
(建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系
上回就已经承诺过大家,一定会出 HTTP 的系列文章,今天终于整理完成了。作为一个 web 开发,HTTP 几乎是天天要打交道的东西,但我发现大部分人对 HTTP 只是浅尝辄止,对更多的细节及原理就了解不深了,在面试的时候感觉非常吃力。这篇文章就是为了帮助大家树立完整的 HTTP 知识体系,并达到一定的深度,从容地应对各种灵魂之问,也同时提升自己作为一个 web 开发的专业素养吧。这是本文的思维导图:
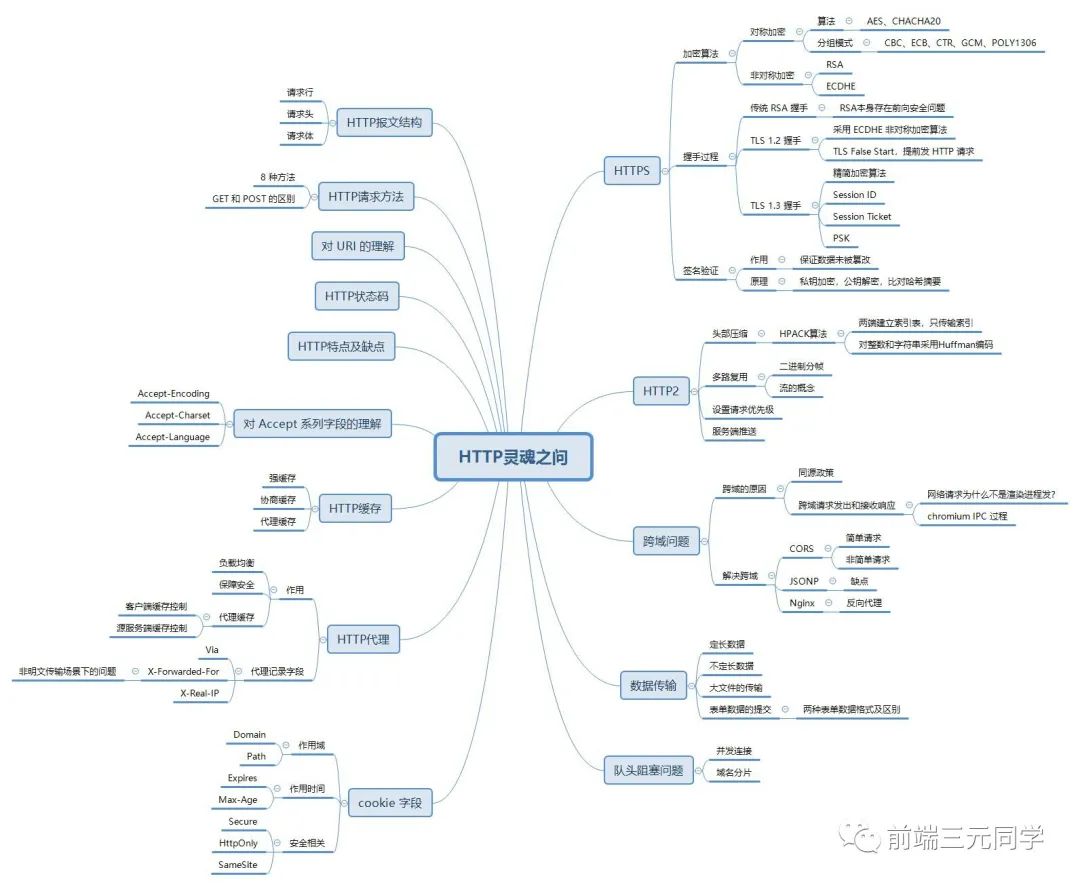
001. HTTP 报文结构是怎样的?
对于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。
而 HTTP 类似,也是header + body的结构,具体而言:
起始行 + 头部 + 空行 + 实体
由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。
起始行
对于请求报文来说,起始行类似下面这样:
GET /home HTTP/1.1
也就是方法 + 路径 + http版本。
对于响应报文来说,起始行一般张这个样:
HTTP/1.1 200 OK
响应报文的起始行也叫做状态行。由http版本、状态码和原因三部分组成。
值得注意的是,在起始行中,每两个部分之间用空格隔开,最后一个部分后面应该接一个换行,严格遵循ABNF语法规范。
头部
展示一下请求头和响应头在报文中的位置:

不管是请求头还是响应头,其中的字段是相当多的,而且牵扯到http非常多的特性,这里就不一一列举的,重点看看这些头部字段的格式:
- 字段名不区分大小写
- 字段名不允许出现空格,不可以出现下划线
_
- 字段名后面必须紧接着
:
空行
很重要,用来区分开头部和实体。
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。
实体
就是具体的数据了,也就是body部分。请求报文对应请求体, 响应报文对应响应体。
002. 如何理解 HTTP 的请求方法?
有哪些请求方法?
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
- TRACE: 追踪请求-响应的传输路径
GET 和 POST 有什么区别?
首先最直观的是语义上的区别。
而后又有这样一些具体的差别:
- 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,
GET是幂等的,而POST不是。(幂等表示执行相同的操作,结果也是相同的) - 从TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
003: 如何理解 URI?
URI, 全称为(Uniform Resource Identifier), 也就是统一资源标识符,它的作用很简单,就是区分互联网上不同的资源。
但是,它并不是我们常说的网址, 网址指的是URL, 实际上URI包含了URN和URL两个部分,由于 URL 过于普及,就默认将 URI 视为 URL 了。
URI 的结构
URI 真正最完整的结构是这样的。

可能你会有疑问,好像跟平时见到的不太一样啊!先别急,我们来一一拆解。
scheme 表示协议名,比如http, https, file等等。后面必须和://连在一起。
user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用。
host:port表示主机名和端口。
path表示请求路径,标记资源所在位置。
query表示查询参数,为key=val这种形式,多个键值对之间用&隔开。
fragment表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置。
举个例子:
https://www.baidu.com/s?wd=HTTP&rsv_spt=1
这个 URI 中,https即scheme部分,www.baidu.com为host:port部分(注意,http 和 https 的默认端口分别为80、443),/s为path部分,而wd=HTTP&rsv_spt=1就是query部分。
URI 编码
URI 只能使用ASCII, ASCII 之外的字符是不支持显示的,而且还有一部分符号是界定符,如果不加以处理就会导致解析出错。
因此,URI 引入了编码机制,将所有非 ASCII 码字符和界定符转为十六进制字节值,然后在前面加个%。
如,空格被转义成了%20,三元被转义成了%E4%B8%89%E5%85%83。
004: 如何理解 HTTP 状态码?
RFC 规定 HTTP 的状态码为三位数,被分为五类:
- 1xx: 表示目前是协议处理的中间状态,还需要后续操作。
- 2xx: 表示成功状态。
- 3xx: 重定向状态,资源位置发生变动,需要重新请求。
- 4xx: 请求报文有误。
- 5xx: 服务器端发生错误。
接下来就一一分析这里面具体的状态码。
1xx
101 Switching Protocols。在HTTP升级为WebSocket的时候,如果服务器同意变更,就会发送状态码 101。
2xx
200 OK是见得最多的成功状态码。通常在响应体中放有数据。
204 No Content含义与 200 相同,但响应头后没有 body 数据。
206 Partial Content顾名思义,表示部分内容,它的使用场景为 HTTP 分块下载和断电续传,当然也会带上相应的响应头字段Content-Range。
3xx
301 Moved Permanently即永久重定向,对应着302 Found,即临时重定向。
比如你的网站从 HTTP 升级到了 HTTPS 了,以前的站点再也不用了,应当返回301,这个时候浏览器默认会做缓存优化,在第二次访问的时候自动访问重定向的那个地址。
而如果只是暂时不可用,那么直接返回302即可,和301不同的是,浏览器并不会做缓存优化。
304 Not Modified: 当协商缓存命中时会返回这个状态码。详见浏览器缓存
4xx
400 Bad Request: 开发者经常看到一头雾水,只是笼统地提示了一下错误,并不知道哪里出错了。
403 Forbidden: 这实际上并不是请求报文出错,而是服务器禁止访问,原因有很多,比如法律禁止、信息敏感。
404 Not Found: 资源未找到,表示没在服务器上找到相应的资源。
405 Method Not Allowed: 请求方法不被服务器端允许。
406 Not Acceptable: 资源无法满足客户端的条件。
408 Request Timeout: 服务器等待了太长时间。
409 Conflict: 多个请求发生了冲突。
413 Request Entity Too Large: 请求体的数据过大。
414 Request-URI Too Long: 请求行里的 URI 太大。
429 Too Many Request: 客户端发送的请求过多。
431 Request Header Fields Too Large请求头的字段内容太大。
5xx
500 Internal Server Error: 仅仅告诉你服务器出错了,出了啥错咱也不知道。
501 Not Implemented: 表示客户端请求的功能还不支持。
502 Bad Gateway: 服务器自身是正常的,但访问的时候出错了,啥错误咱也不知道。
503 Service Unavailable: 表示服务器当前很忙,暂时无法响应服务。
005: 简要概括一下 HTTP 的特点?HTTP 有哪些缺点?
HTTP 特点
HTTP 的特点概括如下:
灵活可扩展,主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
可靠传输。HTTP 基于 TCP/IP,因此把这一特性继承了下来。这属于 TCP 的特性,不具体介绍了。
请求-应答。也就是
一发一收、有来有回, 当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。无状态。这里的状态是指通信过程的上下文信息,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
HTTP 缺点
无状态
所谓的优点和缺点还是要分场景来看的,对于 HTTP 而言,最具争议的地方在于它的无状态。
在需要长连接的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。
但与此同时,另外一些应用仅仅只是为了获取一些数据,不需要保存连接上下文信息,无状态反而减少了网络开销,成为了 http 的优点。
明文传输
即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。
这当然对于调试提供了便利,但同时也让 HTTP 的报文信息暴露给了外界,给攻击者也提供了便利。WIFI陷阱就是利用 HTTP 明文传输的缺点,诱导你连上热点,然后疯狂抓你所有的流量,从而拿到你的敏感信息。
队头阻塞问题
当 http 开启长连接时,共用一个 TCP 连接,同一时刻只能处理一个请求,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态,也就是著名的队头阻塞问题。接下来会有一小节讨论这个问题。
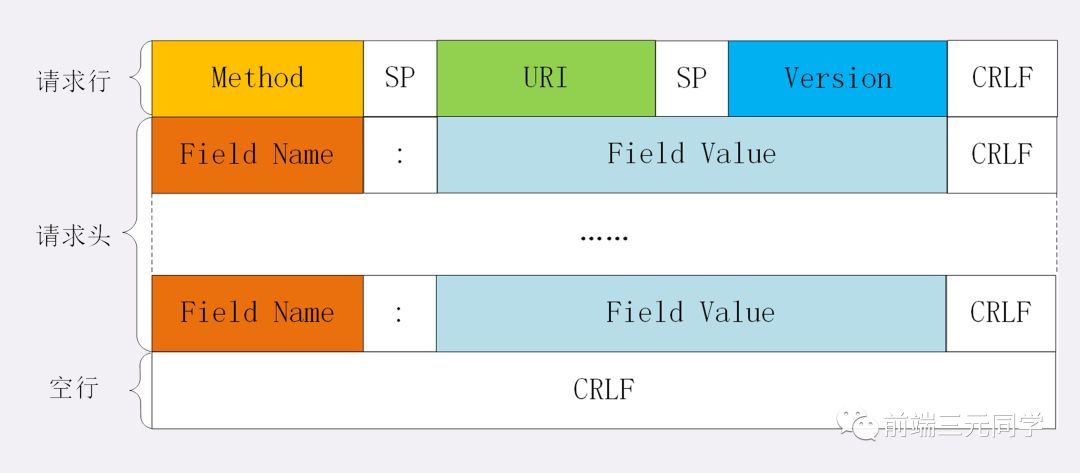
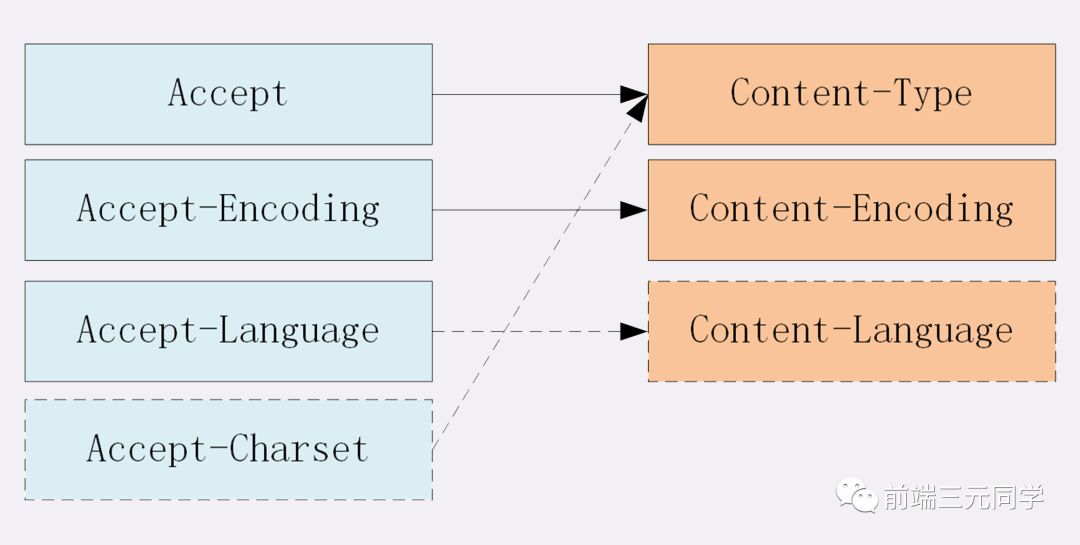
006: 对 Accept 系列字段了解多少?
对于Accept系列字段的介绍分为四个部分: 数据格式、压缩方式、支持语言和字符集。
数据格式
上一节谈到 HTTP 灵活的特性,它支持非常多的数据格式,那么这么多格式的数据一起到达客户端,客户端怎么知道它的格式呢?
当然,最低效的方式是直接猜,有没有更好的方式呢?直接指定可以吗?
答案是肯定的。不过首先需要介绍一个标准——MIME(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)。它首先用在电子邮件系统中,让邮件可以发任意类型的数据,这对于 HTTP 来说也是通用的。
因此,HTTP 从MIME type取了一部分来标记报文 body 部分的数据类型,这些类型体现在Content-Type这个字段,当然这是针对于发送端而言,接收端想要收到特定类型的数据,也可以用Accept字段。
具体而言,这两个字段的取值可以分为下面几类:
- text:text/html, text/plain, text/css 等
- image: image/gif, image/jpeg, image/png 等
- audio/video: audio/mpeg, video/mp4 等
- application: application/json, application/javascript, application/pdf, application/octet-stream
压缩方式
当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的Content-Encoding字段上, 同样的,接收什么样的压缩方式体现在了接受方的Accept-Encoding字段上。这个字段的取值有下面几种:
- gzip: 当今最流行的压缩格式
- deflate: 另外一种著名的压缩格式
- br: 一种专门为 HTTP 发明的压缩算法
// 发送端
Content-Encoding: gzip
// 接收端
Accept-Encoding: gizp
支持语言
对于发送方而言,还有一个Content-Language字段,在需要实现国际化的方案当中,可以用来指定支持的语言,在接受方对应的字段为Accept-Language。如:
// 发送端
Content-Language: zh-CN, zh, en
// 接收端
Accept-Language: zh-CN, zh, en
字符集
最后是一个比较特殊的字段, 在接收端对应为Accept-Charset,指定可以接受的字符集,而在发送端并没有对应的Content-Charset, 而是直接放在了Content-Type中,以charset属性指定。如:
// 发送端
Content-Type: text/html; charset=utf-8
// 接收端
Accept-Charset: charset=utf-8
最后以一张图来总结一下吧:
007: 对于定长和不定长的数据,HTTP 是怎么传输的?
定长包体
对于定长包体而言,发送端在传输的时候一般会带上Content-Length, 来指明包体的长度。
我们用一个nodejs服务器来模拟一下:
const http = require('http');
const server = http.createServer();
server.on('request', (req, res) => {
if(req.url === '/') {
res.setHeader('Content-Type', 'text/plain');
res.setHeader('Content-Length', 10);
res.write("helloworld");
}
})
server.listen(8081, () => {
console.log("成功启动");
})
启动后访问: localhost:8081。
浏览器中显示如下:
helloworld
这是长度正确的情况,那不正确的情况是如何处理的呢?
我们试着把这个长度设置的小一些:
res.setHeader('Content-Length', 8);
重启服务,再次访问,现在浏览器中内容如下:
hellowor
那后面的ld哪里去了呢?实际上在 http 的响应体中直接被截去了。
然后我们试着将这个长度设置得大一些:
res.setHeader('Content-Length', 12);
此时浏览器显示如下:

直接无法显示了。可以看到Content-Length对于 http 传输过程起到了十分关键的作用,如果设置不当可以直接导致传输失败。
不定长包体
上述是针对于定长包体,那么对于不定长包体而言是如何传输的呢?
这里就必须介绍另外一个 http 头部字段了:
Transfer-Encoding: chunked
表示分块传输数据,设置这个字段后会自动产生两个效果:
- Content-Length 字段会被忽略
- 基于长连接持续推送动态内容
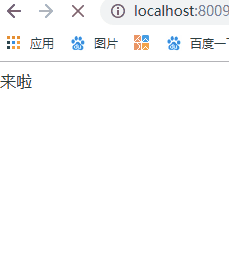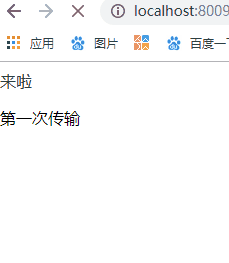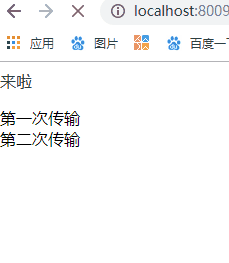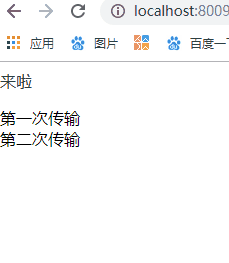
我们依然以一个实际的例子来模拟分块传输,nodejs 程序如下:
const http = require('http');
const server = http.createServer();
server.on('request', (req, res) => {
if(req.url === '/') {
res.setHeader('Content-Type', 'text/html; charset=utf8');
res.setHeader('Content-Length', 10);
res.setHeader('Transfer-Encoding', 'chunked');
res.write("来啦
");
setTimeout(() => {
res.write("第一次传输
");
}, 1000);
setTimeout(() => {
res.write("第二次传输");
res.end()
}, 2000);
}
})
server.listen(8009, () => {
console.log("成功启动");
})
访问效果入下:
用 telnet 抓到的响应如下:
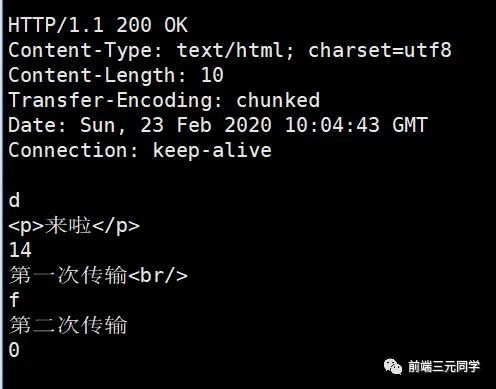
注意,Connection: keep-alive及之前的为响应行和响应头,后面的内容为响应体,这两部分用换行符隔开。
响应体的结构比较有意思,如下所示:
chunk长度(16进制的数)
第一个chunk的内容
chunk长度(16进制的数)
第二个chunk的内容
......
0
最后是留有有一个空行的,这一点请大家注意。
以上便是 http 对于定长数据和不定长数据的传输方式。
008: HTTP 如何处理大文件的传输?
对于几百 M 甚至上 G 的大文件来说,如果要一口气全部传输过来显然是不现实的,会有大量的等待时间,严重影响用户体验。因此,HTTP 针对这一场景,采取了范围请求的解决方案,允许客户端仅仅请求一个资源的一部分。
如何支持
当然,前提是服务器要支持范围请求,要支持这个功能,就必须加上这样一个响应头:
Accept-Ranges: none
用来告知客户端这边是支持范围请求的。
Range 字段拆解
而对于客户端而言,它需要指定请求哪一部分,通过Range这个请求头字段确定,格式为bytes=x-y。接下来就来讨论一下这个 Range 的书写格式:
- 0-499表示从开始到第 499 个字节。
- 500- 表示从第 500 字节到文件终点。
- -100表示文件的最后100个字节。
服务器收到请求之后,首先验证范围是否合法,如果越界了那么返回416错误码,否则读取相应片段,返回206状态码。
同时,服务器需要添加Content-Range字段,这个字段的格式根据请求头中Range字段的不同而有所差异。
具体来说,请求单段数据和请求多段数据,响应头是不一样的。
举个例子:
// 单段数据
Range: bytes=0-9
// 多段数据
Range: bytes=0-9, 30-39
接下来我们就分别来讨论着两种情况。
单段数据
对于单段数据的请求,返回的响应如下:
HTTP/1.1 206 Partial Content
Content-Length: 10
Accept-Ranges: bytes
Content-Range: bytes 0-9/100
i am xxxxx
值得注意的是Content-Range字段,0-9表示请求的返回,100表示资源的总大小,很好理解。
多段数据
接下来我们看看多段请求的情况。得到的响应会是下面这个形式:
HTTP/1.1 206 Partial Content
Content-Type: multipart/byteranges; boundary=00000010101
Content-Length: 189
Connection: keep-alive
Accept-Ranges: bytes
--00000010101
Content-Type: text/plain
Content-Range: bytes 0-9/96
i am xxxxx
--00000010101
Content-Type: text/plain
Content-Range: bytes 20-29/96
eex jspy e
--00000010101--
这个时候出现了一个非常关键的字段Content-Type: multipart/byteranges;boundary=00000010101,它代表了信息量是这样的:
- 请求一定是多段数据请求
- 响应体中的分隔符是 00000010101
因此,在响应体中各段数据之间会由这里指定的分隔符分开,而且在最后的分隔末尾添上--表示结束。
以上就是 http 针对大文件传输所采用的手段。
009: HTTP 中如何处理表单数据的提交?
在 http 中,有两种主要的表单提交的方式,体现在两种不同的Content-Type取值:
- application/x-www-form-urlencoded
- multipart/form-data
由于表单提交一般是POST请求,很少考虑GET,因此这里我们将默认提交的数据放在请求体中。
application/x-www-form-urlencoded
对于application/x-www-form-urlencoded格式的表单内容,有以下特点:
- 其中的数据会被编码成以
&分隔的键值对 - 字符以URL编码方式编码。
如:
// 转换过程: {a: 1, b: 2} -> a=1&b=2 -> 如下(最终形式)
"a%3D1%26b%3D2"
multipart/form-data
对于multipart/form-data而言:
- 请求头中的
Content-Type字段会包含boundary,且boundary的值有浏览器默认指定。例:Content-Type: multipart/form-data;boundary=----WebkitFormBoundaryRRJKeWfHPGrS4LKe。 - 数据会分为多个部分,每两个部分之间通过分隔符来分隔,每部分表述均有 HTTP 头部描述子包体,如
Content-Type,在最后的分隔符会加上--表示结束。
相应的请求体是下面这样:
Content-Disposition: form-data;name="data1";
Content-Type: text/plain
data1
----WebkitFormBoundaryRRJKeWfHPGrS4LKe
Content-Disposition: form-data;name="data2";
Content-Type: text/plain
data2
----WebkitFormBoundaryRRJKeWfHPGrS4LKe--
小结
值得一提的是,multipart/form-data 格式最大的特点在于:每一个表单元素都是独立的资源表述。另外,你可能在写业务的过程中,并没有注意到其中还有boundary的存在,如果你打开抓包工具,确实可以看到不同的表单元素被拆分开了,之所以在平时感觉不到,是以为浏览器和 HTTP 给你封装了这一系列操作。
而且,在实际的场景中,对于图片等文件的上传,基本采用multipart/form-data而不用application/x-www-form-urlencoded,因为没有必要做 URL 编码,带来巨大耗时的同时也占用了更多的空间。
010: HTTP1.1 如何解决 HTTP 的队头阻塞问题?
什么是 HTTP 队头阻塞?
从前面的小节可以知道,HTTP 传输是基于请求-应答的模式进行的,报文必须是一发一收,但值得注意的是,里面的任务被放在一个任务队列中串行执行,一旦队首的请求处理太慢,就会阻塞后面请求的处理。这就是著名的HTTP队头阻塞问题。
并发连接
对于一个域名允许分配多个长连接,那么相当于增加了任务队列,不至于一个队伍的任务阻塞其它所有任务。在RFC2616规定过客户端最多并发 2 个连接,不过事实上在现在的浏览器标准中,这个上限要多很多,Chrome 中是 6 个。
但其实,即使是提高了并发连接,还是不能满足人们对性能的需求。
域名分片
一个域名不是可以并发 6 个长连接吗?那我就多分几个域名。
比如 content1.sanyuan.com 、content2.sanyuan.com。
这样一个sanyuan.com域名下可以分出非常多的二级域名,而它们都指向同样的一台服务器,能够并发的长连接数更多了,事实上也更好地解决了队头阻塞的问题。
011: 对 Cookie 了解多少?
Cookie 简介
前面说到了 HTTP 是一个无状态的协议,每次 http 请求都是独立、无关的,默认不需要保留状态信息。但有时候需要保存一些状态,怎么办呢?
HTTP 为此引入了 Cookie。Cookie 本质上就是浏览器里面存储的一个很小的文本文件,内部以键值对的方式来存储(在chrome开发者面板的Application这一栏可以看到)。向同一个域名下发送请求,都会携带相同的 Cookie,服务器拿到 Cookie 进行解析,便能拿到客户端的状态。而服务端可以通过响应头中的Set-Cookie字段来对客户端写入Cookie。举例如下:
// 请求头
Cookie: a=xxx;b=xxx
// 响应头
Set-Cookie: a=xxx
set-Cookie: b=xxx
Cookie 属性
生存周期
Cookie 的有效期可以通过Expires和Max-Age两个属性来设置。
- Expires即
过期时间 - Max-Age用的是一段时间间隔,单位是秒,从浏览器收到报文开始计算。
若 Cookie 过期,则这个 Cookie 会被删除,并不会发送给服务端。
作用域
关于作用域也有两个属性: Domain和path, 给 Cookie 绑定了域名和路径,在发送请求之前,发现域名或者路径和这两个属性不匹配,那么就不会带上 Cookie。值得注意的是,对于路径来说,/表示域名下的任意路径都允许使用 Cookie。
安全相关
如果带上Secure,说明只能通过 HTTPS 传输 cookie。
如果 cookie 字段带上HttpOnly,那么说明只能通过 HTTP 协议传输,不能通过 JS 访问,这也是预防 XSS 攻击的重要手段。
相应的,对于 CSRF 攻击的预防,也有SameSite属性。
SameSite可以设置为三个值,Strict、Lax和None。
a. 在Strict模式下,浏览器完全禁止第三方请求携带Cookie。比如请求sanyuan.com网站只能在sanyuan.com域名当中请求才能携带 Cookie,在其他网站请求都不能。
b. 在Lax模式,就宽松一点了,但是只能在 get 方法提交表单况或者a 标签发送 get 请求的情况下可以携带 Cookie,其他情况均不能。
c. 在None模式下,也就是默认模式,请求会自动携带上 Cookie。
Cookie 的缺点
容量缺陷。Cookie 的体积上限只有
4KB,只能用来存储少量的信息。性能缺陷。Cookie 紧跟域名,不管域名下面的某一个地址需不需要这个 Cookie ,请求都会携带上完整的 Cookie,这样随着请求数的增多,其实会造成巨大的性能浪费的,因为请求携带了很多不必要的内容。但可以通过
Domain和Path指定作用域来解决。安全缺陷。由于 Cookie 以纯文本的形式在浏览器和服务器中传递,很容易被非法用户截获,然后进行一系列的篡改,在 Cookie 的有效期内重新发送给服务器,这是相当危险的。另外,在
HttpOnly为 false 的情况下,Cookie 信息能直接通过 JS 脚本来读取。
012: 如何理解 HTTP 代理?
我们知道在 HTTP 是基于请求-响应模型的协议,一般由客户端发请求,服务器来进行响应。
当然,也有特殊情况,就是代理服务器的情况。引入代理之后,作为代理的服务器相当于一个中间人的角色,对于客户端而言,表现为服务器进行响应;而对于源服务器,表现为客户端发起请求,具有双重身份。
那代理服务器到底是用来做什么的呢?
功能
负载均衡。客户端的请求只会先到达代理服务器,后面到底有多少源服务器,IP 都是多少,客户端是不知道的。因此,这个代理服务器可以拿到这个请求之后,可以通过特定的算法分发给不同的源服务器,让各台源服务器的负载尽量平均。当然,这样的算法有很多,包括随机算法、轮询、一致性hash、LRU
(最近最少使用)等等,不过这些算法并不是本文的重点,大家有兴趣自己可以研究一下。保障安全。利用心跳机制监控后台的服务器,一旦发现故障机就将其踢出集群。并且对于上下行的数据进行过滤,对非法 IP 限流,这些都是代理服务器的工作。
缓存代理。将内容缓存到代理服务器,使得客户端可以直接从代理服务器获得而不用到源服务器那里。下一节详细拆解。
相关头部字段
Via
代理服务器需要标明自己的身份,在 HTTP 传输中留下自己的痕迹,怎么办呢?
通过Via字段来记录。举个例子,现在中间有两台代理服务器,在客户端发送请求后会经历这样一个过程:
客户端 -> 代理1 -> 代理2 -> 源服务器
在源服务器收到请求后,会在请求头拿到这个字段:
Via: proxy_server1, proxy_server2
而源服务器响应时,最终在客户端会拿到这样的响应头:
Via: proxy_server2, proxy_server1
可以看到,Via中代理的顺序即为在 HTTP 传输中报文传达的顺序。
X-Forwarded-For
字面意思就是为谁转发, 它记录的是请求方的IP地址(注意,和Via区分开,X-Forwarded-For记录的是请求方这一个IP)。
X-Real-IP
是一种获取用户真实 IP 的字段,不管中间经过多少代理,这个字段始终记录最初的客户端的IP。
相应的,还有X-Forwarded-Host和X-Forwarded-Proto,分别记录客户端(注意哦,不包括代理)的域名和协议名。
X-Forwarded-For产生的问题
前面可以看到,X-Forwarded-For这个字段记录的是请求方的 IP,这意味着每经过一个不同的代理,这个字段的名字都要变,从客户端到代理1,这个字段是客户端的 IP,从代理1到代理2,这个字段就变为了代理1的 IP。
但是这会产生两个问题:
意味着代理必须解析 HTTP 请求头,然后修改,比直接转发数据性能下降。
在 HTTPS 通信加密的过程中,原始报文是不允许修改的。
由此产生了代理协议,一般使用明文版本,只需要在 HTTP 请求行上面加上这样格式的文本即可:
// PROXY + TCP4/TCP6 + 请求方地址 + 接收方地址 + 请求端口 + 接收端口
PROXY TCP4 0.0.0.1 0.0.0.2 1111 2222
GET / HTTP/1.1
...
这样就可以解决X-Forwarded-For带来的问题了。
013: 如何理解 HTTP 缓存及缓存代理?
关于强缓存和协商缓存的内容,我已经在【说一说浏览器缓存】做了详细分析,小结如下:
首先通过 Cache-Control 验证强缓存是否可用
- 如果强缓存可用,直接使用
- 否则进入协商缓存,即发送 HTTP 请求,服务器通过请求头中的
If-Modified-Since或者If-None-Match这些条件请求字段检查资源是否更新- 若资源更新,返回资源和200状态码
- 否则,返回304,告诉浏览器直接从缓存获取资源
这一节我们主要来说说另外一种缓存方式: 代理缓存。
为什么产生代理缓存?
对于源服务器来说,它也是有缓存的,比如Redis, Memcache,但对于 HTTP 缓存来说,如果每次客户端缓存失效都要到源服务器获取,那给源服务器的压力是很大的。
由此引入了缓存代理的机制。让代理服务器接管一部分的服务端HTTP缓存,客户端缓存过期后就近到代理缓存中获取,代理缓存过期了才请求源服务器,这样流量巨大的时候能明显降低源服务器的压力。
那缓存代理究竟是如何做到的呢?
总的来说,缓存代理的控制分为两部分,一部分是源服务器端的控制,一部分是客户端的控制。
源服务器的缓存控制
private 和 public
在源服务器的响应头中,会加上Cache-Control这个字段进行缓存控制字段,那么它的值当中可以加入private或者public表示是否允许代理服务器缓存,前者禁止,后者为允许。
比如对于一些非常私密的数据,如果缓存到代理服务器,别人直接访问代理就可以拿到这些数据,是非常危险的,因此对于这些数据一般是不会允许代理服务器进行缓存的,将响应头部的Cache-Control设为private,而不是public。
proxy-revalidate
must-revalidate的意思是客户端缓存过期就去源服务器获取,而proxy-revalidate则表示代理服务器的缓存过期后到源服务器获取。
s-maxage
s是share的意思,限定了缓存在代理服务器中可以存放多久,和限制客户端缓存时间的max-age并不冲突。
讲了这几个字段,我们不妨来举个小例子,源服务器在响应头中加入这样一个字段:
Cache-Control: public, max-age=1000, s-maxage=2000
相当于源服务器说: 我这个响应是允许代理服务器缓存的,客户端缓存过期了到代理中拿,并且在客户端的缓存时间为 1000 秒,在代理服务器中的缓存时间为 2000 s。
客户端的缓存控制
max-stale 和 min-fresh
在客户端的请求头中,可以加入这两个字段,来对代理服务器上的缓存进行宽容和限制操作。比如:
max-stale: 5
表示客户端到代理服务器上拿缓存的时候,即使代理缓存过期了也不要紧,只要过期时间在5秒之内,还是可以从代理中获取的。
又比如:
min-fresh: 5
表示代理缓存需要一定的新鲜度,不要等到缓存刚好到期再拿,一定要在到期前 5 秒之前的时间拿,否则拿不到。
only-if-cached
这个字段加上后表示客户端只会接受代理缓存,而不会接受源服务器的响应。如果代理缓存无效,则直接返回504(Gateway Timeout)。
以上便是缓存代理的内容,涉及的字段比较多,希望能好好回顾一下,加深理解。
014: 什么是跨域?浏览器如何拦截响应?如何解决?
在前后端分离的开发模式中,经常会遇到跨域问题,即 Ajax 请求发出去了,服务器也成功响应了,前端就是拿不到这个响应。接下来我们就来好好讨论一下这个问题。
什么是跨域
回顾一下 URI 的组成:
浏览器遵循同源政策(scheme(协议)、host(主机)和port(端口)都相同则为同源)。非同源站点有这样一些限制:
- 不能读取和修改对方的 DOM
- 不读访问对方的 Cookie、IndexDB 和 LocalStorage
- 限制 XMLHttpRequest 请求。(后面的话题着重围绕这个)
当浏览器向目标 URI 发 Ajax 请求时,只要当前 URL 和目标 URL 不同源,则产生跨域,被称为跨域请求。
跨域请求的响应一般会被浏览器所拦截,注意,是被浏览器拦截,响应其实是成功到达客户端了。那这个拦截是如何发生呢?
首先要知道的是,浏览器是多进程的,以 Chrome 为例,进程组成如下:

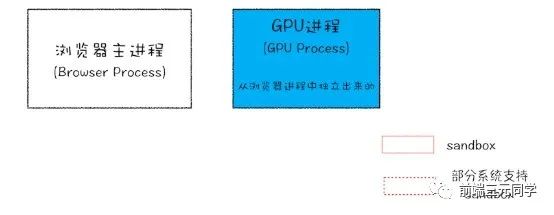
WebKit 渲染引擎和V8 引擎都在渲染进程当中。
当xhr.send被调用,即 Ajax 请求准备发送的时候,其实还只是在渲染进程的处理。为了防止黑客通过脚本触碰到系统资源,浏览器将每一个渲染进程装进了沙箱,并且为了防止 CPU 芯片一直存在的Spectre 和 Meltdown漏洞,采取了站点隔离的手段,给每一个不同的站点(一级域名不同)分配了沙箱,互不干扰。具体见YouTube上Chromium安全团队的演讲视频。
在沙箱当中的渲染进程是没有办法发送网络请求的,那怎么办?只能通过网络进程来发送。那这样就涉及到进程间通信(IPC,Inter Process Communication)了。接下来我们看看 chromium 当中进程间通信是如何完成的,在 chromium 源码中调用顺序如下:
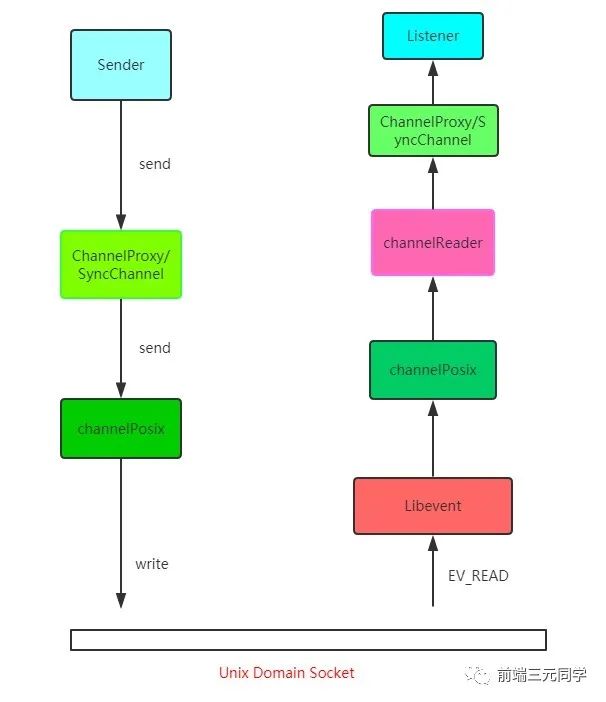
可能看了你会比较懵,如果想深入了解可以去看看 chromium 最新的源代码,IPC源码地址及Chromium IPC源码解析文章。
总的来说就是利用Unix Domain Socket套接字,配合事件驱动的高性能网络并发库libevent完成进程的 IPC 过程。
好,现在数据传递给了浏览器主进程,主进程接收到后,才真正地发出相应的网络请求。
在服务端处理完数据后,将响应返回,主进程检查到跨域,且没有cors(后面会详细说)响应头,将响应体全部丢掉,并不会发送给渲染进程。这就达到了拦截数据的目的。
接下来我们来说一说解决跨域问题的几种方案。
CORS
CORS 其实是 W3C 的一个标准,全称是跨域资源共享。它需要浏览器和服务器的共同支持,具体来说,非 IE 和 IE10 以上支持CORS,服务器需要附加特定的响应头,后面具体拆解。不过在弄清楚 CORS 的原理之前,我们需要清楚两个概念: 简单请求和非简单请求。
浏览器根据请求方法和请求头的特定字段,将请求做了一下分类,具体来说规则是这样,凡是满足下面条件的属于简单请求:
- 请求方法为 GET、POST 或者 HEAD
- 请求头的取值范围: Accept、Accept-Language、Content-Language、Content-Type(只限于三个值
application/x-www-form-urlencoded、multipart/form-data、text/plain)
浏览器画了这样一个圈,在这个圈里面的就是简单请求, 圈外面的就是非简单请求,然后针对这两种不同的请求进行不同的处理。
简单请求
请求发出去之前,浏览器做了什么?
它会自动在请求头当中,添加一个Origin字段,用来说明请求来自哪个源。服务器拿到请求之后,在回应时对应地添加Access-Control-Allow-Origin字段,如果Origin不在这个字段的范围中,那么浏览器就会将响应拦截。
因此,Access-Control-Allow-Origin字段是服务器用来决定浏览器是否拦截这个响应,这是必需的字段。与此同时,其它一些可选的功能性的字段,用来描述如果不会拦截,这些字段将会发挥各自的作用。
Access-Control-Allow-Credentials。这个字段是一个布尔值,表示是否允许发送 Cookie,对于跨域请求,浏览器对这个字段默认值设为 false,而如果需要拿到浏览器的 Cookie,需要添加这个响应头并设为true, 并且在前端也需要设置withCredentials属性:
let xhr = new XMLHttpRequest();
xhr.withCredentials = true;
Access-Control-Expose-Headers。这个字段是给 XMLHttpRequest 对象赋能,让它不仅可以拿到基本的 6 个响应头字段(包括Cache-Control、Content-Language、Content-Type、Expires、Last-Modified和Pragma), 还能拿到这个字段声明的响应头字段。比如这样设置:
Access-Control-Expose-Headers: aaa
那么在前端可以通过 XMLHttpRequest.getResponseHeader('aaa') 拿到 aaa 这个字段的值。
非简单请求
非简单请求相对而言会有些不同,体现在两个方面: 预检请求和响应字段。
我们以 PUT 方法为例。
var url = 'http://xxx.com';
var xhr = new XMLHttpRequest();
xhr.open('PUT', url, true);
xhr.setRequestHeader('X-Custom-Header', 'xxx');
xhr.send();
当这段代码执行后,首先会发送预检请求。这个预检请求的请求行和请求体是下面这个格式:
OPTIONS / HTTP/1.1
Origin: 当前地址
Host: xxx.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: X-Custom-Header
预检请求的方法是OPTIONS,同时会加上Origin源地址和Host目标地址,这很简单。同时也会加上两个关键的字段:
- Access-Control-Request-Method, 列出 CORS 请求用到哪个HTTP方法
- Access-Control-Request-Headers,指定 CORS 请求将要加上什么请求头
这是预检请求。接下来是响应字段,响应字段也分为两部分,一部分是对于预检请求的响应,一部分是对于 CORS 请求的响应。
预检请求的响应。如下面的格式:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
Access-Control-Allow-Credentials: true
Access-Control-Max-Age: 1728000
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
其中有这样几个关键的响应头字段:
- Access-Control-Allow-Origin: 表示可以允许请求的源,可以填具体的源名,也可以填
*表示允许任意源请求。 - Access-Control-Allow-Methods: 表示允许的请求方法列表。
- Access-Control-Allow-Credentials: 简单请求中已经介绍。
- Access-Control-Allow-Headers: 表示允许发送的请求头字段
- Access-Control-Max-Age: 预检请求的有效期,在此期间,不用发出另外一条预检请求。
在预检请求的响应返回后,如果请求不满足响应头的条件,则触发XMLHttpRequest的onerror方法,当然后面真正的CORS请求也不会发出去了。
CORS 请求的响应。绕了这么一大转,到了真正的 CORS 请求就容易多了,现在它和简单请求的情况是一样的。浏览器自动加上Origin字段,服务端响应头返回Access-Control-Allow-Origin。可以参考以上简单请求部分的内容。
JSONP
虽然XMLHttpRequest对象遵循同源政策,但是script标签不一样,它可以通过 src 填上目标地址从而发出 GET 请求,实现跨域请求并拿到响应。这也就是 JSONP 的原理,接下来我们就来封装一个 JSONP:
const jsonp = ({ url, params, callbackName }) => {
const generateURL = () => {
let dataStr = '';
for(let key in params) {
dataStr += `${key}=${params[key]}&`;
}
dataStr += `callback=${callbackName}`;
return `${url}?${dataStr}`;
};
return new Promise((resolve, reject) => {
// 初始化回调函数名称
callbackName = callbackName || Math.random().toString.replace(',', '');
// 创建 script 元素并加入到当前文档中
let scriptEle = document.createElement('script');
scriptEle.src = generateURL();
document.body.appendChild(scriptEle);
// 绑定到 window 上,为了后面调用
window[callbackName] = (data) => {
resolve(data);
// script 执行完了,成为无用元素,需要清除
document.body.removeChild(scriptEle);
}
});
}
当然在服务端也会有响应的操作, 以 express 为例:
let express = require('express')
let app = express()
app.get('/', function(req, res) {
let { a, b, callback } = req.query
console.log(a); // 1
console.log(b); // 2
// 注意哦,返回给script标签,浏览器直接把这部分字符串执行
res.end(`${callback}('数据包')`);
})
app.listen(3000)
前端这样简单地调用一下就好了:
jsonp({
url: 'http://localhost:3000',
params: {
a: 1,
b: 2
}
}).then(data => {
// 拿到数据进行处理
console.log(data); // 数据包
})
和CORS相比,JSONP 最大的优势在于兼容性好,IE 低版本不能使用 CORS 但可以使用 JSONP,缺点也很明显,请求方法单一,只支持 GET 请求。
Nginx
Nginx 是一种高性能的反向代理服务器,可以用来轻松解决跨域问题。
what?反向代理?我给你看一张图你就懂了。
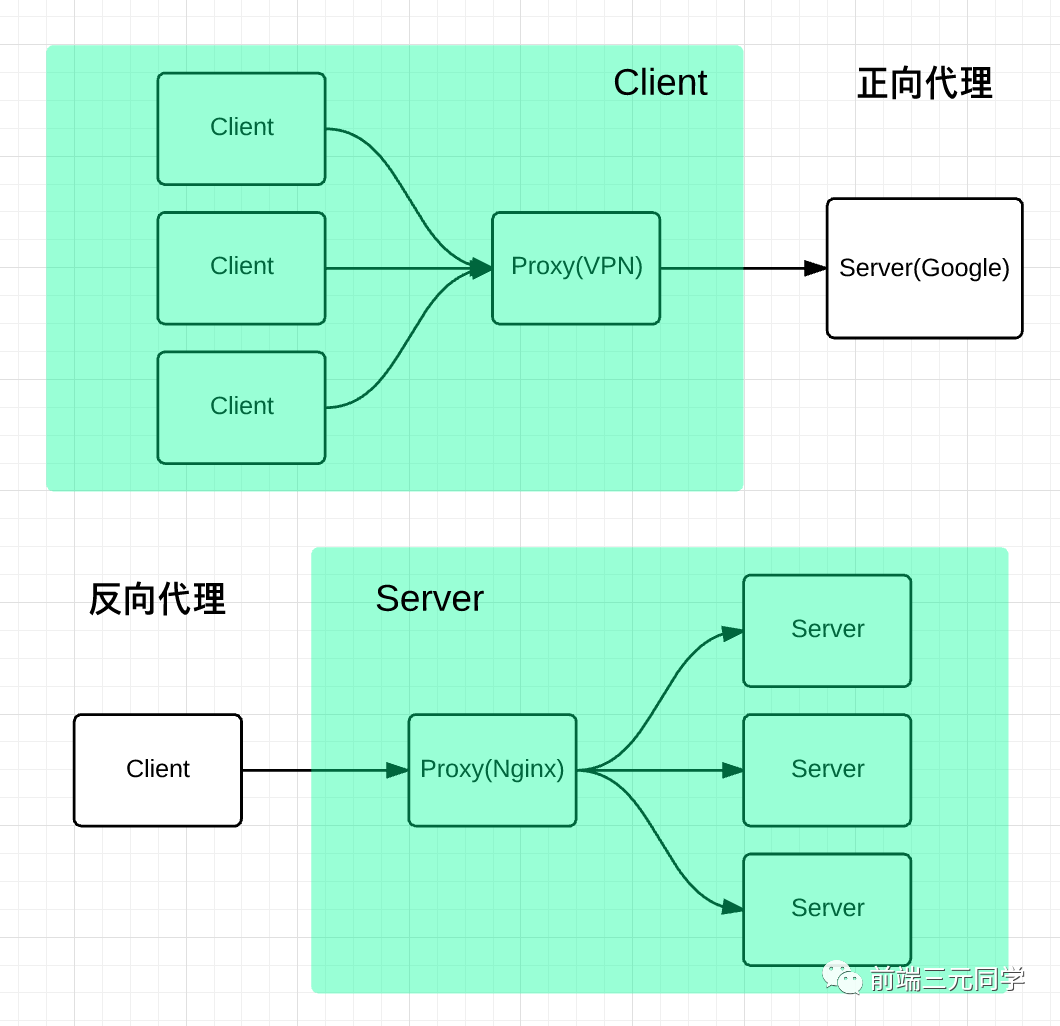
正向代理帮助客户端访问客户端自己访问不到的服务器,然后将结果返回给客户端。
反向代理拿到客户端的请求,将请求转发给其他的服务器,主要的场景是维持服务器集群的负载均衡,换句话说,反向代理帮其它的服务器拿到请求,然后选择一个合适的服务器,将请求转交给它。
因此,两者的区别就很明显了,正向代理服务器是帮客户端做事情,而反向代理服务器是帮其它的服务器做事情。
好了,那 Nginx 是如何来解决跨域的呢?
比如说现在客户端的域名为client.com,服务器的域名为server.com,客户端向服务器发送 Ajax 请求,当然会跨域了,那这个时候让 Nginx 登场了,通过下面这个配置:
server {
listen 80;
server_name client.com;
location /api {
proxy_pass server.com;
}
}
Nginx 相当于起了一个跳板机,这个跳板机的域名也是client.com,让客户端首先访问 client.com/api,这当然没有跨域,然后 Nginx 服务器作为反向代理,将请求转发给server.com,当响应返回时又将响应给到客户端,这就完成整个跨域请求的过程。
其实还有一些不太常用的方式,大家了解即可,比如postMessage,当然WebSocket也是一种方式,但是已经不属于 HTTP 的范畴,另外一些奇技淫巧就不建议大家去死记硬背了,一方面从来不用,名字都难得记住,另一方面临时背下来,面试官也不会对你印象加分,因为看得出来是背的。当然没有背并不代表减分,把跨域原理和前面三种主要的跨域方式理解清楚,经得起更深一步的推敲,反而会让别人觉得你是一个靠谱的人。
015: TLS1.2 握手的过程是怎样的?
之前谈到了 HTTP 是明文传输的协议,传输保文对外完全透明,非常不安全,那如何进一步保证安全性呢?
由此产生了 HTTPS,其实它并不是一个新的协议,而是在 HTTP 下面增加了一层 SSL/TLS 协议,简单的讲,HTTPS = HTTP + SSL/TLS。
那什么是 SSL/TLS 呢?
SSL 即安全套接层(Secure Sockets Layer),在 OSI 七层模型中处于会话层(第 5 层)。之前 SSL 出过三个大版本,当它发展到第三个大版本的时候才被标准化,成为 TLS(传输层安全,Transport Layer Security),并被当做 TLS1.0 的版本,准确地说,TLS1.0 = SSL3.1。
现在主流的版本是 TLS/1.2, 之前的 TLS1.0、TLS1.1 都被认为是不安全的,在不久的将来会被完全淘汰。因此我们接下来主要讨论的是 TLS1.2, 当然在 2018 年推出了更加优秀的 TLS1.3,大大优化了 TLS 握手过程,这个我们放在下一节再去说。
TLS 握手的过程比较复杂,写文章之前我查阅了大量的资料,发现对 TLS 初学者非常不友好,也有很多知识点说的含糊不清,可以说这个整理的过程是相当痛苦了。希望我下面的拆解能够帮你理解得更顺畅些吧 : )
传统 RSA 握手
先来说说传统的 TLS 握手,也是大家在网上经常看到的。我之前也写过这样的文章,(传统RSA版本)HTTPS为什么让数据传输更安全,其中也介绍到了对称加密和非对称加密的概念,建议大家去读一读,不再赘述。之所以称它为 RSA 版本,是因为它在加解密pre_random的时候采用的是 RSA 算法。
TLS 1.2 握手过程
现在我们来讲讲主流的 TLS 1.2 版本所采用的方式。
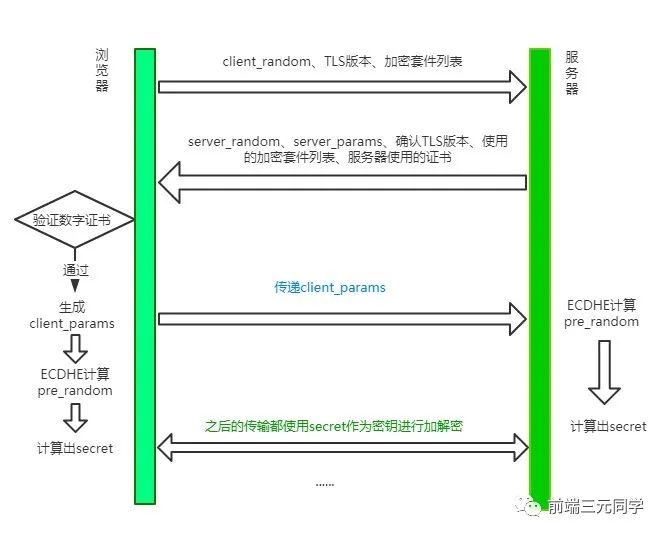
刚开始你可能会比较懵,先别着急,过一遍下面的流程再来看会豁然开朗。
step 1: Client Hello
首先,浏览器发送 client_random、TLS版本、加密套件列表。
client_random 是什么?用来最终 secret 的一个参数。
加密套件列表是什么?我举个例子,加密套件列表一般张这样:
TLS_ECDHE_WITH_AES_128_GCM_SHA256
意思是TLS握手过程中,使用ECDHE算法生成pre_random(这个数后面会介绍),128位的AES算法进行对称加密,在对称加密的过程中使用主流的GCM分组模式,因为对称加密中很重要的一个问题就是如何分组。最后一个是哈希摘要算法,采用SHA256算法。
其中值得解释一下的是这个哈希摘要算法,试想一个这样的场景,服务端现在给客户端发消息来了,客户端并不知道此时的消息到底是服务端发的,还是中间人伪造的消息呢?现在引入这个哈希摘要算法,将服务端的证书信息通过这个算法生成一个摘要(可以理解为比较短的字符串),用来标识这个服务端的身份,用私钥加密后把加密后的标识和自己的公钥传给客户端。客户端拿到这个公钥来解密,生成另外一份摘要。两个摘要进行对比,如果相同则能确认服务端的身份。这也就是所谓数字签名的原理。其中除了哈希算法,最重要的过程是私钥加密,公钥解密。
step 2: Server Hello
可以看到服务器一口气给客户端回复了非常多的内容。
server_random也是最后生成secret的一个参数, 同时确认 TLS 版本、需要使用的加密套件和自己的证书,这都不难理解。那剩下的server_params是干嘛的呢?
我们先埋个伏笔,现在你只需要知道,server_random到达了客户端。
step 3: Client 验证证书,生成secret
客户端验证服务端传来的证书和签名是否通过,如果验证通过,则传递client_params这个参数给服务器。
接着客户端通过ECDHE算法计算出pre_random,其中传入两个参数:server_params和client_params。现在你应该清楚这个两个参数的作用了吧,由于ECDHE基于椭圆曲线离散对数,这两个参数也称作椭圆曲线的公钥。
客户端现在拥有了client_random、server_random和pre_random,接下来将这三个数通过一个伪随机数函数来计算出最终的secret。
step4: Server 生成 secret
刚刚客户端不是传了client_params过来了吗?
现在服务端开始用ECDHE算法生成pre_random,接着用和客户端同样的伪随机数函数生成最后的secret。
注意事项
TLS的过程基本上讲完了,但还有两点需要注意。
第一、实际上 TLS 握手是一个双向认证的过程,从 step1 中可以看到,客户端有能力验证服务器的身份,那服务器能不能验证客户端的身份呢?
当然是可以的。具体来说,在 step3中,客户端传送client_params,实际上给服务器传一个验证消息,让服务器将相同的验证流程(哈希摘要 + 私钥加密 + 公钥解密)走一遍,确认客户端的身份。
第二、当客户端生成secret后,会给服务端发送一个收尾的消息,告诉服务器之后的都用对称加密,对称加密的算法就用第一次约定的。服务器生成完secret也会向客户端发送一个收尾的消息,告诉客户端以后就直接用对称加密来通信。
这个收尾的消息包括两部分,一部分是Change Cipher Spec,意味着后面加密传输了,另一个是Finished消息,这个消息是对之前所有发送的数据做的摘要,对摘要进行加密,让对方验证一下。
当双方都验证通过之后,握手才正式结束。后面的 HTTP 正式开始传输加密报文。
RSA 和 ECDHE 握手过程的区别
ECDHE 握手,也就是主流的 TLS1.2 握手中,使用
ECDHE实现pre_random的加密解密,没有用到 RSA。使用 ECDHE 还有一个特点,就是客户端发送完收尾消息后可以提前
抢跑,直接发送 HTTP 报文,节省了一个 RTT,不必等到收尾消息到达服务器,然后等服务器返回收尾消息给自己,直接开始发请求。这也叫TLS False Start。
016: TLS 1.3 做了哪些改进?
TLS 1.2 虽然存在了 10 多年,经历了无数的考验,但历史的车轮总是不断向前的,为了获得更强的安全、更优秀的性能,在2018年就推出了 TLS1.3,对于TLS1.2做了一系列的改进,主要分为这几个部分:强化安全、提高性能。
强化安全
在 TLS1.3 中废除了非常多的加密算法,最后只保留五个加密套件:
- TLS_AES_128_GCM_SHA256
- TLS_AES_256_GCM_SHA384
- TLS_CHACHA20_POLY1305_SHA256
- TLS_AES_128_GCM_SHA256
- TLS_AES_128_GCM_8_SHA256
可以看到,最后剩下的对称加密算法只有 AES 和 CHACHA20,之前主流的也会这两种。分组模式也只剩下 GCM 和 POLY1305, 哈希摘要算法只剩下了 SHA256 和 SHA384 了。
那你可能会问了, 之前RSA这么重要的非对称加密算法怎么不在了?
我觉得有两方面的原因:
第一、2015年发现了FREAK攻击,即已经有人发现了 RSA 的漏洞,能够进行破解了。
第二、一旦私钥泄露,那么中间人可以通过私钥计算出之前所有报文的secret,破解之前所有的密文。
为什么?回到 RSA 握手的过程中,客户端拿到服务器的证书后,提取出服务器的公钥,然后生成pre_random并用公钥加密传给服务器,服务器通过私钥解密,从而拿到真实的pre_random。当中间人拿到了服务器私钥,并且截获之前所有报文的时候,那么就能拿到pre_random、server_random和client_random并根据对应的随机数函数生成secret,也就是拿到了 TLS 最终的会话密钥,每一个历史报文都能通过这样的方式进行破解。
但ECDHE在每次握手时都会生成临时的密钥对,即使私钥被破解,之前的历史消息并不会收到影响。这种一次破解并不影响历史信息的性质也叫前向安全性。
RSA 算法不具备前向安全性,而 ECDHE 具备,因此在 TLS1.3 中彻底取代了RSA。
提升性能
握手改进
流程如下:
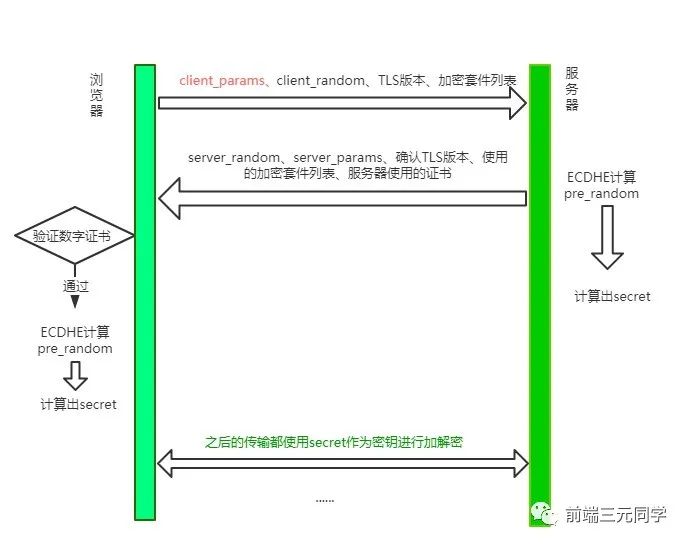
大体的方式和 TLS1.2 差不多,不过和 TLS 1.2 相比少了一个 RTT, 服务端不必等待对方验证证书之后才拿到client_params,而是直接在第一次握手的时候就能够拿到, 拿到之后立即计算secret,节省了之前不必要的等待时间。同时,这也意味着在第一次握手的时候客户端需要传送更多的信息,一口气给传完。
这种 TLS 1.3 握手方式也被叫做1-RTT握手。但其实这种1-RTT的握手方式还是有一些优化的空间的,接下来我们来一一介绍这些优化方式。
会话复用
会话复用有两种方式: Session ID和Session Ticket。
先说说最早出现的Seesion ID,具体做法是客户端和服务器首次连接后各自保存会话的 ID,并存储会话密钥,当再次连接时,客户端发送ID过来,服务器查找这个 ID 是否存在,如果找到了就直接复用之前的会话状态,会话密钥不用重新生成,直接用原来的那份。
但这种方式也存在一个弊端,就是当客户端数量庞大的时候,对服务端的存储压力非常大。
因而出现了第二种方式——Session Ticket。它的思路就是: 服务端的压力大,那就把压力分摊给客户端呗。具体来说,双方连接成功后,服务器加密会话信息,用Session Ticket消息发给客户端,让客户端保存下来。下次重连的时候,就把这个 Ticket 进行解密,验证它过没过期,如果没过期那就直接恢复之前的会话状态。
这种方式虽然减小了服务端的存储压力,但与带来了安全问题,即每次用一个固定的密钥来解密 Ticket 数据,一旦黑客拿到这个密钥,之前所有的历史记录也被破解了。因此为了尽量避免这样的问题,密钥需要定期进行更换。
总的来说,这些会话复用的技术在保证1-RTT的同时,也节省了生成会话密钥这些算法所消耗的时间,是一笔可观的性能提升。
PSK
刚刚说的都是1-RTT情况下的优化,那能不能优化到0-RTT呢?
答案是可以的。做法其实也很简单,在发送Session Ticket的同时带上应用数据,不用等到服务端确认,这种方式被称为Pre-Shared Key,即 PSK。
这种方式虽然方便,但也带来了安全问题。中间人截获PSK的数据,不断向服务器重复发,类似于 TCP 第一次握手携带数据,增加了服务器被攻击的风险。
总结
TLS1.3 在 TLS1.2 的基础上废除了大量的算法,提升了安全性。同时利用会话复用节省了重新生成密钥的时间,利用 PSK 做到了0-RTT连接。
017: HTTP/2 有哪些改进?
由于 HTTPS 在安全方面已经做的非常好了,HTTP 改进的关注点放在了性能方面。对于 HTTP/2 而言,它对于性能的提升主要在于两点:
- 头部压缩
- 多路复用
当然还有一些颠覆性的功能实现:
- 设置请求优先级
- 服务器推送
这些重大的提升本质上也是为了解决 HTTP 本身的问题而产生的。接下来我们来看看 HTTP/2 解决了哪些问题,以及解决方式具体是如何的。
头部压缩
在 HTTP/1.1 及之前的时代,请求体一般会有响应的压缩编码过程,通过Content-Encoding头部字段来指定,但你有没有想过头部字段本身的压缩呢?当请求字段非常复杂的时候,尤其对于 GET 请求,请求报文几乎全是请求头,这个时候还是存在非常大的优化空间的。HTTP/2 针对头部字段,也采用了对应的压缩算法——HPACK,对请求头进行压缩。
HPACK 算法是专门为 HTTP/2 服务的,它主要的亮点有两个:
- 首先是在服务器和客户端之间建立哈希表,将用到的字段存放在这张表中,那么在传输的时候对于之前出现过的值,只需要把索引(比如0,1,2,...)传给对方即可,对方拿到索引查表就行了。这种传索引的方式,可以说让请求头字段得到极大程度的精简和复用。
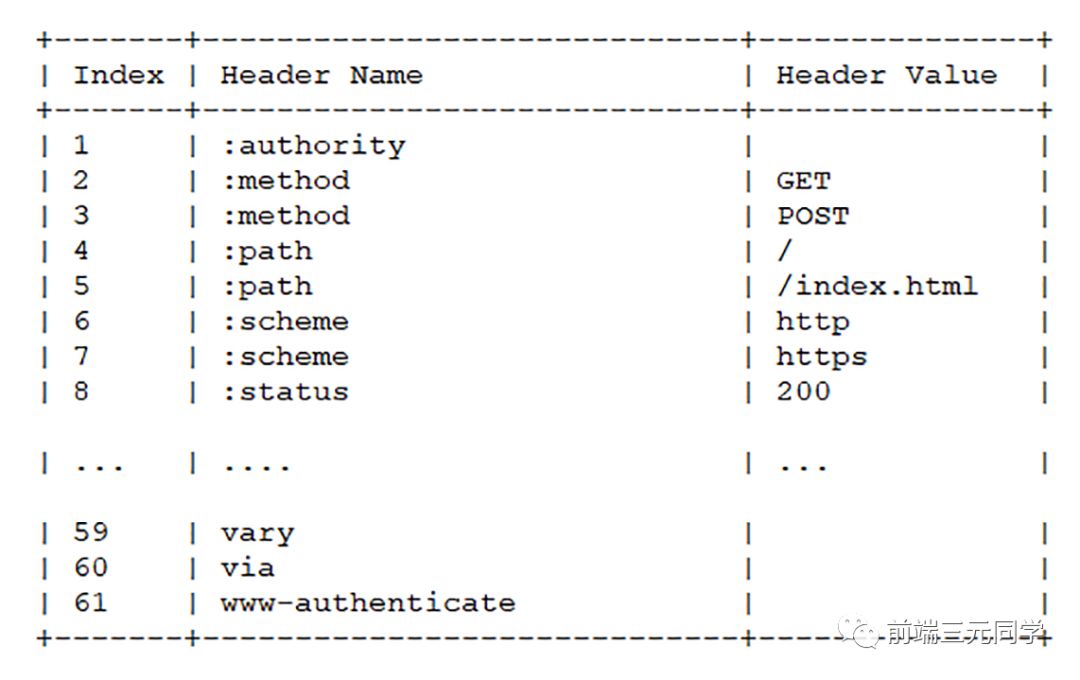
HTTP/2 当中废除了起始行的概念,将起始行中的请求方法、URI、状态码转换成了头字段,不过这些字段都有一个":"前缀,用来和其它请求头区分开。
- 其次是对于整数和字符串进行哈夫曼编码,哈夫曼编码的原理就是先将所有出现的字符建立一张索引表,然后让出现次数多的字符对应的索引尽可能短,传输的时候也是传输这样的索引序列,可以达到非常高的压缩率。
多路复用
HTTP 队头阻塞
我们之前讨论了 HTTP 队头阻塞的问题,其根本原因在于HTTP 基于请求-响应的模型,在同一个 TCP 长连接中,前面的请求没有得到响应,后面的请求就会被阻塞。
后面我们又讨论到用并发连接和域名分片的方式来解决这个问题,但这并没有真正从 HTTP 本身的层面解决问题,只是增加了 TCP 连接,分摊风险而已。而且这么做也有弊端,多条 TCP 连接会竞争有限的带宽,让真正优先级高的请求不能优先处理。
而 HTTP/2 便从 HTTP 协议本身解决了队头阻塞问题。注意,这里并不是指的TCP队头阻塞,而是HTTP队头阻塞,两者并不是一回事。TCP 的队头阻塞是在数据包层面,单位是数据包,前一个报文没有收到便不会将后面收到的报文上传给 HTTP,而HTTP 的队头阻塞是在 HTTP 请求-响应层面,前一个请求没处理完,后面的请求就要阻塞住。两者所在的层次不一样。
那么 HTTP/2 如何来解决所谓的队头阻塞呢?
二进制分帧
首先,HTTP/2 认为明文传输对机器而言太麻烦了,不方便计算机的解析,因为对于文本而言会有多义性的字符,比如回车换行到底是内容还是分隔符,在内部需要用到状态机去识别,效率比较低。于是 HTTP/2 干脆把报文全部换成二进制格式,全部传输01串,方便了机器的解析。
原来Headers + Body的报文格式如今被拆分成了一个个二进制的帧,用Headers帧存放头部字段,Data帧存放请求体数据。分帧之后,服务器看到的不再是一个个完整的 HTTP 请求报文,而是一堆乱序的二进制帧。这些二进制帧不存在先后关系,因此也就不会排队等待,也就没有了 HTTP 的队头阻塞问题。
通信双方都可以给对方发送二进制帧,这种二进制帧的双向传输的序列,也叫做流(Stream)。HTTP/2 用流来在一个 TCP 连接上来进行多个数据帧的通信,这就是多路复用的概念。
可能你会有一个疑问,既然是乱序首发,那最后如何来处理这些乱序的数据帧呢?
首先要声明的是,所谓的乱序,指的是不同 ID 的 Stream 是乱序的,但同一个 Stream ID 的帧一定是按顺序传输的。二进制帧到达后对方会将 Stream ID 相同的二进制帧组装成完整的请求报文和响应报文。当然,在二进制帧当中还有其他的一些字段,实现了优先级和流量控制等功能,我们放到下一节再来介绍。
服务器推送
另外值得一说的是 HTTP/2 的服务器推送(Server Push)。在 HTTP/2 当中,服务器已经不再是完全被动地接收请求,响应请求,它也能新建 stream 来给客户端发送消息,当 TCP 连接建立之后,比如浏览器请求一个 HTML 文件,服务器就可以在返回 HTML 的基础上,将 HTML 中引用到的其他资源文件一起返回给客户端,减少客户端的等待。
总结
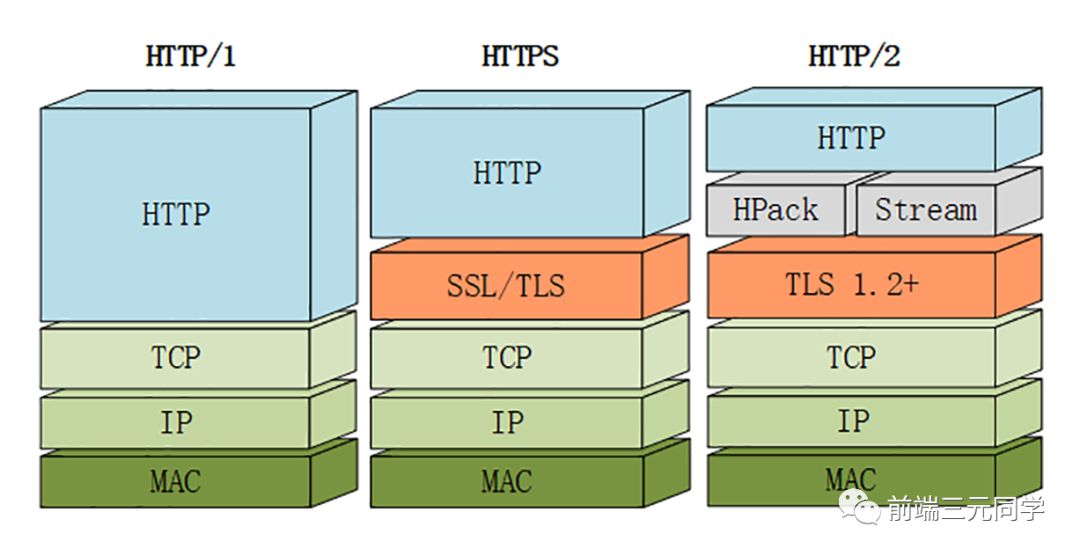
当然,HTTP/2 新增那么多的特性,是不是 HTTP 的语法要重新学呢?不需要,HTTP/2 完全兼容之前 HTTP 的语法和语义,如请求头、URI、状态码、头部字段都没有改变,完全不用担心。同时,在安全方面,HTTP 也支持 TLS,并且现在主流的浏览器都公开只支持加密的 HTTP/2, 因此你现在能看到的 HTTP/2 也基本上都是跑在 TLS 上面的了。最后放一张分层图给大家参考:
018: HTTP/2 中的二进制帧是如何设计的?
帧结构
HTTP/2 中传输的帧结构如下图所示:

每个帧分为帧头和帧体。先是三个字节的帧长度,这个长度表示的是帧体的长度。
然后是帧类型,大概可以分为数据帧和控制帧两种。数据帧用来存放 HTTP 报文,控制帧用来管理流的传输。
接下来的一个字节是帧标志,里面一共有 8 个标志位,常用的有 END_HEADERS表示头数据结束,END_STREAM表示单方向数据发送结束。
后 4 个字节是Stream ID, 也就是流标识符,有了它,接收方就能从乱序的二进制帧中选择出 ID 相同的帧,按顺序组装成请求/响应报文。
流的状态变化
从前面可以知道,在 HTTP/2 中,所谓的流,其实就是二进制帧的双向传输的序列。那么在 HTTP/2 请求和响应的过程中,流的状态是如何变化的呢?
HTTP/2 其实也是借鉴了 TCP 状态变化的思想,根据帧的标志位来实现具体的状态改变。这里我们以一个普通的请求-响应过程为例来说明:
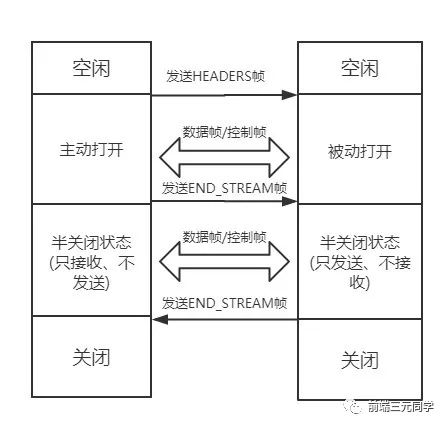
最开始两者都是空闲状态,当客户端发送Headers帧后,开始分配Stream ID, 此时客户端的流打开, 服务端接收之后服务端的流也打开,两端的流都打开之后,就可以互相传递数据帧和控制帧了。
当客户端要关闭时,向服务端发送END_STREAM帧,进入半关闭状态, 这个时候客户端只能接收数据,而不能发送数据。
服务端收到这个END_STREAM帧后也进入半关闭状态,不过此时服务端的情况是只能发送数据,而不能接收数据。随后服务端也向客户端发送END_STREAM帧,表示数据发送完毕,双方进入关闭状态。
如果下次要开启新的流,流 ID 需要自增,直到上限为止,到达上限后开一个新的 TCP 连接重头开始计数。由于流 ID 字段长度为 4 个字节,最高位又被保留,因此范围是 0 ~ 2的 31 次方,大约 21 亿个。
流的特性
刚刚谈到了流的状态变化过程,这里顺便就来总结一下流传输的特性:
- 并发性。一个 HTTP/2 连接上可以同时发多个帧,这一点和 HTTP/1 不同。这也是实现多路复用的基础。
- 自增性。流 ID 是不可重用的,而是会按顺序递增,达到上限之后又新开 TCP 连接从头开始。
- 双向性。客户端和服务端都可以创建流,互不干扰,双方都可以作为
发送方或者接收方。 - 可设置优先级。可以设置数据帧的优先级,让服务端先处理重要资源,优化用户体验。
以上就是对 HTTP/2 中二进制帧的介绍,希望对你有所启发
参考:
《web协议详解与抓包实战——陶辉》
《透视 HTTP 协议》——chrono
Chromium IPC 源码
前端开发者必备的Nginx知识 ——conardli
推荐阅读
我的公众号能带来什么价值?(文末有送书规则,一定要看)
每个前端工程师都应该了解的图片知识(长文建议收藏)
为什么现在面试总是面试造火箭?