
13000字!最常问的MySQL面试题集合
除了基础题部分,本文还收集整理的MySQL面试题还包括如下知识点或题型:
MySQL高性能索引
SQL语句
MySQL查询优化
MySQL高扩展高可用
MySQL安全性
问题1:char、varchar的区别是什么?
varchar是变长而char的长度是固定的。如果你的内容是固定大小的,你会得到更好的性能。
问题2: TRUNCATE和DELETE的区别是什么?
DELETE命令从一个表中删除某一行,或多行,TRUNCATE命令永久地从表中删除每一行。
问题3:什么是触发器,MySQL中都有哪些触发器?
触发器是指一段代码,当触发某个事件时,自动执行这些代码。在MySQL数据库中有如下六种触发器:
1、Before Insert
2、After Insert
3、Before Update
4、After Update
5、Before Delete
6、After Delete
问题4:FLOAT和DOUBLE的区别是什么?
FLOAT类型数据可以存储至多8位十进制数,并在内存中占4字节。
DOUBLE类型数据可以存储至多18位十进制数,并在内存中占8字节。
问题5:如何在MySQL种获取当前日期?
SELECT CURRENT_DATE();
问题6:如何查询第n高的工资?
SELECT DISTINCT(salary) from employee ORDER BY salary DESC LIMIT n-1,1
(提示:代码可以左右滑动)
问题7:请写出下面MySQL数据类型表达的意义(int(0)、char(16)、varchar(16)、datetime、text)
知识点分析
此题考察的是MySQL数据类型。MySQL数据类型属于MySQL数据库基础,由此延伸出的知识点还包括如下内容:
MySQL基础操作
MySQL存储引擎
MySQL锁机制
MySQL事务处理、存储过程、触发器
数据类型考点:
1、整数类型,包括TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,分别表示1字节、2字节、3字节、4字节、8字节整数。任何整数类型都可以加上UNSIGNED属性,表示数据是无符号的,即非负整数。长度:整数类型可以被指定长度,例如:INT(11)表示长度为11的INT类型。长度在大多数场景是没有意义的,它不会限制值的合法范围,只会影响显示字符的个数,而且需要和UNSIGNED ZEROFILL属性配合使用才有意义。例子,假定类型设定为INT(5),属性为UNSIGNED ZEROFILL,如果用户插入的数据为12的话,那么数据库实际存储数据为00012。2、实数类型,包括FLOAT、DOUBLE、DECIMAL。
DECIMAL可以用于存储比BIGINT还大的整型,能存储精确的小数。
而FLOAT和DOUBLE是有取值范围的,并支持使用标准的浮点进行近似计算。
计算时FLOAT和DOUBLE相比DECIMAL效率更高一些,DECIMAL你可以理解成是用字符串进行处理。3、字符串类型,包括VARCHAR、CHAR、TEXT、BLOB
VARCHAR用于存储可变长字符串,它比定长类型更节省空间。
VARCHAR使用额外1或2个字节存储字符串长度。列长度小于255字节时,使用1字节表示,否则使用2字节表示。
VARCHAR存储的内容超出设置的长度时,内容会被截断。
CHAR是定长的,根据定义的字符串长度分配足够的空间。
CHAR会根据需要使用空格进行填充方便比较。
CHAR适合存储很短的字符串,或者所有值都接近同一个长度。
CHAR存储的内容超出设置的长度时,内容同样会被截断。
使用策略:
对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
使用时要注意只分配需要的空间,更长的列排序时会消耗更多内存。
尽量避免使用TEXT/BLOB类型,查询时会使用临时表,导致严重的性能开销。
4、枚举类型(ENUM),把不重复的数据存储为一个预定义的集合。
有时可以使用ENUM代替常用的字符串类型。
ENUM存储非常紧凑,会把列表值压缩到一个或两个字节。
ENUM在内部存储时,其实存的是整数。
尽量避免使用数字作为ENUM枚举的常量,因为容易混乱。
排序是按照内部存储的整数5、日期和时间类型,尽量使用timestamp,空间效率高于datetime,
用整数保存时间戳通常不方便处理。
如果需要存储微妙,可以使用bigint存储。
看到这里,这道真题是不是就比较容易回答了。
答:int(0)表示数据是INT类型,长度是0、char(16)表示固定长度字符串,长度为16、varchar(16)表示可变长度字符串,长度为16、datetime表示时间类型、text表示字符串类型,能存储大字符串,最多存储65535字节数据)
MySQL基础操作:
常见操作
MySQL的连接和关闭:mysql -u -p -h -P
-u:指定用户名
-p:指定密码
-h:主机
-P:端口
进入MySQL命令行后:G、c、q、s、h、d
G:打印结果垂直显示
c:取消当前MySQL命令
q:退出MySQL连接
s:显示服务器状态
h:帮助信息
d:改变执行符
MySQL存储引擎:
1、InnoDB存储引擎,
默认事务型引擎,最重要最广泛的存储引擎,性能非常优秀。
数据存储在共享表空间,可以通过配置分开。也就是多个表和索引都存储在一个表空间中,可以通过配置文件改变此配置。
对主键查询的性能高于其他类型的存储引擎。
内部做了很多优化,从磁盘读取数据时会自动构建hash索引,插入数据时自动构建插入缓冲区。
通过一些机制和工具支持真正的热备份。
支持崩溃后的安全恢复。
支持行级锁。
支持外键。
2、MyISAM存储引擎,
拥有全文索引、压缩、空间函数。
不支持事务和行级锁、不支持崩溃后的安全恢复。
表存储在两个文件,MYD和MYI。
设计简单,某些场景下性能很好,例如获取整个表有多少条数据,性能很高。
全文索引不是很常用,不如使用外部的ElasticSearch或Lucene。
3、其他表引擎,
Archive、Blackhole、CSV、Memory
使用策略
在大多数场景下建议使用InnoDB存储引擎。
MySQL锁机制
表锁是日常开发中的常见问题,因此也是面试当中最常见的考察点,当多个查询同一时刻进行数据修改时,就会产生并发控制的问题。共享锁和排他锁,就是读锁和写锁。
共享锁,不堵塞,多个用户可以同时读一个资源,互不干扰。
排他锁,一个写锁会阻塞其他的读锁和写锁,这样可以只允许一个用户进行写入,防止其他用户读取正在写入的资源。
锁的粒度
表锁,系统开销最小,会锁定整张表,MyIsam使用表锁。
行锁,最大程度的支持并发处理,但是也带来了最大的锁开销,InnoDB使用行锁。
MySQL事务处理
MySQL提供事务处理的表引擎,也就是InnoDB。
服务器层不管理事务,由下层的引擎实现,所以同一个事务中,使用多种引擎是不靠谱的。
需要注意,在非事务表上执行事务操作,MySQL不会发出提醒,也不会报错。
存储过程
为以后的使用保存的一条或多条MySQL语句的集合,因此也可以在存储过程中加入业务逻辑和流程。
可以在存储过程中创建表,更新数据,删除数据等等。
使用策略
可以通过把SQL语句封装在容易使用的单元中,简化复杂的操作
可以保证数据的一致性
可以简化对变动的管理
触发器
提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程。
使用场景
可以通过数据库中的相关表实现级联更改。
实时监控某张表中的某个字段的更改而需要做出相应的处理。
例如可以生成某些业务的编号。
注意不要滥用,否则会造成数据库及应用程序的维护困难。
大家需要牢记以上基础知识点,重点是理解数据类型CHAR和VARCHAR的差异,表存储引擎InnoDB和MyISAM的区别。
问题8:请说明InnoDB和MyISAM的区别
InnoDB支持事务,MyISAM不支持;
InnoDB数据存储在共享表空间,MyISAM数据存储在文件中;
InnoDB支持行级锁,MyISAM只支持表锁;
InnoDB支持崩溃后的恢复,MyISAM不支持;
InnoDB支持外键,MyISAM不支持;
InnoDB不支持全文索引,MyISAM支持全文索引;
问题9:innodb引擎的特性
插入缓冲(insert buffer)
二次写(double write)
自适应哈希索引(ahi)
预读(read ahead)
问题10:请列举3个以上表引擎
InnoDB、MyISAM、Memory
问题11:请说明varchar和text的区别
varchar可指定字符数,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
text类型不能有默认值。
varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下,text的索引几乎不起作用。
查询text需要创建临时表。
问题12:varchar(50)中50的含义
最多存放50个字符,varchar(50)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样)。
问题13:int(20)中20的含义
是指显示字符的长度,不影响内部存储,只是当定义了ZEROFILL时,前面补多少个 0
问题14:简单描述MySQL中,索引,主键,唯一索引,联合索引的区别,对数据库的性能有什么影响?
知识点分析
此真题主要考察的是MySQL索引的基础和类型,由此延伸出的知识点还包括如下内容:
MySQL索引的创建原则
MySQL索引的注意事项
MySQL索引的原理
下面我们就来将这些知识一网打尽
索引的基础
索引类似于书籍的目录,要想找到一本数的某个特定主题,需要先查找书的目录,定位对应的页码
存储引擎使用类似的方式进行数据查询,先去索引当中找到对应的值,然后根据匹配的索引找到对应的数据行。
创建索引的语法:
首先创建一个表:create table t1 (id int primary key,username varchar(20),password varchar(20));
创建单个索引的语法:CREATE INDEX 索引名 on 表名(字段名)
索引名一般是:表名_字段名
给id创建索引:CREATE INDEX t1_id on t1(id);
创建联合索引的语法:CREATE INDEX 索引名 on 表名(字段名1,字段名2)
给username和password创建联合索引:CREATE index t1_username_password ON t1(username,password)
其中index还可以替换成unique,primary key,分别代表唯一索引和主键索引
删除索引:DROP INDEX t1_username_password ON t1
索引对性能的影响:
大大减少服务器需要扫描的数据量。
帮助服务器避免排序和临时表。
将随机I/O变顺序I/O。
大大提高查询速度。
降低写的速度(不良影响)。
磁盘占用(不良影响)。
索引的使用场景:
对于非常小的表,大部分情况下全表扫描效率更高。
中到大型表,索引非常有效。
特大型的表,建立和使用索引的代价会随之增大,可以使用分区技术来解决。
索引的类型:
索引很多种类型,是在MySQL的存储引擎实现的。
普通索引:最基本的索引,没有任何约束限制。
唯一索引:和普通索引类似,但是具有唯一性约束。
主键索引:特殊的唯一索引,不允许有空值。
索引的区别:
-一个表只能有一个主键索引,但是可以有多个唯一索引。
主键索引一定是唯一索引,唯一索引不是主键索引。
主键可以与外键构成参照完整性约束,防止数据不一致。
联合索引:将多个列组合在一起创建索引,可以覆盖多个列。(也叫复合索引,组合索引)
外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性、和实现级联操作(基本不用)。
全文索引:MySQL自带的全文索引只能用于MyISAM,并且只能对英文进行全文检索 (基本不用)
MySQL索引的创建原则
最适合创建索引的列是出现在WHERE或ON子句中的列,或连接子句中的列而不是出现在SELECT关键字后的列。
索引列的基数越大,数据区分度越高,索引的效果越好。
对于字符串进行索引,应该制定一个前缀长度,可以节省大量的索引空间。
根据情况创建联合索引,联合索引可以提高查询效率。
避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率。
主键尽可能选择较短的数据类型,可以有效减少索引的磁盘占用提高查询效率。
MySQL索引的注意事项
1、联合索引遵循前缀原则
KEY(a,b,c)
WHERE a = 1 AND b = 2 AND c = 3
WHERE a = 1 AND b = 2
WHERE a = 1
#以上SQL语句可以用到索引
WHERE b = 2 AND c = 3
WHERE a = 1 AND c = 3
#以上SQL语句用不到索引
2、LIKE查询,%不能在前
WHERE name LIKE "%wang%"
#以上语句用不到索引,可以用外部的ElasticSearch、Lucene等全文搜索引擎替代。
3、列值为空(NULL)时是可以使用索引的,但MySQL难以优化引用了可空列的查询,它会使索引、索引统计和值更加复杂。可空列需要更多的储存空间,还需要在MySQL内部进行特殊处理。
4、如果MySQL估计使用索引比全表扫描更慢,会放弃使用索引,例如:
表中只有100条数据左右。对于SQL语句WHERE id > 1 AND id < 100,MySQL会优先考虑全表扫描。
5、如果关键词or前面的条件中的列有索引,后面的没有,所有列的索引都不会被用到。
6、列类型是字符串,查询时一定要给值加引号,否则索引失效,例如:
列name varchar(16),存储了字符串"100"
WHERE name = 100;
以上SQL语句能搜到,但无法用到索引。
MySQL索引的原理
MySQL索引是用一种叫做聚簇索引的数据结构实现的,下面我们就来看一下什么是聚簇索引。
聚簇索引是一种数据存储方式,它实际上是在同一个结构中保存了B+树索引和数据行,InnoDB表是按照聚簇索引组织的(类似于Oracle的索引组织表)。
注:
B+ 树是一种树数据结构,是一个n叉排序树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
B+ 树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
InnoDB通过主键聚簇数据,如果没有定义主键,会选择一个唯一的非空索引代替,如果没有这样的索引,会隐式定义个主键作为聚簇索引。
下图形象说明了聚簇索引表(InnoDB)和普通的堆组织表(MyISAM)的区别:
最常问的MySQL面试题三——每个开发人员都应该知道
对于普通的堆组织表来说(右图),表数据和索引是分别存储的,主键索引和二级索引存储上没有任何区别。
而对于聚簇索引表来说(左图),表数据是和主键一起存储的,主键索引的叶结点存储行数据,二级索引的叶结点存储行的主键值。
聚簇索引表最大限度地提高了I/O密集型应用的性能,但它也有以下几个限制:
1)插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
2)更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
3)二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
二级索引的叶节点存储的是主键值,而不是行指针,这是为了减少当出现行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多的空间。
解题方法
在一些MySQL索引基础考题中,我们可以轻松的通过索引基础和类型来解决此类问题,对于一些索引创建注意事项方面的考点,我们可以通过索引创建原则和注意事项来解决。
问题14:创建MySQL联合索引应该注意什么?
需遵循前缀原则
问题15:列值为NULL时,查询是否会用到索引?
在MySQL里NULL值的列也是走索引的。当然,如果计划对列进行索引,就要尽量避免把它设置为可空,MySQL难以优化引用了可空列的查询,它会使索引、索引统计和值更加复杂。
问题16:以下语句是否会应用索引:SELECT FROM users WHERE YEAR(adddate) < 2007;*
不会,因为只要列涉及到运算,MySQL就不会使用索引。
问题17:MyISAM索引实现?
MyISAM存储引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。MyISAM的索引方式也叫做非聚簇索引的,之所以这么称呼是为了与InnoDB的聚簇索引区分。
问题18:MyISAM索引与InnoDB索引的区别?
InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
问题19:以下三条sql 如何建索引,只建一条怎么建?
WHERE a=1 AND b=1
WHERE b=1
WHERE b=1 ORDER BY time DESC
以顺序b,a,time建立联合索引,CREATE INDEX table1_b_a_time ON index_test01(b,a,time)。因为最新MySQL版本会优化WHERE子句后面的列顺序,以匹配联合索引顺序。
问题20:有A(id,sex,par,c1,c2),B(id,age,c1,c2)两张表,其中A.id与B.id关联,现在要求写出一条SQL语句,将B中age>50的记录的c1,c2更新到A表中同一记录中的c1,c2字段中
考点分析
这道题主要考察的是MySQL的关联UPDATE语句
延伸考点:
MySQL的关联查询语句
MySQL的关联UPDATE语句
针对刚才这道题,答案可以是如下两种形式的写法:
UPDATE A,B SET A.c1 = B.c1, A.c2 = B.c2 WHERE A.id = B.id
UPDATE A INNER JOIN B ON A.id=B.id SET A.c1 = B.c1,A.c2=B.c2
再加上B中age>50的条件:
UPDATE A,B set A.c1 = B.c1, A.c2 = B.c2 WHERE A.id = B.id and B.age > 50;
UPDATE A INNER JOIN B ON A.id = B.id set A.c1 = B.c1,A.c2 = B.c2 WHERE B.age > 50
MySQL的关联查询语句
六种关联查询
交叉连接(CROSS JOIN)
内连接(INNER JOIN)
外连接(LEFT JOIN/RIGHT JOIN)
联合查询(UNION与UNION ALL)
全连接(FULL JOIN)
交叉连接(CROSS JOIN)
SELECT * FROM A,B(,C)或者
SELECT * FROM A CROSS JOIN B (CROSS JOIN C)
#没有任何关联条件,结果是笛卡尔积,结果集会很大,没有意义,很少使用
内连接(INNER JOIN)
SELECT * FROM A,B WHERE A.id=B.id或者
SELECT * FROM A INNER JOIN B ON A.id=B.id
多表中同时符合某种条件的数据记录的集合,INNER JOIN可以缩写为JOIN
内连接分为三类
等值连接:ON A.id=B.id
不等值连接:ON A.id > B.id
自连接:SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
外连接(LEFT JOIN/RIGHT JOIN)
左外连接:LEFT OUTER JOIN, 以左表为主,先查询出左表,按照ON后的关联条件匹配右表,没有匹配到的用NULL填充,可以简写成LEFT JOIN
右外连接:RIGHT OUTER JOIN, 以右表为主,先查询出右表,按照ON后的关联条件匹配左表,没有匹配到的用NULL填充,可以简写成RIGHT JOIN
联合查询(UNION与UNION ALL)
SELECT * FROM A UNION SELECT * FROM B UNION ...
就是把多个结果集集中在一起,UNION前的结果为基准,需要注意的是联合查询的列数要相等,相同的记录行会合并
如果使用UNION ALL,不会合并重复的记录行
效率 UNION 高于 UNION ALL
全连接(FULL JOIN)
MySQL不支持全连接
可以使用LEFT JOIN 和UNION和RIGHT JOIN联合使用
SELECT * FROM A LEFT JOIN B ON A.id=B.id UNION
SELECT * FROM A RIGHT JOIN B ON A.id=B.id
嵌套查询
用一条SQL语句得结果作为另外一条SQL语句得条件,效率不好把握
SELECT * FROM A WHERE id IN (SELECT id FROM B)
解题方法
根据考题要搞清楚表的结果和多表之间的关系,根据想要的结果思考使用那种关联方式,通常把要查询的列先写出来,然后分析这些列都属于哪些表,才考虑使用关联查询
问题21:
为了记录足球比赛的结果,设计表如下:
team:参赛队伍表
match:赛程表
其中,match赛程表中的hostTeamID与guestTeamID都和team表中的teamID关联,查询2006-6-1到2006-7-1之间举行的所有比赛,并且用以下形式列出:拜仁 2:0 不莱梅 2006-6-21
首先列出需要查询的列:
表team
teamID teamName
表match
match ID
hostTeamID
guestTeamID
matchTime matchResult
其次列出结果列:
主队 结果 客对 时间
初步写一个基础的SQL:
SELECT hostTeamID,matchResult,matchTime guestTeamID from match where matchTime between "2006-6-1" and "2006-7-1";
通过外键联表,完成最终SQL:
select t1.teamName,m.matchResult,t2.teamName,m.matchTime from match as m left join team as t1 on m.hostTeamID = t1.teamID, left join team t2 on m.guestTeamID=t2.guestTeamID where m.matchTime between "2006-6-1" and "2006-7-1"
问题22:UNION与UNION ALL的区别?
如果使用UNION ALL,不会合并重复的记录行
效率 UNION 高于 UNION ALL
问题23:一个6亿的表a,一个3亿的表b,通过外键tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>50000 limit 200;
2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;
问题24:拷贝表( 拷贝数据, 源表名:a 目标表名:b)
insert into b(a, b, c) select d,e,f from a;
问题25:Student(S#,Sname,Sage,Ssex) 学生表 Course(C#,Cname,T#) 课程表 SC(S#,C#,score) 成绩表 Teacher(T#,Tname) 教师表 查询没学过“叶平”老师课的同学的学号、姓名
select Student.S#,Student.Sname
from Student
where S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname=’叶平’);
问题26:随机取出10条数据
SELECT * FROM users WHERE id >= ((SELECT MAX(id) FROM users)-(SELECT MIN(id) FROM users)) * RAND() + (SELECT MIN(id) FROM users) LIMIT 10
#此方法效率比直接用SELECT * FROM users order by rand() LIMIT 10高很多
问题27:请简述项目中优化SQL语句执行效率的方法,从哪些方面,SQL语句性能如何分析?
考点分析:
这道题主要考察的是查找分析SQL语句查询速度慢的方法
延伸考点:
优化查询过程中的数据访问
优化长难的查询语句
优化特定类型的查询语句
如何查找查询速度慢的原因
记录慢查询日志,分析查询日志,不要直接打开慢查询日志进行分析,这样比较浪费时间和精力,可以使用pt-query-digest工具进行分析
使用show profile
set profiling=1;开启,服务器上所有执行语句会记录执行时间,存到临时表中
show profiles
show profile for query 临时表ID
使用show status
show status会返回一些计数器,show global status会查看所有服务器级别的所有计数
有时根据这些计数,可以推测出哪些操作代价较高或者消耗时间多
show processlist
观察是否有大量线程处于不正常的状态或特征

最常问的MySQL面试题五——每个开发人员都应该知道
使用explain
分析单条SQL语句
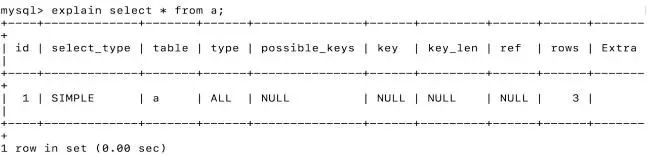
优化查询过程中的数据访问
访问数据太多导致查询性能下降
确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
确认MySQL服务器是否在分析大量不必要的数据行
避免犯如下SQL语句错误
查询不需要的数据。解决办法:使用limit解决
多表关联返回全部列。解决办法:指定列名
总是返回全部列。解决办法:避免使用SELECT *
重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
是否在扫描额外的记录。解决办法:
使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
改变数据库和表的结构,修改数据表范式
重写SQL语句,让优化器可以以更优的方式执行查询。
优化长难的查询语句
一个复杂查询还是多个简单查询
MySQL内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多
使用尽可能小的查询是好的,但是有时将一个大的查询分解为多个小的查询是很有必要的。
切分查询
将一个大的查询分为多个小的相同的查询
一次性删除1000万的数据要比一次删除1万,暂停一会的方案更加损耗服务器开销。
分解关联查询,让缓存的效率更高。
执行单个查询可以减少锁的竞争。
在应用层做关联更容易对数据库进行拆分。
查询效率会有大幅提升。
较少冗余记录的查询。
优化特定类型的查询语句
count(*)会忽略所有的列,直接统计所有列数,不要使用count(列名)
MyISAM中,没有任何where条件的count(*)非常快。
当有where条件时,MyISAM的count统计不一定比其它引擎快。
可以使用explain查询近似值,用近似值替代count(*)
增加汇总表
使用缓存
优化关联查询
确定ON或者USING子句中是否有索引。
确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
优化子查询
用关联查询替代
优化GROUP BY和DISTINCT
这两种查询据可以使用索引来优化,是最有效的优化方法
关联查询中,使用标识列分组的效率更高
如果不需要ORDER BY,进行GROUP BY时加ORDER BY NULL,MySQL不会再进行文件排序。
WITH ROLLUP超级聚合,可以挪到应用程序处理
优化LIMIT分页
LIMIT偏移量大的时候,查询效率较低
可以记录上次查询的最大ID,下次查询时直接根据该ID来查询
优化UNION查询
UNION ALL的效率高于UNION
优化WHERE子句
解题方法
对于此类考题,先说明如何定位低效SQL语句,然后根据SQL语句可能低效的原因做排查,先从索引着手,如果索引没有问题,考虑以上几个方面,数据访问的问题,长难查询句的问题还是一些特定类型优化的问题,逐一回答。
SQL语句优化的一些方法?
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=
3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20可以这样查询:select id from t where num=10 union all select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:select id from t where name like ‘%李%’若要提高效率,可以考虑全文检索。
7. 如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num可以改为强制查询使用索引:select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100应改为:select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’ ,name以abc开头的id应改为:
select id from t where name like ‘abc%’
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
整理自网络、SQL数据库开发
如果您觉得这篇文章对您有点用的话,麻烦您为本文来个四连:转发分享、点赞、点在看、留言,因为这将是我写作与分享更多优质文章的最强动力!
本公众号全部博文已整理成一个目录,请在公众号后台回复「
m」获取!
推荐阅读:
1、Redis是什么?看这一篇就够了!
2、请收好这一份详细 & 清晰的计算机网络基础学习指南!
3、打造一款高逼格的 Vim 神器!
4、超清晰的 DNS 原理入门指南!
5、开发者必备的 7 款效率提升工具!
6、IT运维面试问题总结-数据库、监控、网络管理(NoSQL、MongoDB、MySQL、Prometheus、Zabbix)
7、IT运维面试问题总结-LVS、Keepalived、HAProxy、Kubernetes、OpenShift等
8、IT运维面试问题总结-运维工具、开源应用(Ansible、Ceph、Docker、Apache、Nginx等)
9、IT运维面试问题总结-基础服务、磁盘管理、虚拟平台和系统管理
10、IT运维面试问题总结-Linux基础关注微信公众号「杰哥的IT之旅」,后台回复「1024」查看更多内容,回复「加群」备注:地区-职业方向-昵称 即可加入读者交流群。 点个[在看],是对杰哥最大的支持!
