
Netty17# 实战|Young GC时间过长导致RPC超时
引言
前几天一个业务负责的同事找老梁,说每次发布SOA拉入时就有少量报错。
报错的集中在RPC设置超时时间比较短的上游服务,比如设置300ms,发布完就好了。
我说最近没有发布新版本,应该不是中间件变更引起的。
同事说这问题存在好几个月了,他们一直想抓原因,一直没找到。
你咋早点不反馈到我这呢?就自己这么琢磨了几个月,够执着的。
老梁让他组织个会议,拉了小组两个同事一起参与下,聚焦复盘下问题。
忘了说了,我们SOA框架使用gRPC通信,gRPC底层使用Netty。
GC 日志
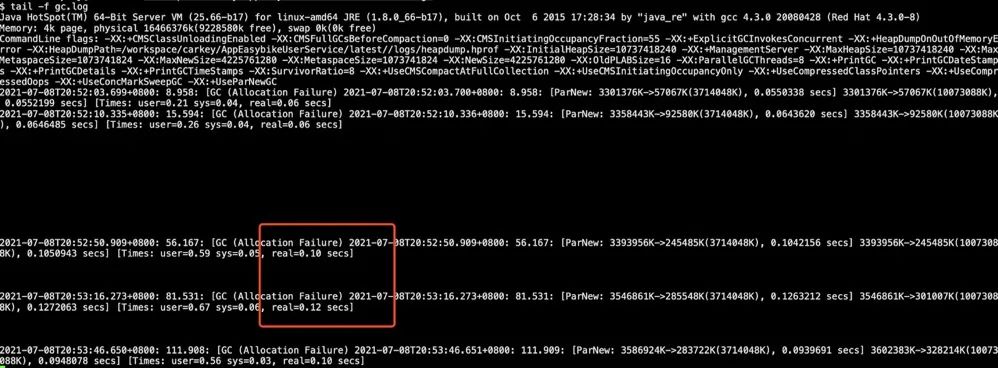
从GC日志现象来看,在第4次和第5次Young GC的时间过长,线上达到了900ms。

在测试环境复现,第4次Young GC的时间也超过500ms。

dump文件情况
dump一份看看当时内存情况,可以看到主要是MpscArrayQueue这个队列给占了。
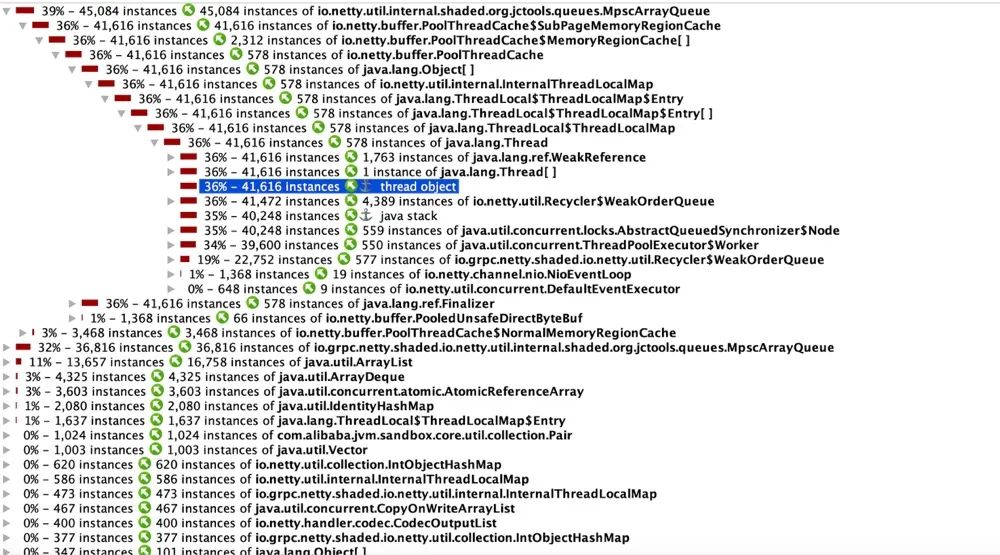
小结: 通过日志和dump文件看出,由于MpscArrayQueue对象占用过多,导致Young GC时间过长。
解决方式
这个问题到时网上也有人遇到,下面帖子指出通过以下设置解决。
-Dio.netty.allocator.useCacheForAllThreads=false
-Dio.grpc.netty.shaded.io.netty.allocator.useCacheForAllThreads=false
设置GC参数后,再看下GC日志发现,Young GC耗时100ms左右,通过线上灰度QPS和资源均可满足需求。
源码分析
先看下useCacheForAllThreads参数,用于设置DEFAULT_USE_CACHE_FOR_ALL_THREADS的值,默认为true,指会对所有线程对象进行缓存。
private static final boolean DEFAULT_USE_CACHE_FOR_ALL_THREADS;
DEFAULT_USE_CACHE_FOR_ALL_THREADS = SystemPropertyUtil.getBoolean(
"io.netty.allocator.useCacheForAllThreads", true);
如下代码,开启线程缓存会构造PoolThreadCache时会有一系列的值传入。
@Override
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
final Thread current = Thread.currentThread();
// 线程缓存开关
if (useCacheForAllThreads || current instanceof FastThreadLocalThread) {
final PoolThreadCache cache = new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
if (DEFAULT_CACHE_TRIM_INTERVAL_MILLIS > 0) {
final EventExecutor executor = ThreadExecutorMap.currentExecutor();
if (executor != null) {
executor.scheduleAtFixedRate(trimTask, DEFAULT_CACHE_TRIM_INTERVAL_MILLIS,
DEFAULT_CACHE_TRIM_INTERVAL_MILLIS, TimeUnit.MILLISECONDS);
}
}
return cache;
}
// No caching so just use 0 as sizes.
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);
}
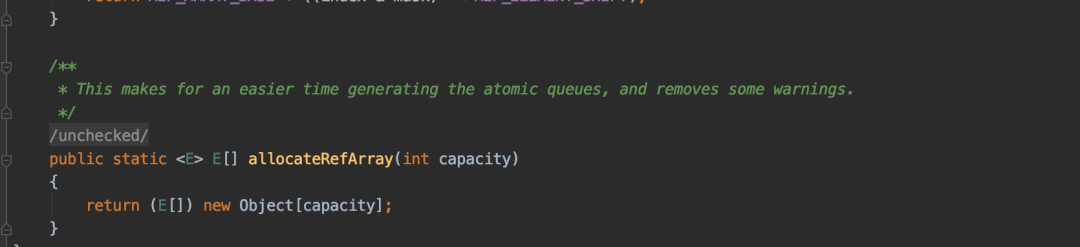
跟到下面可以看到通过构造MpscArrayQueue实现的,下面为对象数组。与dump文件显示的图示一致。

小结: 其实这部分在《Netty14# 池化内存之线程缓存》 有详细的分析,会形成如下图结构,顺带着把小结也摘录下。
Netty以chunk为单位(16M)向系统申请物理内存,Netty池化内存分成了4种内存类型。Tiny(0~512Byte),Small(512Byte~8KB),Normal(8KB~16MB),Huge(>16M) Netty对Tiny、Small、Normal做了缓存,针对不同的类型通过”数组+队列“继续切成不同的尺寸,每个尺寸内的缓存ByteBuffer大小相同,不同尺寸之间缓存的Buffer大小以2的N次增长。 Tiny类型从0到496被划分为32个尺寸(数组) Small类型从512到4096(4K)被划分4个尺寸 Normal类型从8192(8K)到32768(32K)被划分为3个尺寸 在内存分配时,先根据需要分配的内存大小判断属于那种内存类每个尺寸都维护有队列Queue,定位到尺寸规格也就拿到Queue中的实际缓存(PoolChunk)和指针(handle)并完成所需分配内存buffer的初始化。于该内存类型的哪个尺寸。 每个尺寸都维护有队列Queue,定位到尺寸规格也就拿到Queue中的实际缓存(PoolChunk)和指针(handle)并完成所需分配内存buffer的初始化。
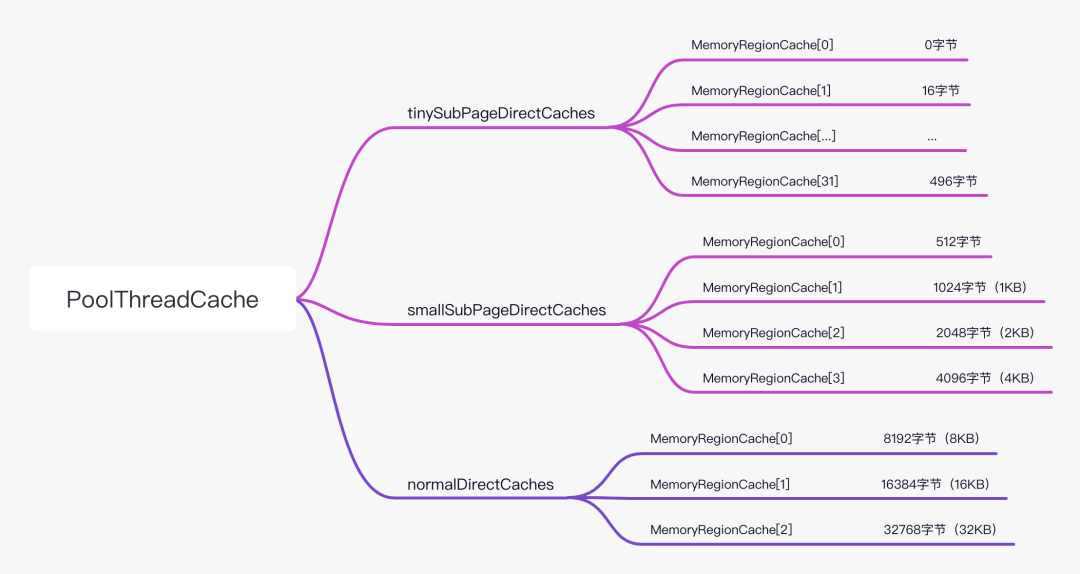
当把缓存关闭-Dio.netty.allocator.useCacheForAllThreads=false 时,上面这个结构也就不存在,构建的对象少了自然Young GC时间就短了。