
是时候和pd.read_csv(), pd.to_csv()说再见了

大数据文摘授权转载自数据派THU
作者:Avi Chawla
翻译:欧阳锦
校对:和中华
Pandas 对 CSV 的输入输出操作是串行化的,这使得它们非常低效且耗时。我在这里看到足够的并行优化空间,但遗憾的是,Pandas 还没有提供这个功能。尽管我从不赞成一开始就使用 Pandas 创建 CSV(请阅读https://towardsdatascience.com/why-i-stopped-dumping-dataframes-to-a-csv-and-why-you-should-too-c0954c410f8f了解原因),但我知道在某些情况下,除了使用 CSV 之外别无选择。
因此,在这篇文章中,我们将探索Dask和DataTable,这两个最受数据科学家欢迎的类 Pandas 库。我们将根据 Pandas、Dask 和 Datatable 在以下参数上的表现对它们进行排名:
1. 读取 CSV 并获取 PANDAS DATAFRAME 所需的时间
如果我们通过 Dask 和 DataTable 读取 CSV,它们将分别生成 Dask DataFrame 和 DataTable DataFrame,而不是 Pandas DataFrame。假设我们想坚持传统的 Pandas 语法和函数(由于熟悉),我们必须首先将它们转换为 Pandas DataFrame,如下所示。
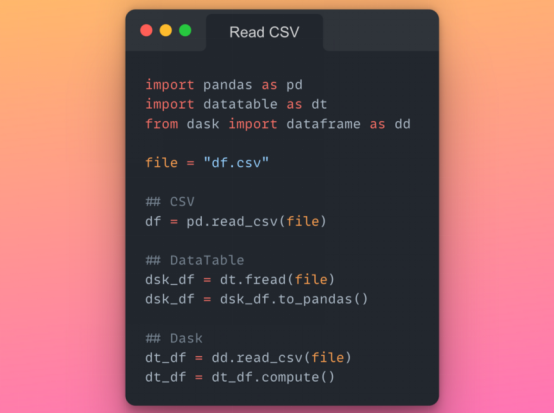
描述 Dask 和 DataTable DataFrame 转换到Pandas DataFrame 的代码片段
2. 将 PANDAS DATAFRAME 存储到 CSV 所需的时间
目标是从给定的 Pandas DataFrame 生成 CSV 文件。对于 Pandas,我们已经知道df.to_csv()方法。但是,要从 Dask 和 DataTable 创建 CSV,我们首先需要将给定的 Pandas DataFrame 转换为它们各自的 DataFrame,然后将它们存储在 CSV 中。因此,我们还将在此分析中考虑此 DataFrame 转换所花费的时间。
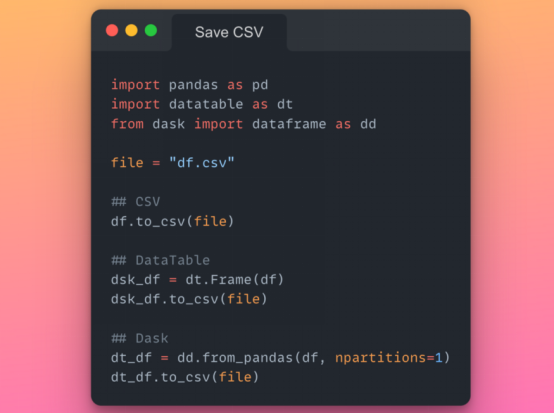
使用 Pandas、Dask 和 DataTable 将 DataFrame 保存到 CSV 的代码片段
实验装置:
1. 出于实验目的,我在 Python 中生成了一个随机数据集,其中包含可变行和三十列——包括字符串、浮点数和整数数据类型。
2. 我将下面描述的每个实验重复了五次,以减少随机性并从观察到的结果中得出较公平的结论。我在下一节中报告的数据是五个实验的平均值。
3. Python环境和库:
Python 3.9.12
Pandas 1.4.2
DataTable 1.0.0
Dask 2022.02.1
实验 1:读取 CSV 所需的时间
下图描述了 Pandas、Dask 和 DataTable 读取 CSV 文件并生成 Pandas DataFrame 所花费的时间(以秒为单位)。CSV 的行数从 100k 到 500 万不等。
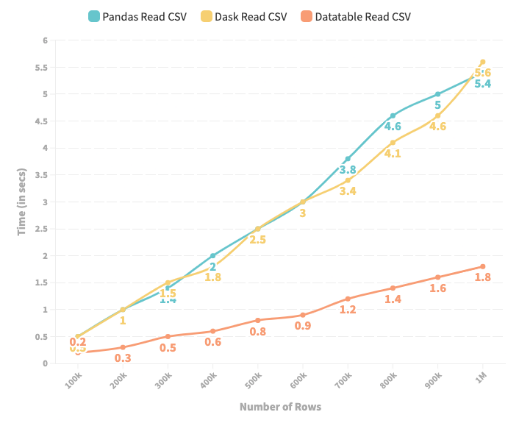
描绘 Pandas、DataTable 和 Dask 读取 CSV 所需时间的折线图
1. 实验结果表明,当行数少于一百万时,Dask 和 Pandas 从 CSV 生成 Pandas DataFrame 的时间大致相同。
2. 但是,当我们超过一百万行时,Dask 的性能会变差,生成 Pandas DataFrame 所花费的时间要比 Pandas 本身多得多。
3. 在这两种情况下,Datatable 生成Pandas 中的 DataFrame 所需的时间最少,提供高达 4 到 5 倍的加速——使其成为迄今为止最好的选择。
实验 2:保存到 CSV 所需的时间
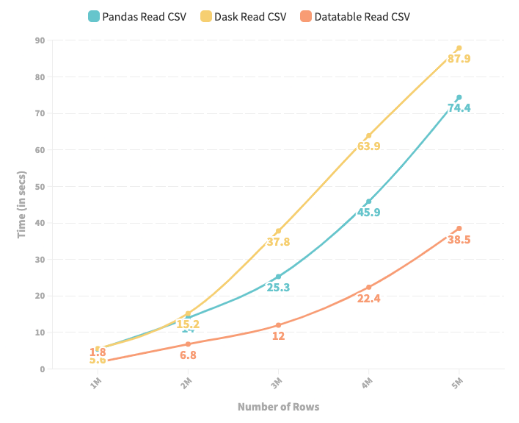
下图描述了 Pandas、Dask 和 DataTable 从给定的 Pandas DataFrame 生成 CSV 文件所花费的时间(以秒为单位)。行数范围从 100k 到 500 万。
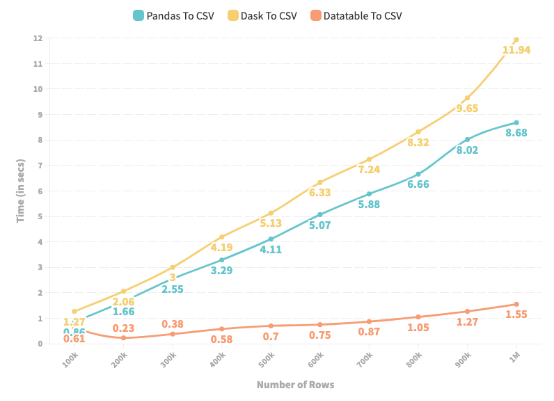
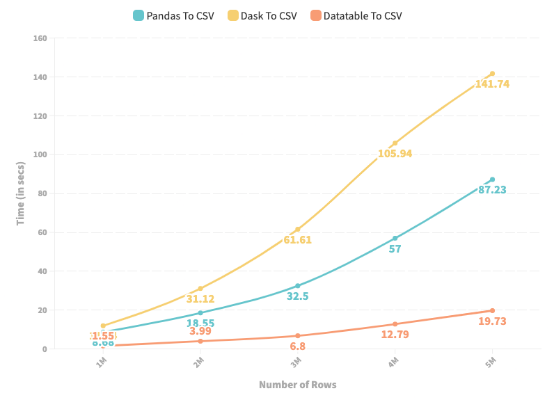
折线图描绘了 Pandas、DataTable 和 Dask 将 DataFrame 存储到 CSV 所需的时间
1. 在所有情况下,Dask 在将 Pandas DataFrame 存储到 CSV 方面的表现都比 Pandas 差。
2. 与实验 1 类似,DataTable 表现最好——相对于 Pandas 将保存过程提高了近8 倍。
结论
老实说,我算不上 CSV 的忠实粉丝。如果您阅读了我之前的帖子(我在上面链接过,或者您可以在https://medium.com/towards-data-science/why-i-stopped-dumping-dataframes-to-a-csv-and-why-you-should-too-c0954c410f8f阅读)以及您现在正在阅读的帖子,您可能也会认同我的观点。由于我发现了与 CSV 相关的众多问题,因此我已尽可能停止使用它们。
最后,我想说,除非您需要在 Excel 等非 Python 环境之外查看 DataFrame,否则您根本不需要 CSV。首选 Parquet、Feather 或 Pickle 等格式来存储 DataFrame。尽管如此,如果您没有其他选项,至少可以利用 DataTable 而不是 Pandas 来优化您的输入和输出操作。
原文标题:
It’s Time to Say GoodBye to pd.read_csv() and pd.to_csv()
原文链接:
https://towardsdatascience.com/its-time-to-say-goodbye-to-pd-read-csv-and-pd-to-csv-27fbc74e84c5
 点「在看」的人都变好看了哦!
点「在看」的人都变好看了哦!