
关于复杂度的碎碎念
之前陶师傅推荐过这么一篇文章,Complexity has to live somewhere[1],大致意思是系统的复杂度是没法凭空消失的,只能从一个地方转移到另一个地方,因为现实世界的逻辑就是那么多,边边角角的 case 就是那么多,你必须要处理,这必然会给系统引入复杂度。
尽管这些复杂度你可以转移给你的同事,或者外包给第三方系统,但复杂度是不灭的。
设计系统时,我们要注意到这一点,同时要管理好复杂度问题。
在《a philosophy of software design》这本书中,作者也提出了一个不一样的,比较有意思的系统复杂度理论,
可以和上面那篇文章结合在一起来看。
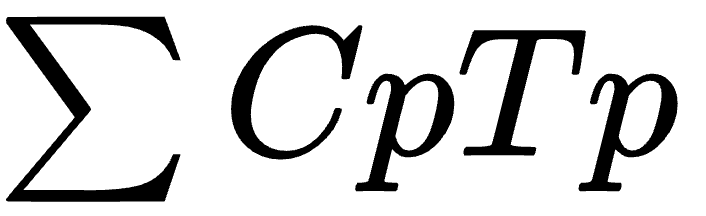
C 代表 Complexity,T 代表在该模块上开发投入的时间 Time。系统的整体复杂度= “每个模块的复杂度 Ⅹ 在该模块上投入的开发时间”,再对结果求和。
如果我们日常工作中主动或被动地去设计并实现过一些逻辑比较复杂的系统,这个简单的公式应该是一看就懂。这个公式里的 C 其实也可以认为是 Cognitive Load,即认知负担。你写的代码你同事很难看懂,那也要认为这些代码是很复杂的。
提高研发效率,本质上应该是降低这里定义的系统整体复杂度。
将公式与我们日常的开发和系统设计相结合,这篇文章简单列一些暴论,希望大家一起探讨。
系统可以设计得复杂,只要复杂的部分不常修改就可以了
举个例子,我们的 API 服务基本都部署在 linux 上,linux 当前有千万行级的代码,但我们并不需要阅读 linux 的源代码,也不需要关注 linux 的复杂度。只需要将精力聚焦在上层业务。即使是做系统编程,也只需要熟读 man7.org,并不需要把 syscall 底层的实现机制搞明白(现在很多人是自己太卷了)。
如果碰到了操作系统相关的性能问题,大多数情况下也不需要我们去内核里做优化,根据业务情况调整少量的系统暴露配置参数就可以了,比如 somaxconn,tcp_tw_reuse 等。
如果是设计一套业务系统,为了适配尽可能多的情况,不常修改的部分对复杂度也不必畏之如虎,只要你的抽象足够通用,并且能够在无法适配的时候给用户提供好扩展的后门,也不会有什么大问题。
与 linux kernel 场景类似,如果我们面对的是只需要解决一次的复杂问题,通过一个不频繁修改的复杂系统来解决它,也是合理的。
对于极复杂的系统,哪怕修改一次需要一个月,但我们两年只需修改一次,成本也是可以接受的。
经常修改的部分与不经常修改的部分可以进行拆分
无论是业务系统还是基础设施,随着时间的推移都会变得越来越复杂,具体可能体现在:冗长复杂的逻辑,场景化的代码分支,繁多的协议适配,奇怪的功能组合。
在“看起来很复杂”的系统上做开发并不见得就一定会很痛苦,因为我们常修改的并不总是系统的流程,可能只是经常变化的业务策略:触发拉新的推送频率,用户使用的业务指标,当前功能开启的城市,用户违规的判罚标准。
上面的这些策略也是业务复杂性的一部分,不过它们跟流程没有什么关系。设计糟糕的系统,面对巨大的 code base,不知道该去哪里修改,需要反复阅读整个流程代码才能确认在哪里进行修改更为合适。如果工作任务压迫严重,排期缩水,工程师也有神技,所有的需求都可以在入参处理后,结果返回之前的两个位置进行无限累加。经过经年累月的迭代,这样的系统基本是没法维护的。

我们可以将这些易变常变的内容从系统中拆分出来成为配置,总结为模式。通过配置来控制系统的行为。
即使做不到配置化,将不常修改的部分与常修改的部分隔离开,也可以大幅降低工程师维护整体系统时的心智负担,开发只需要关注自己系统的功能就好。系统与系统之间是解耦的。
重复的工作一定可以配置化
如果我们反复修改的是一些判断条件,那么把这些条件抽象为规则,放在配置管理系统中就好。
如果我们反复修改的是外部数据源,那么把数据本身进行抽象,并使用 xpath,jpath 之类的工具来进行查询就好。再复杂的数据获取可以直接使用 apijson,GraphQL 或 falcor 之类的开源项目,自己设计一套方案也不难。
如果我们反复修改的是计算逻辑,那么我们在系统内支持表达式引擎就可以。
如果我们反复修改的是业务流程,那么将流程本身使用 bpm 类框架实现即可。
如果我们反复修改的是各种协议的支持,那么设计一套按照 IDL 来生成协议处理代码的工具即可。
配置化是将重复的工作内容模板化,在上面的公式中,是通过直接减少 T 来降低了系统整体的复杂度。
工程师不应该抗拒复杂度
现在的 CRUD 工程师都不太喜欢复杂的东西,很多时候会以“这个需求会让系统变复杂”为由,拒绝接受新的需求或对系统进行大幅修改。
但简单的项目无非逻辑堆砌,应届生就可以做得很好,很多人又为了涨工资跳槽跳得飞快,对于经历过的公司业务理解有限。将所有公司的业务都总结为 CRUD,实在有点简单暴力。
前几年中台大热,几乎所有公司都在推中台,尽管本人对中台有一些批评意见,但并没有否定中台提升工程师能力的效用。由于业务中台项目往往有一定复杂度,对于参与的工程师来说是很好的视野开阔和能力锻炼机会。
若因为太复杂,没收益(年终奖)的理由,放弃了这些机会,这也会导致你丧失一次提升自己认知的机会。
当初在某司设计某平台,按照部门内的惯例,这样的平台并不会得到太多部门的支持与收益,但可以消灭组内大量的重复无聊的开发工作。我们从过往的开发经验中总结了 90% 的需求和日常工作,结合了公司本身阶段考量和业界先进系统的调研才设计出了这套系统。
落地之后,我们这些参与者,也通过这个过程看到了这种数据相关的系统向更大范围延伸,能够发展出什么样的未来:
可以是一个数据中台,搭上国内中台的热潮,成为一线互联网公司的数据中台实践案例
也可以是类似 Google F1 那样的超级查询系统,成为先进工程理念落地的典范
也可以进化为专门服务机器学习业务的特征、模型生命周期管理平台
这些是之后的可能性,向哪一个方向继续进化并不是一线的开发者与架构师所能决定的,去除政治因素,整个系统的研发与迭代还是给我们提供了非常宝贵的经验,至今依然受用。
设计系统和算命其实差不多
尽管我们可以从过往的开发中汲取经验,但在做系统设计时还是要对未来做一些预测。
这些预测并不一定准确,技术上的判断和业务未来的发展并不一定能匹配。
电商公司的牛逼架构师们,也没想到国内两家电商近乎垄断的情况下,还能异军突起一家新电商,但你说它是电商又不合适,它其实更类似一家游戏厂商。
他们在很长一段时间内被打得措手不及。原来的系统和机制设计根本没法实现类似对手的游戏化电商,在宣传标语里神通广大的中台这时候也成为了业务发展的瓶颈。
我们几个朋友曾经对架构师有个神奇的调侃,架构师本身就是数据驱动的算命师傅,对未来所做的预测,预测对了是神,预测错了是🐶。
不过也只是个调侃,大家都是人,没有谁能突破人类认知的上限。
有时间单独写写 《a philosophy of software design》这本书的读书笔记。
Complexity has to live somewhere: https://ferd.ca/complexity-has-to-live-somewhere.html