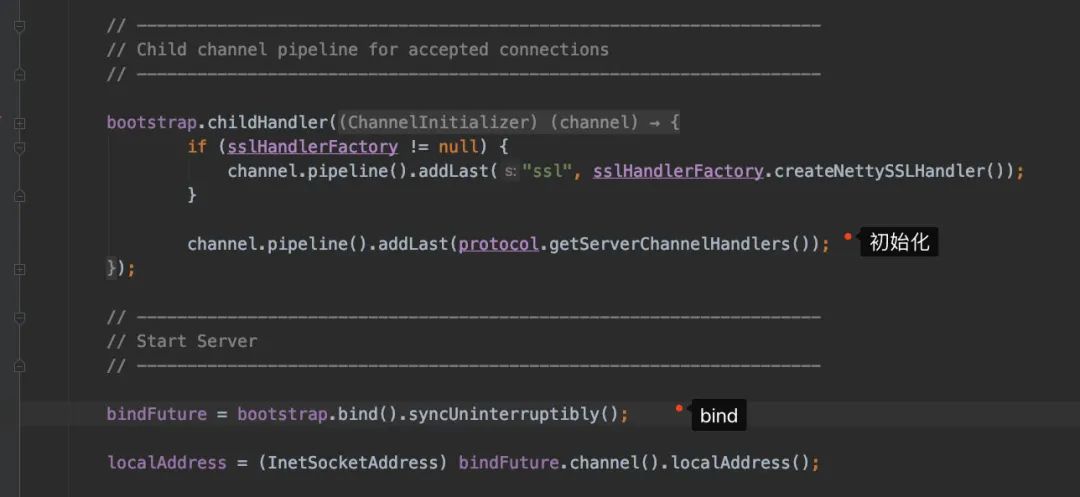
好了,我们再进去getServerChannelHandlers()看看吧:
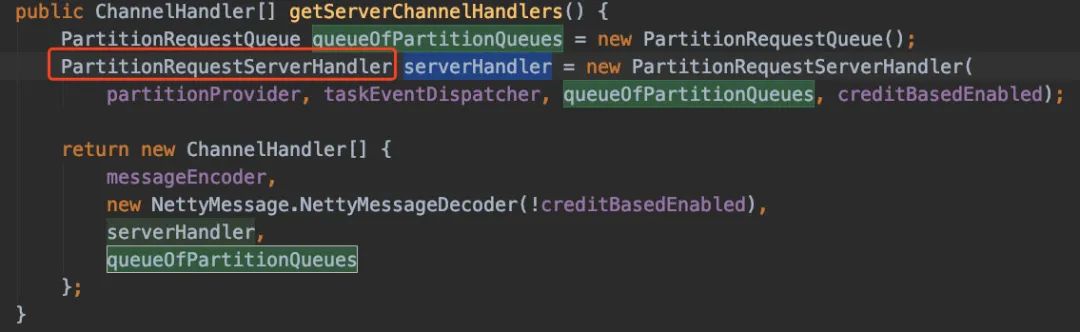
有了上面经验的我们,直接进去看看它的方法,没错,又是channnelRead,只是这次是channelRead0。
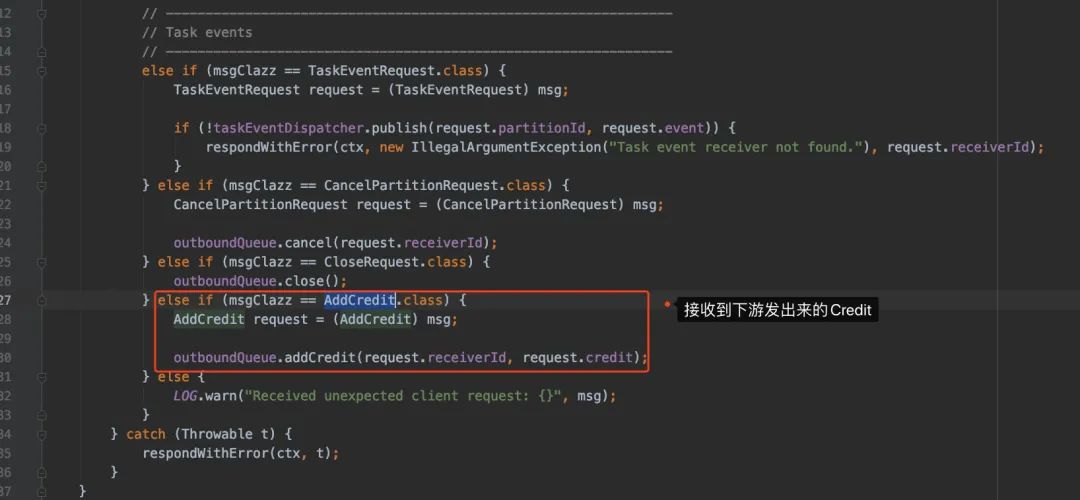
ok,我们进去addCredit()看看:
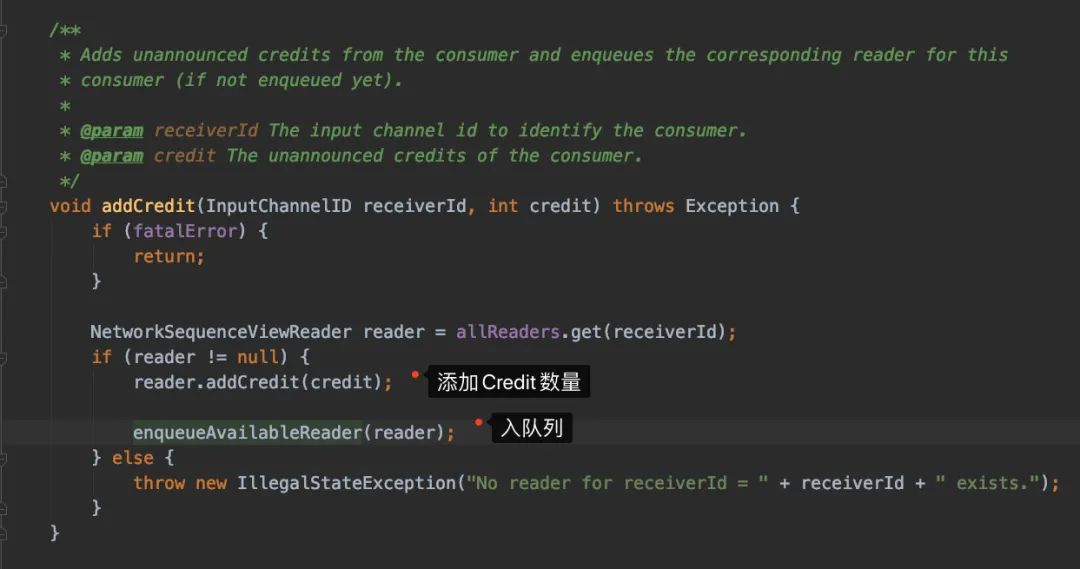
reader.addCredit(credit)只是更新了下数量
public void addCredit(int creditDeltas) {
numCreditsAvailable += creditDeltas;
}
重点我们看下enqueueAvailableReader() 方法,而enqueueAvailableReader()的重点就是判断Credit是否足够发送
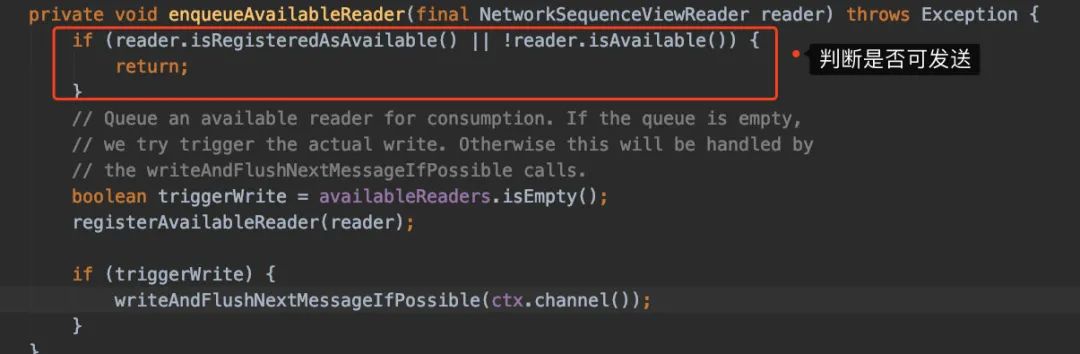
isAvailable的实现也很简单,就是判断Credit是否大于0且有真实数据可发
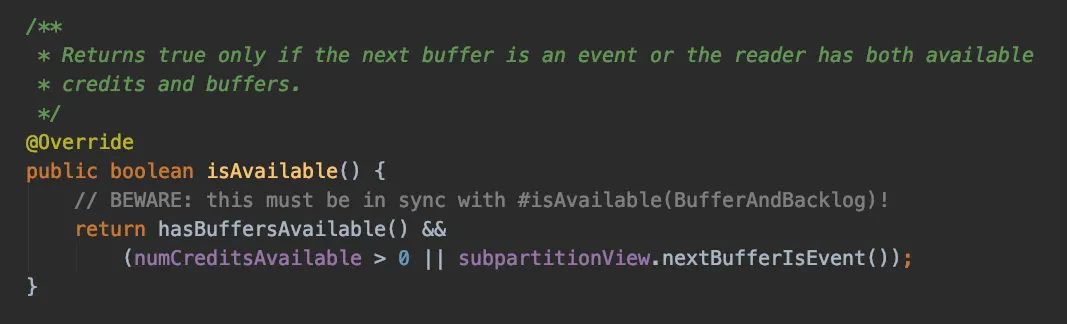
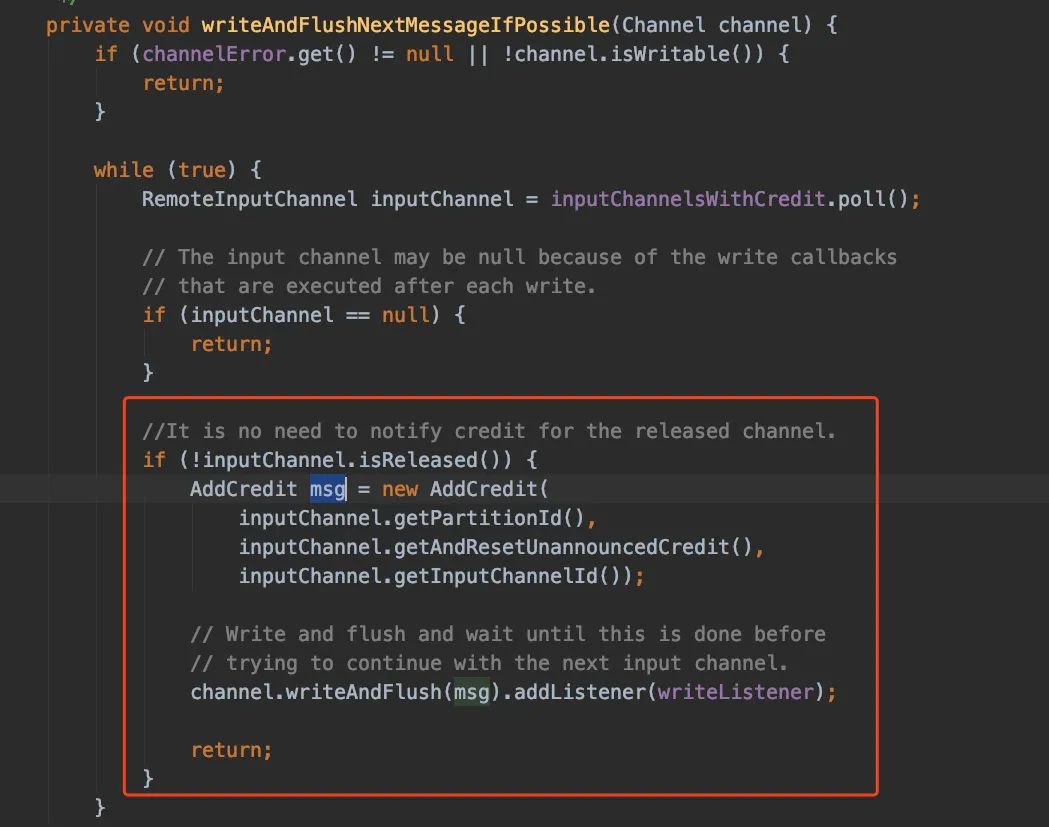
而writeAndFlushNextMessageIfPossible实际上就是往下游发送数据:

拿数据的时候会判断Credit是否足够,不足够抛异常:
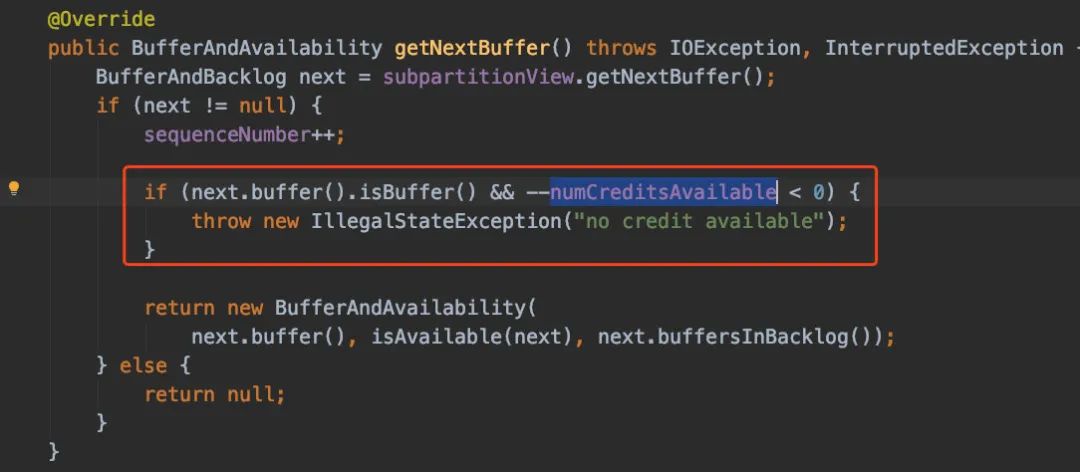
再画张图来简单理解一下:
背压总结
「下游」的处理速度跟不上「上游」的发送速度,从而降低了处理速度,看似是很美好的(毕竟看起来就是帮助我们限流了)。
但在Flink里,背压再加上Checkponit机制,很有可能导致State状态一直变大,拖慢完成checkpoint速度甚至超时失败。
当checkpoint处理速度延迟时,会加剧背压的情况(很可能大多数时间都在处理checkpoint了)。
当checkpoint做不上时,意味着重启Flink应用就会从上一次完成checkpoint重新执行(...
举个我真实遇到的例子:
我有一个
Flink任务,我只给了它一台TaskManager去执行任务,在更新DB的时候发现会有并发的问题。只有一台
TaskManager定位问题很简单,稍微定位了下判断:我更新DB的Sink 并行度调高了。如果Sink的并行度设置为1,那肯定没有并发的问题,但这样处理起来太慢了。
于是我就在Sink之前根据
userId进行keyBy(相同的userId都由同一个Thread处理,那这样就没并发的问题了)
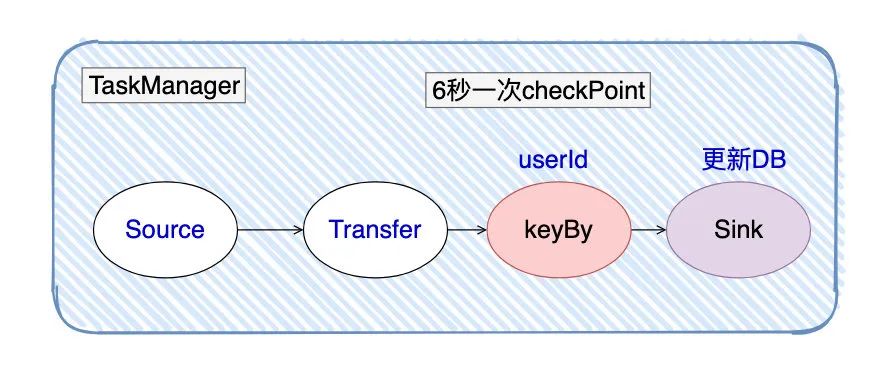
看似很美好,但userId存在热点数据的问题,导致下游数据处理形成反压。原本一次checkpoint执行只需要30~40ms,反压后一次checkpoint需要2min+。
checkpoint执行间隔相对频繁(6s/次),执行时间2min+,最终导致数据一直处理不过来,整条链路的消费速度从原来的3000qps到背压后的300qps,一直堵住(程序没问题,就是处理速度大大下降,影响到数据的最终产出)。
最后
本来想着这篇文章把反压和Checkpoint都一起写了,但写着写着发现有点长了,那checkpoint开下一篇吧。
相信我,只要你用到Flink,迟早会遇到这种问题的,现在可能有的同学还没看懂,没关系,先点个赞?,收藏起来,后面就用得上了。
参考资料:
https://www.cnblogs.com/ljygz/tag/flink/ https://ci.apache.org/projects/flink/flink-docs-release-1.11/

原创电子书原创思维导图
已经有8756个初学者都下载了!
?三歪把【大厂面试知识点】、【简历模板】、【原创文章】
全部整理成电子书,共有1263页!扫码或微信搜 Java3y
回复「888」领取

 |
|

