
Vue3+TS+Node打造个人博客(后端架构)
点击上方卡片“前端司南”关注我您的关注意义重大 原创@前端司南
原创@前端司南
本项目代码已开源,具体见:
前端工程:vue3-ts-blog-frontend[1]
后端工程:express-blog-backend[2]
数据库初始化脚本:关注公众号前端司南,回复关键字“博客数据库脚本”,即可获取。
Express[3] 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架。目前已经更新到 5.x 版本。
我的博客后端其实开发得比较早,19年年底基本上已经完成了主体功能的开发,当时用的是 Express 4.x 版本。
在使用 Express 搭建后端服务时,主要关注的几个点是:
- 路由中间件和控制器
- SQL处理
- 响应返回体数据结构
- 错误码
- Web安全
- 环境变量/配置
路由基本上是按模块或功能去划分的。
首先是按模块去划分一级路由,各个模块的子功能相当于是用二级路由处理。
简单举个例子,/article路由开头的是文章模块,/article/add用于新增文章功能。
控制器的概念其实是从其他语言中借鉴而来的,Express 并没有明确说什么是控制器,但在我看来,路由中间件的处理模块/函数就是控制器的概念。
下面是本项目使用到的一些控制器。

const BaseController = require('../controllers/base');
const ValidatorController = require('../controllers/validator');
const UserController = require('../controllers/user');
const BannerController = require('../controllers/banner');
const ArticleController = require('../controllers/article');
const TagController = require('../controllers/tag');
const CategoryController = require('../controllers/category');
const CommentController = require('../controllers/comment');
const ReplyController = require('../controllers/reply');
module.exports = function(app) {
app.use(BaseController);
app.use('/validator', ValidatorController);
app.use('/user', UserController);
app.use('/banner', BannerController);
app.use('/article', ArticleController);
app.use('/tag', TagController);
app.use('/category', CategoryController);
app.use('/comment', CommentController);
app.use('/reply', ReplyController);
};
BaseController
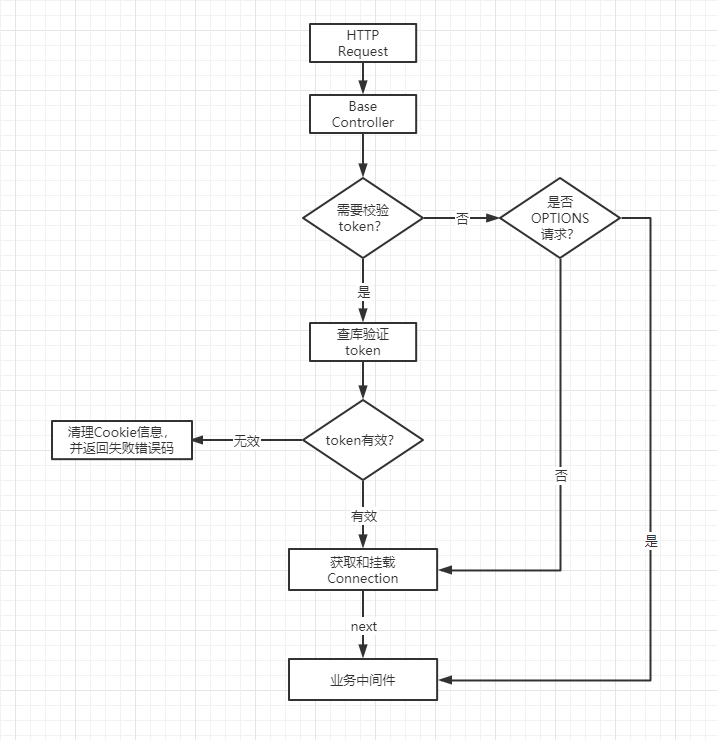
其中,BaseController是用作第一道关卡,对所有的请求做一个基本的校验和拦截。
其实主要是对一些敏感接口(比如后台维护类的)做一个权限校验。
权限控制这块,我设计得还是比较简单粗暴的,因为我在数据库表中目前只预留了一个用户Tusi,关联的角色也是唯一用到的admin。毕竟目前还没考虑开放用户注册这类的能力,有一个管理用户基本上也够用了。
所以我的设计是:只要在我登录成功后的有效期内,就有权限操作敏感接口,否则就无权操作!
BaseController大体工作流程如下:
BaseController的主体代码结构大概如下:
router.use(function(req, res, next) {
// authMap 维护了敏感接口列表
const authority = authMap.get(req.path);
// 首先检查是不是敏感接口
if (authority) {
// 需要检验身份的接口
if (req.cookies.token) {
// 取到 token 去做校验
dbUtils.getConnection(function (connection) {
req.connection = connection;
// 这里会直接查库验明身份
connection.query(indexSQL.GetCurrentUser, [req.cookies.token], function (error, results, fileds) {
// 身份校验通过,才继续,否则返回错误码
})
})
} else {
return res.send({
...errcode.AUTH.UNAUTHORIZED
});
}
} else {
// 不是敏感接口,不校验身份
if (req.method == 'OPTIONS') {
// OPTIONS 类型请求不能去连数据库,否则会导致数据库连接过多崩了
next();
} else {
// 从mysql连接池取得connection
dbUtils.getConnection(function (connection) {
req.connection = connection;
next();
}, function (err) {
return res.send({
...errcode.DB.CONNECT_EXCEPTION
});
})
}
}
}
如注释所述,BaseController主要是针对敏感接口做一个身份检查,防止系统数据被一些不怀好意的 HTTP 请求给黑了。
20220218更新
按照上面的逻辑实现功能并上线后,服务运行一段时间(可能是3~5天)后,能观察到服务请求会变成无法正常响应的状态。
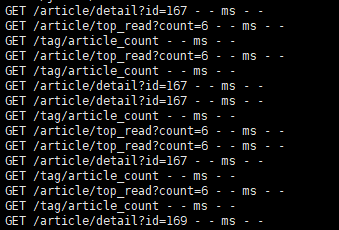
其实我能感觉到可能是mysql连接池未合理释放导致的。
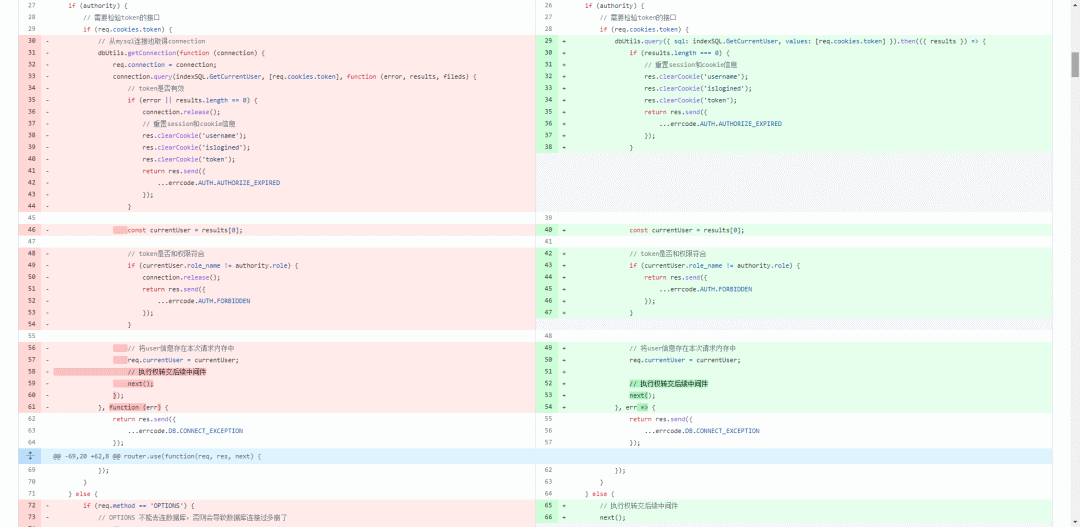
但是由于我一开始采取的方案是:在BaseController给req挂载connection,并在具体的业务控制器执行完sql查询语句后再自行释放connection,这个基本使用过程我在后面一节也说到了。
如果要完全改掉这种调用方式,代码改动还是挺大的,所以我一直拖着没改,发现问题了就通过 PM2 重启服务也能接着用。最近还是咬咬牙全部重构了,具体见refactor: 重构sql调用部分[4]。
业务Controller
前端会分模块,后端自然也会。业务模块会有很多,比如文章,分类,标签,等等。这些都可以分成不同的Controller处理。
业务Controller的大体结构如下,一个子路由就对应一个功能:
/**
* @param {Number} count 查询数量
* @description 根据传入的count获取阅读排行top N的文章
*/
router.get('/top_read', function (req, res, next) {
// 业务代码
}
/**
* @param {Number} pageNo 页码数
* @param {Number} pageSize 一页数量
* @description 分页查询文章
*/
router.get('/page', function (req, res, next) {
// 业务代码
}
/**
* @param {Number} id 当前文章的id
* @description 查询上一篇和下一篇文章的id
*/
router.get('/neighbors', function (req, res, next) {
// 业务代码
}
SQL 这块,我没有直接用 ORM 工具。因为我觉得自己的 SQL 基础并不是很好,还需要自己多写 SQL 语句练习一下,所以我只用了一个mysql的库。

安装mysql依赖:
npm install --save mysql
简单使用时,可以直接创建连接,然后执行 SQL 语句:
var mysql = require('mysql');
var connection = mysql.createConnection({
host : 'localhost',
user : 'me',
password : 'secret',
database : 'my_db'
});
connection.connect();
connection.query('SELECT 1 + 1 AS solution', function (error, results, fields) {
if (error) throw error;
console.log('The solution is: ', results[0].solution);
});
connection.end();
实际上,更推荐使用连接池,可以避免重复向 MySQL 申请连接,实现了连接的重用,在响应速度上也会更快!
var mysql = require('mysql');
var pool = mysql.createPool(...);
pool.getConnection(function(err, connection) {
if (err) throw err; // not connected!
// Use the connection
connection.query('SELECT something FROM sometable', function (error, results, fields) {
// When done with the connection, release it.
connection.release();
// Handle error after the release.
if (error) throw error;
// Don't use the connection here, it has been returned to the pool.
});
});
实际操作时,我是在BaseController中执行了pool.getConnection,然后把connection对象挂载到req对象上,后续的路由中间件就可以直接从req对象中取得connection,可以少嵌套一层回调,也避免了每处业务代码都写这部分重复的getConnection代码。
BaseController的关键代码:
// 从mysql连接池取得connection
dbService.getConnection(function (connection) {
req.connection = connection;
next();
}, function (err) {
return res.send({
...errcode.DB.CONNECT_EXCEPTION
});
})
业务处直接从req获取到connection对象:
router.get('/page', function (req, res, next) {
const connection = req.connection;
const pageNo = Number(req.query.pageNo || 1);
const pageSize = Number(req.query.pageSize || 10);
connection.query(indexSQL.GetPagedArticle, [(pageNo - 1) * pageSize, pageSize], function (error, results, fileds) {
connection.release();
// 其他业务代码
})
SQL 语句主要是以字符串的形式编写,通过?作为一个参数槽位,接收一些动态的值。
比如一个逻辑删除的语句,我们会这样写:
// 逻辑删除/恢复
UpdateArticleDeleted: 'UPDATE article SET deleted = ? WHERE id = ?',
第一个?是留给字段deleted的值,第二个?便是传具体的id值。
而参数传值是通过connection.query的第二个参数携带的。
注意,这个参数是一个数组,数组中的值会按照从左到右的顺序依次替换掉 SQL 字符串中的?,变成一个真实的可执行的 SQL 语句。
connection.query(indexSQL.UpdateArticleDeleted, [params.deleted, params.id], function (error, results, fileds) {})
connection.query执行回调后切记调用connection.release释放连接。
另外要注意的一个就是 MySQL 的事务处理。对事务而言,初步要关注的是这三个 API!具体的使用场景我在后面的具体应用会再提到,这里就不展开了!
// 开始事务,对应 MySQL begin 语句
connection.beginTransaction();
// 事务提交,对应 MySQL commit 语句
connection.commit();
// 事务回滚,对应 MySQL rollback 语句
connection.rollback();
20220218更新
为了保留在这个项目中我使用mysql思路的一个转变过程,前面的 mysql 调用过程,我还是按照最初的想法展开介绍的,关键的也就是这么几点。
- BaseController 统一获取 mysql pool 的 connection 对象,并挂载到 req 对象上,供后面的业务使用。
- 业务 Controller 与 mysql 交互时,只需要从 req 对象中取得 connection,通过 connection.query 去执行 sql 语句。
- 业务 Controller 执行完 sql 语句后,主动 release 释放掉 connection。
- 事务场景中,事务处理完毕后,统一 release 释放掉 connection,而不是每个 query 都自行释放 connection。
这样的设计,虽然省去了在具体业务 Controller 执行getConnection(少一层回调写法),但是在connection.release()的把控上还存在漏洞,一旦业务调用方忘记调用release(),就有可能造成服务不可用。而且有的业务不需要与 mysql 交互,也必须要记得 release(),虽然可以用一些配置字段去规避,也并不能从根本上解决问题!
所以我的修改方案是:
- 总体的原则是高内聚,低耦合。
- 封装 mysql 的查询过程,把 getConnection, query, release 等几个关键行为都放在封装的代码中控制,对外只暴露一些封装好的方法,这样就不用担心调用方忘记某些关键操作(比如
release())。 - 关键 API Promise 化,这样在一些复杂的异步过程中可以做到事半功倍,特别是涉及事务处理的时候!
核心代码见db.js[5]
响应返回体响应返回体的数据结构是需要前后端进行约定的,只有约定好规范,双方才能紧密有序地配合起来。通常来说,会涉及到错误码,信息,数据等字段。
其中错误码code,信息message两个字段应该是通用的。数据部分data则随业务的需要,可能会有多种情况,比如数组结构,对象结构,或者是普通数据类型。
{
code: "0",
message: "查询成功",
data: {
id: 1,
name: 'xxx'
}
}
错误码是后端规范中必不可少的部分。错误码的设计是为了快速定位问题,也为一些业务监控系统提供了分析和统计依据。
每个程序员会有自己的一些编码风格,在错误码这块,我是通过语义化的属性名去定位到错误码的。通常,一个错误码会配对一条错误信息,也就是下面的msg字段。
module.exports = {
DB: {
CONNECT_EXCEPTION: {
code: "-1",
msg: "数据库连接异常"
}
},
AUTH: {
UNAUTHORIZED: {
code: "000001",
msg: "对不起,您还未获得授权"
},
AUTHORIZE_EXPIRED: {
code: "000002",
msg: "授权已过期"
},
FORBIDDEN: {
code: "000003",
msg: "抱歉,您没有权限访问该内容"
}
},
}
错误码的设计还有一个好处,就是方便做映射。
什么意思呢?后端返回错误码-1,并且通过msg字段告诉前端错误信息是数据库连接异常。但是,前端到底要不要反馈用户这么直接粗暴的信息呢?我想,有时候是不需要的,而是通过一条委婉的提示来安抚一下用户情绪。
比如,

所以,有了错误码,前端就可以收放自如,在错误提示上有更多发挥的余地,而不是直白地把后端反馈的错误信息直接暴露给用户。
简单的一个映射可以是:
// ERR_MSG
{
"-1": "系统开了个小差,请稍后重试!",
}
那么message的展示逻辑就可以是:
message.error(ERR_MSG[res.code])
主要是考虑几个方面,XSS,CSRF,响应头。
XSS,指的是 Cross-Site-Scripting 跨站脚本攻击。出现 XSS 漏洞的主要场景是用户输入,比如评论,富文本等信息,如果不加以校验,就可能会被植入恶意代码,造成数据和财产损失!
针对 XSS 的校验不能光靠客户端,服务端也必须进行校验。我这里用的是xss@1.0.9。
npm install --save xss
xss默认会处理掉常见的 XSS 风险,使用起来也非常简单。比如,在新增评论的接口处,我们可以对参数这样处理:
const xss = require("xss");
router.post('/add', function (req, res, next) {
const params = Object.assign(req.body, {
create_time: new Date(),
});
// XSS防护
if (params.content) {
params.content = xss(params.content)
}
}
虽然我目前还没有用富文本承载评论内容,但是还是先预备一下,万一哪天想用富文本了呢!
至于 CSRF(跨站请求伪造)攻击,常见的漏洞来源就是基于 Cookie 的身份验证,因为 Cookie 会在发 HTTP 请求的时候自动带上,这样一来攻击者就有了可乘之机,通过脚本注入,或者一些引诱点击,让你不知不觉就上了套,发出了意料之外的请求。
不过,浏览器也是在不断完善 Cookie 安全这块,比如 Chrome 80 版本默认启用的 SameSite=Lax,也防范了很多 CSRF 的攻击场景。
为了安全起见,在 Set-Cookie 时,最好带上这些属性。
Set-Cookie: token=74afes7a8; HttpOnly; Secure; SameSite=Lax;
为了防止 CSRF 攻击,还可以采用 csrf-token 方式,或者采用 JWT 认证,共同点都是避开基于 Cookie 的身份/口令认证方式。
另外,设置一些必要的响应头对于 Web 安全也至关重要!
Express 推荐我们直接用上helmet。
Helmet 通过设置各种 HTTP 请求头,提升 Express 应用的安全性。它不是 Web 安全的银弹,但的确有所帮助!
安装helmet:
npm install --save helmet
使用起来也很简单,因为它就是一个中间件。
app.use(helmet());
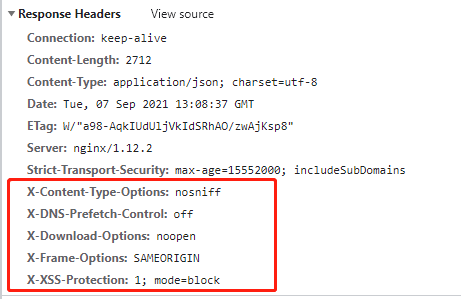 环境变量/配置
环境变量/配置由于后端配置文件中一般会出现一些私密性的配置,比如数据库配置,服务器配置,这些都不适合在开源项目中直接出现。所以,在本项目[6]中,我只给出了example示例,大家按照说明给出自己的配置文件即可。
- 通用配置:config/env.example.js
- 开发环境配置:config/dev.env.example.js
- 生产环境配置:config/prod.env.example.js
- PM2 deploy 配置:deploy.config.example.js
数据库、邮箱配置,以及其他的参数配置,建议是给开发环境和生产环境单独配置,避免本地开发时直接影响到生产环境。
所以,我们需要设置环境标识,并且根据环境标识来引用对应的参数配置。
环境标识我们都不陌生了,它就是process.env.NODE_ENV。由于项目中用到了pm2,所以我是通过pm2来配置NODE_ENV的。
env: {
NODE_ENV: "development",
PORT: 8002,
},
env_production: {
NODE_ENV: 'production',
PORT: 8002,
},
所以,我们只要根据NODE_ENV来判断开发环境或生产环境,然后加载对应的参数配置即可。逻辑非常简单!
// 配置入口文件,根据环境标识导出配置
const baseEnv = require("./env")
const devEnv = require("./dev.env")
const prodEnv = require("./prod.env")
module.exports = process.env.NODE_ENV === 'production' ? {
...baseEnv,
...prodEnv
} : {
...baseEnv,
...devEnv
}
本文是Vue3+TS+Node打造个人博客(后端架构篇),从一个不太专业的视角来切入后端,主要介绍了我在为博客系统设计后端时的一些主要思路,诸多细节不便展开,可以打开源码[7]了解。
有了这次全栈开发的经验,大大提高了我对前后端全链路的理解程度,这之后和后端开发们聊天也更有话题可聊了,有时候还能帮后端捋捋思路、一起排查下问题。总之非常奈斯!
但是,要把后端做完善还有很多的路要走,看看 Java 那么多中间件就知道了,道阻且长,行则将至,加油吧!
 系列文章
系列文章Vue3+TS+Node打造个人博客系列文章入口可点击下方链接,持续更新,欢迎阅读!点赞关注不迷路!😍
- Vue3+TS+Node打造个人博客(总览篇)[8]
参考
[1]vue3-ts-blog-frontend: https://github.com/cumt-robin/vue3-ts-blog-frontend
[2]express-blog-backend: https://github.com/cumt-robin/express-blog-backend
[3]Express: https://www.expressjs.com.cn/
[4]refactor: 重构sql调用部分: https://github.com/cumt-robin/express-blog-backend/commit/41628e98b2e1f2fee14289fdb8d13fe1bc0501e3
[5]db.js: https://github.com/cumt-robin/express-blog-backend/blob/main/utils/db.js
[6]本项目: https://github.com/cumt-robin/express-blog-backend
[7]源码: https://github.com/cumt-robin/express-blog-backend
[8]Vue3+TS+Node打造个人博客(总览篇): https://juejin.cn/post/7066966456638013477
END

如果觉得这篇文章还不错点击下面卡片关注我来个【分享、点赞、在看】三连支持一下吧

“分享、点赞、在看” 支持一波 