用GPT-3开发一款应用,如何兼顾灵活和成本?

大数据文摘授权转载自数据实战派
作者:Ben Dickson
译者:张雨嘉
最近,OpenAI 宣布取消 GPT-3 接口的等待制,这意味着所有满足使用 OpenAI API 条件的开发人员都可以申请该应用,并快速将 GPT-3 集成到他们自己的应用程序中。
GPT-3 的测试版发布之后,开发人员已经在该语言模型的基础上构建了数百个应用程序。但想要构建完美的 GPT-3 产品,还面临着很多挑战。
本文旨在总结计利用 OpenAI GPT-3 的方法和思路,尤其同时兼顾操作的灵活性和成本效益。
模型和 token

OpenAI 提供了四个不同版本的 GPT-3:Ada,Babbage,Curie 和 Davinci。Ada 是最快、最便宜,但性能也最差的版本。Davinci 是最慢、最贵,但表现性能最好的。Babbage 和 Curie 则在两者之间。
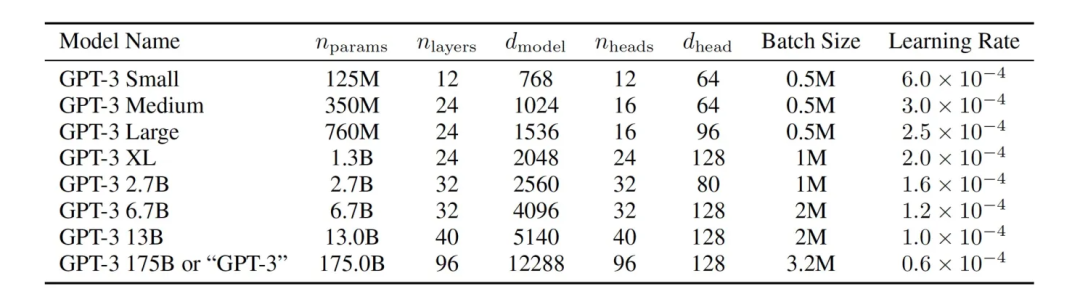
OpenAI 的网站并没有提供每个模型的结构细节,但在 GPT-3 的论文中介绍了该语言模型的不同版本。这些模型的主要区别在于参数量和层数,从最小的 12 层、1.25 亿个参数到最大的 96 层、1750 亿个参数。增加层数和参数量可以提高模型的学习能力,但同时也会增加处理的时间和成本。
OpenAI 根据 tokens 计算模型的价格。据 OpenAI 的说法,“对于普通英文文本,一个 token 对应文本中的 4 个字符,大约是 3/4 个单词(所以 100 个 tokens 约等于 75 个单词)”。
下面是使用 OpenAI Tokenizer 工具的一个示例:
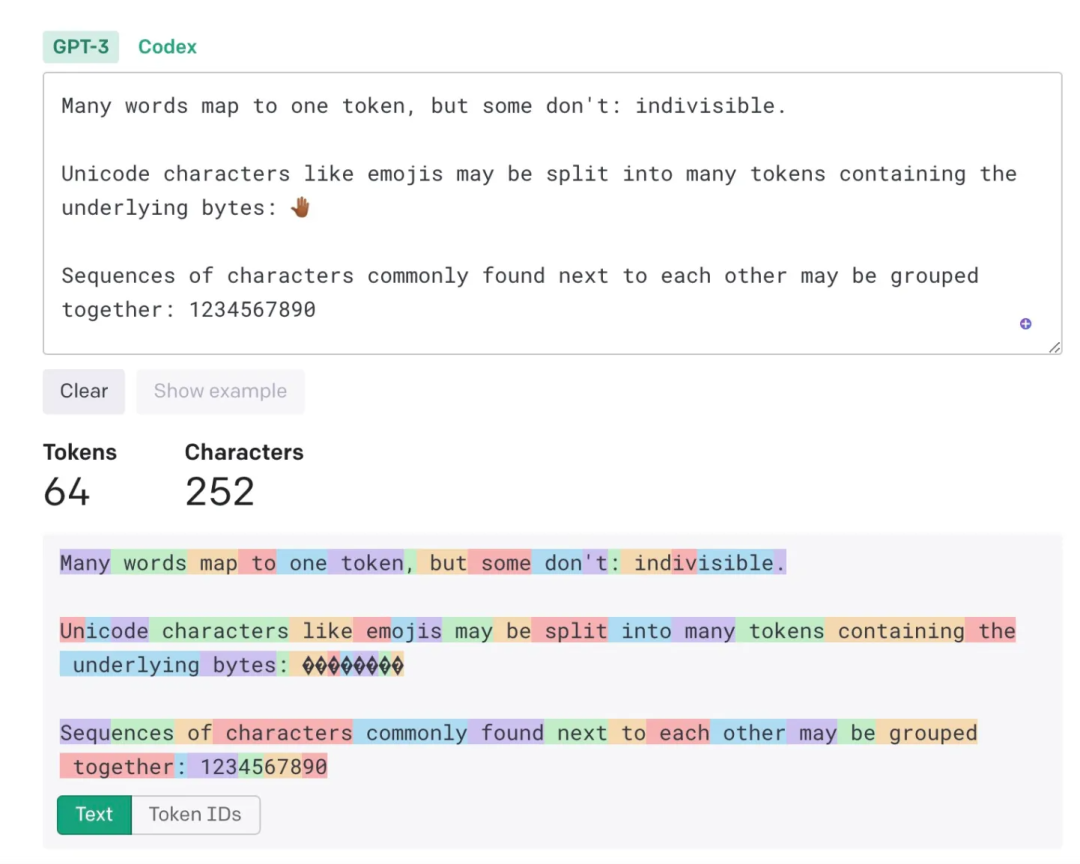
将文本转为 token
如果你使用比较专业的英语(减少术语,尽量使用音节少的简单单词),就会得到更高的 token-to-word 比率。下图中,除了“GPT-3”,其他每个单词都算作一个 token。
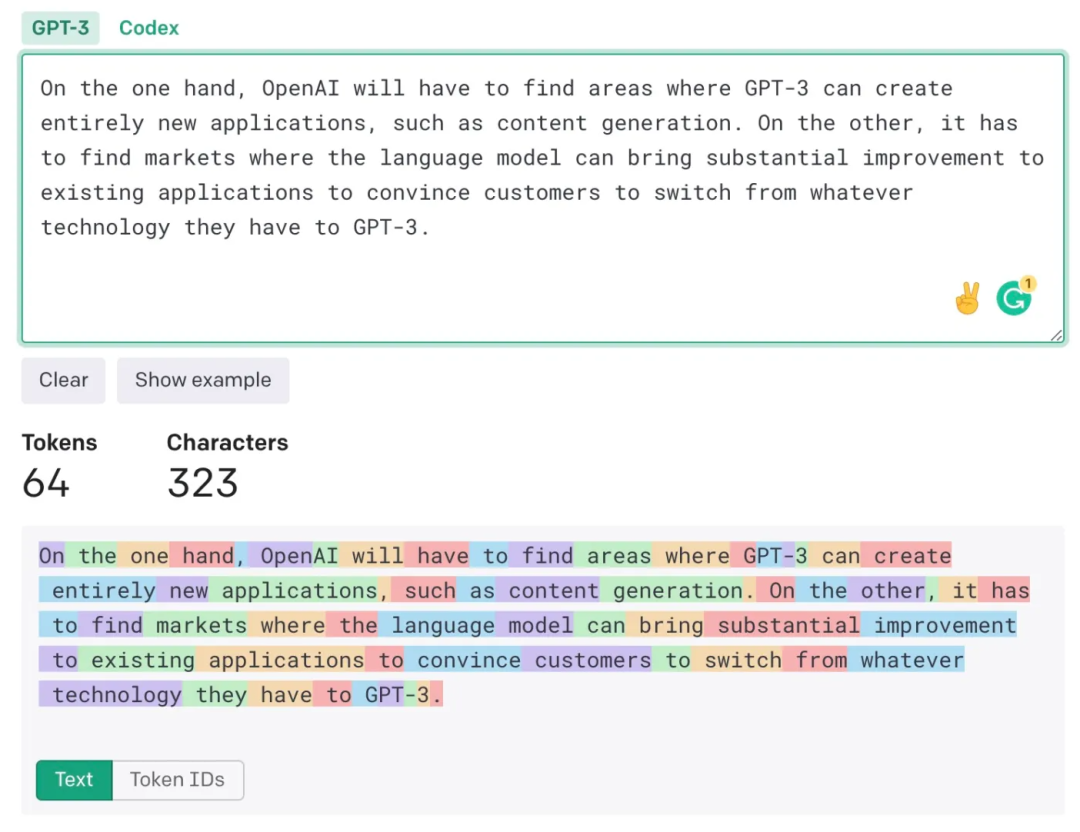
GPT-3 在少样本学习上也有比较好的能力。如果你不满意模型给出的结果,可以通过输入更长的正确示例对模型进行指导。通过对示例的实时训练,在不调整参数的情况下提高 GPT-3 的结果。
不过 OpenAI 的收费标准,是根据输入的 token 总数以及 GPT-3 输出的 token 数收取的。因此,少样本学习中较长的提示(promote)将增加 GPT-3 的使用成本。
你应该用哪种模型?
由于最便宜和最昂贵的 GPT-3 模型之间差了 75 倍,所以需要选择最适合你应用程序的模型版本。
OthersideAI 的联合创始人兼首席执行官 Matt Shumer 使用 GPT-3 开发了一个人工智能写作工具。使用 GPT-3 的 HyperWrite 可以完成文本生成、自动补全和重新措辞等功能。
Shumer 认为在选择不同的 GPT-3 模型时,应该首先考虑测试用例的复杂性。
他说:“如果是比较简单的二分类任务,我可能会选择Ada或Babbage模型。如果是非常复杂的任务,比如需要生成高质量和可靠的结果,那我就会使用Davinci。”
当不确定任务复杂度时,Shumer 建议先尝试使用最大的 Davinci 模型,然后逐渐转移到较小的模型上。
他说:“如果发现用 Davinci 可以完成任务,那就可以改动提升去尝试 Curie 模型。不过这可能需要添加更多的示例或者优化模型结构。如果用 Curie 依旧有效,那就转向使用 Babbage 或 Ada。”
还有一些应用程序,是多个模型混合而成的多步系统。
他说:“比如一个生成任务需要先进行分类,那我可能会用 Babbage 先进行分类,然后转用 Curie 或 Davinci 完成生成任务。使用一段时间后,你就会明白怎样为不同用例选择合适的模型。”

图 | OpenAI 的 Playground 支持使用不同的 GPT-3 版本
LitRPG Adventures 的作者和开发者 Paul Bellow,在 GPT-3 驱动的 RPG 内容生成器(RPG content generator)中使用了 Davinci。
Bellow 在 TechTalks 说:“我希望生成高质量的输出,以方便后续的微调。Davinci 虽然是最慢且最贵的模型,但是具有高质量的输出,这在当前这个发展阶段非常重要。所以我已经购买了模型,并获得了 10,000 多个生成结果用于未来的微调。”
Bellow 说:“如果你想知道其他模型是否对这个任务有效,可以先在 Playground 上运行一些测试用例,Playground 工具可以直接在不同的 GPT-3 模型上进行测试(不过使用 Playground 也需要向 OpenAI 付费)。”
“大多数情况下,我们可以从 Curie 模型中得到比较好的结果。但这完全取决于用例的复杂程度”,Bellow 说。
平衡成本与性能
在选择模型去构建应用程序时,必须权衡成本和价值。选择高性能的模型可以提供高质量的输出,但同时可能带来巨大的成本花费。
Shumer 说:“你应该建立一个围绕你产品的商业模型,来支持你使用的方法。如果你的目的是为用户提供高质量的输出,那么可以使用 Davinci 模型,将成本转嫁给用户。如果只是想要创造一款大规模的免费产品,你的用户也只需要一般的结果,那就可以使用较小的模型。所以模型的选择取决于你的产品目标。”
“OthersideAI 还开发了一个支持不同的用例的混合 GPT-3 模型。付费用户可以享受高性能 GPT-3 的强大功能,免费用户也可以使用较小的模型。”Shumer说。
Bellow 最初使用的就是 Davinci 模型,因为对于 LitRPG Adventures 来说质量是最重要的。虽然在 one-shot 或 two-shot 上使用 Davinci 模型会增加成本,但可以确保 GPT-3 提供高质量的输出。
Bellow 说:“现在的 OpenAI API Davinci 模型确实有点贵,但成本最终会呈现下降趋势。在允许的范围内通过微调 Curie 或更小的模型,可以提高模型的灵活性。意味着在保持高质量的同时,可以大大降低每代的成本。”
如今,Bellow 已经在保证利润率的前提下,使用 Davinci 开发了一种商业模型。
他说:“虽然 LitRPG Adventures 项目的目的并不是为了赚钱,但现在已经赚到足够多的钱去扩大规模了。”
对 GPT-3 进行微调
OpenAI 的科学家最初将 GPT-3 作为一种与任务无关的语言模型。根据测试结果显示,GPT-3 无需进一步微调,就可以与某些任务上最先进的模型抗衡。但是他们也认为微调是“未来研究的重要方向”。
在几个月前 GPT-3 测试版发布后,OpenAI 和微软用许多任务对模型进行了微调,包括数据库查询和源码生成任务。
与其他深度学习模型一样,微调对 GPT-3 也是有益的。OpenAI API 允许客户对 GPT-3 进行微调,来获得更高的回报。你可以通过 OpenAI 服务器上传自己构建的训练集,然后使用数据集生成微调的 GPT-3 模型。OpenAI 可以保存模型,并通过 API 提供给你。
很多基础模型无法处理的问题,都可以通过微调解决。
Shumer 说:“基础模型的性能很强,可用于多种任务。但是有些任务(例如多步生成)对于基础模型来说过于复杂,即使是 Davinci 模型也无法准确完成。在这种情况下,可以采取两种方法:1)创建将输出输入到下一个提示符的提示符通道,2)微调模型。我一般先试着创建提示符通道,如果不起作用,再进行微调。”
如果操作得当,微调还可以降低 GPT-3 的使用成本。如果 GPT-3 只在特定的应用中使用,那么经过微调的小模型可以拥有与大模型一样好的结果。微调过的模型还可以减少提示符的大小,从而进一步降低 token 的使用率。
Shumer 说:“当使用基础模型时的提示符太长,导致为用户提供服务的成本很高时,我会去使用微调。因为它可以降低总体运营成本。”
但微调并非屡试不爽,如果没有高质量的训练数据集,微调可能会出现问题。
Bellow 说:“要尽可能对数据集进行多次清理。因为错误输入与输出是现在提示符工程中的一大问题。”
但如果你能收集到足够多的高质量训练数据集,那微调可能带来奇迹。在使用 Davinci 模型进行 LitRPG 之后,Bellow 用 7 兆字节的 JSON 文件收集了 4000 多个样本的数据集,并进行了清理。初步的实验表明,这可以在保证性能没有变化的前提下,将模型由 Davinci 转成 Curie,降低 GPT-3 模型 90% 的查询成本。
另一个需要考虑的是微调 GPT-3 所需的时间,它随着模型和训练数据集的大小而延长。
Shumer 说:“用几百个示例微调小模型只需要五分钟。但在数千个示例上训练更大的模型可能需要五个多小时。”
Shumer 的实验结果说明,模型的大小与微调 GPT-3 所需的数据大小之间存在负相关。意味着较大的模型可以用较少的数据进行微调。
“在许多任务中可以通过增大基本模型的大小,来减少对微调数据量的需求。用 100 个示例微调后的 Curie 模型可能跟用 2000 个示例进行微调的 Babbage 模型有相似的结果。所以模型越大,就可以用越少的数据完成同样的事。”,Shumer 说。
GPT-3 的“替代版”
OpenAI 并没有将 GPT-3 发布成开源模型,所以受到了一些批评。但是其他开发商发布了 GPT-3 的替代方案,并向公众开放。EleutherAI 发布的 GPT-J 是比较通用的项目,与其他开源项目一样,GPT-J 需要应用开发人员去进行调试才能运行。而且不能在 Microsoft Azure 云上保存或微调模型,所以易用性和可扩展性较差。
但是如果有人员可以对模型进行设置,并且符合开发应用的要求,那么开源代码模型就是有用的。
Shumer 说:“GPT-J 与 GPT-3 不太一样,但如果你知道它的使用方法就会非常有用。与 Davinci 相比,GPT-J 更难获得复杂提示符,除非你拥有大量训练示例。一般情况下,无法得到超高质量的结果,不过可以通过增加训练时间获得一部分性能提升。与使用 Davinci 的成本相比,这些模型的最大优势是降低运行成本。”
Bellow 说:“据我猜测,它们的运行水平与 OpenAI 的 Curie 模型相当,因为他们并没有提供模型大小的详细信息。供应商之间的竞争有利于广大消费者,在未来让用户可以有更多的选择。”