
Kubernetes 动态创建 Jenkins Agent 压力测试

前面我们利用 Kubernetes 提供的弹性,在 Kubernetes 上动态创建 Jenkins Slave,本文主要是对 Jenkins 进行大规模构建的压力测试。
1. 集群配置
1.1 Kubernetes 版本
这里使用的是 v1.16.7
kubectl version
Client Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.7", GitCommit:"be3d344ed06bff7a4fc60656200a93c74f31f9a4", GitTreeState:"clean", BuildDate:"2020-02-11T19:34:02Z", GoVersion:"go1.13.6", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.7", GitCommit:"be3d344ed06bff7a4fc60656200a93c74f31f9a4", GitTreeState:"clean", BuildDate:"2020-02-11T19:24:46Z", GoVersion:"go1.13.6", Compiler:"gc", Platform:"linux/amd64"}
1.2 节点数量
集群节点总数, 16 个
kubectl get node |grep "Ready" | wc -l
16
其中 master 节点 3 个,worker 节点 13 个。
kubectl get node |grep "master" | wc -l
3
kubectl get node |grep "worker" | wc -l
13
1.3 CI 节点
选取其中的 10 个节点用于 CI 构建,5 个 8 核 32 G ,5 个 16 核 32 G 。给这些节点打上 Label node-role.kubernetes.io/worker=ci ,用于构建 Pod 选取 Node 使用,避免影响集群上的其他负载。
kubectl top node -l node-role.kubernetes.io/worker=ci
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ci1 67m 0% 1268Mi 8%
ci10 100m 1% 1273Mi 4%
ci2 80m 1% 1258Mi 8%
ci3 90m 1% 1274Mi 8%
ci4 72m 0% 1286Mi 8%
ci5 80m 1% 1276Mi 8%
ci6 80m 1% 1268Mi 4%
ci7 89m 1% 1293Mi 4%
ci8 118m 1% 1285Mi 4%
ci9 81m 1% 1268Mi 4%
1.4 CI 资源配置
Pod 数量限制,足够支持 1100 Pod
按照官网文档描述,Kubernetes 最大支持 5000 个节点,15 W 个 Pod。
At v1.18, Kubernetes supports clusters with up to 5000 nodes. More specifically, we support configurations that meet all of the following criteria:
No more than 5000 nodes
No more than 150000 total pods
No more than 300000 total containers
No more than 100 pods per node
除了集群 Pod 总数有上限,这里有意义的是 kubelet 对 pod 最大数量的限制。
cat /var/lib/kubelet/config.yaml|grep max
maxOpenFiles: 1000000
maxPods: 110
10 个 CI 节点,总共能提供 1100 个 Pod,除去一些系统组件占用,已经足够。
Memory 和 CPU,足够支持 400 条流水线并发
每个 Pod 大约占用 500 MB Memory,CPU 是构建时瞬时值会比较高,但是维持时间较短,这里不用太多考虑。5 个 8 核 32 G ,5 个 16 核 32 G,总共有 120 核 320 G 内存,足够支撑 400 ( > 320 * 0.8 / 0.5 = 512) 条流水线同时构建。另外,由于 Jenkins Agent Pod 配置的是软亲和,当 CI 节点资源不足时,也可以调度到其他节点。
2. Jenkins 配置
2.1 Jenkins
即使流水线是在 Agent 上执行,但是大量的流水线同时运行,也会对 Jenkins 产生压力,这里给 Jenkins 的 limit 为 8 核 16 GB ,也就是最大允许消耗的资源量。
Jenkins 采用 Helm 部署,运行在 Kubernetes 上。下面是截取的部分 Deployment 信息:
kind: Deployment
apiVersion: apps/v1
metadata:
name: ks-jenkins
namespace: ks-jenkins
labels:
app.kubernetes.io/managed-by: Helm
chart: jenkins-0.19.0
spec:
replicas: 1
template:
metadata:
labels:
chart: jenkins-0.19.0
spec:
containers:
- name: ks-jenkins
image: 'jenkins/jenkins:2.176.2'
env:
- name: JAVA_TOOL_OPTIONS
value: >-
-Xms3g -Xmx6g -XX:MaxRAM=16g
-Dhudson.slaves.NodeProvisioner.initialDelay=20
-Dhudson.slaves.NodeProvisioner.MARGIN=50
-Dhudson.slaves.NodeProvisioner.MARGIN0=0.85
-Dhudson.model.LoadStatistics.clock=5000
-Dhudson.model.LoadStatistics.decay=0.2
-Dhudson.slaves.NodeProvisioner.recurrencePeriod=5000
-Dio.jenkins.plugins.casc.ConfigurationAsCode.initialDelay=10000
-verbose:gc -Xloggc:/var/jenkins_home/gc-%t.log
-XX:NumberOfGCLogFiles=2 -XX:+UseGCLogFileRotation
-XX:GCLogFileSize=100m -XX:+PrintGC -XX:+PrintGCDateStamps
-XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCCause
-XX:+PrintTenuringDistribution -XX:+PrintReferenceGC
-XX:+PrintAdaptiveSizePolicy -XX:+UseG1GC
-XX:+UseStringDeduplication -XX:+ParallelRefProcEnabled
-XX:+DisableExplicitGC -XX:+UnlockDiagnosticVMOptions
-XX:+UnlockExperimentalVMOptions
- name: kubernetes.connection.timeout
value: '60000'
- name: kubernetes.request.timeout
value: '60000'
schedulerName: default-scheduler
...
2.2 Jenkins Agent
使用 Kubernetes 提供的动态 Pod 作为 Jenkins Agent 用于构建流水线,具体配置可以参考顶部的文档链接。
Pod 中的 Maven 容器镜像 Dockerfile 主要内容如下:
centos:7
# java
RUN yum install -y java-1.8.0-openjdk \
java-1.8.0-openjdk-devel \
java-1.8.0-openjdk-devel.i686
...
为了减少对其他节点的影响,在 Jenkins 中配置了软亲和,将创建的动态 Pod 尽量调度到指定的 CI 节点。
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: node-role.kubernetes.io/worker
operator: In
values:
- ci
2.4 Jenkins 中 Kubernetes 插件配置
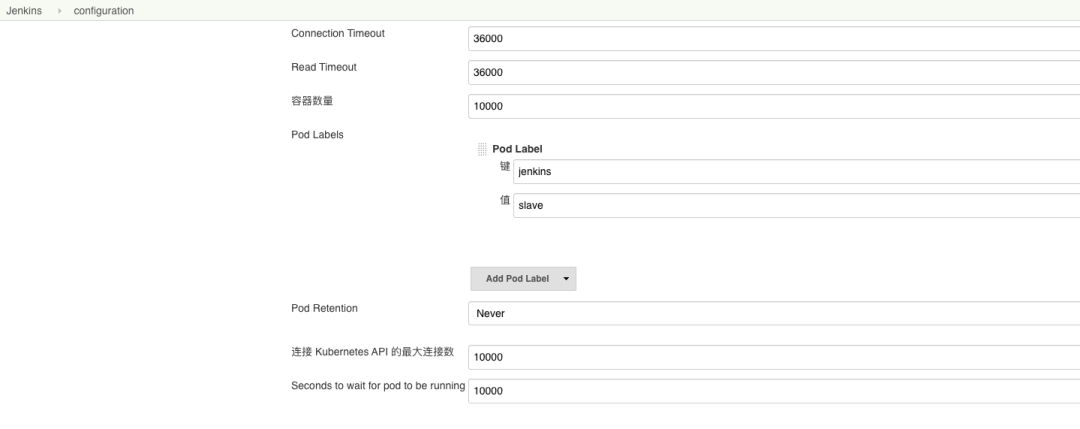
将容器数量和等待时间设置为一个较大值。
2.5 测试用的 Pipeline Demo
Demo 采用的是一个 Java 项目,克隆代码、执行单元测试、镜像构建。由于镜像内容都一样,这里就没有推送镜像,同时也减少了外部依赖。gitee.com 对拉取频率也有限制,建议使用自己搭建的代码仓库。
pipeline {
agent {
node {
label 'maven'
}
}
environment {
REGISTRY = 'docker.io'
DOCKERHUB_NAMESPACE = 'shaowenchen'
APP_NAME = 'devops-java-sample'
TAG_NAME = "SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER"
}
stages {
stage('checkout') {
steps {
container('maven') {
git branch: 'master', url: 'https://gitee.com/shaowenchen/devops-java-sample.git'
}
}
}
stage('unit test') {
steps {
container('maven') {
sh 'mvn clean -o -gs `pwd`/configuration/settings.xml test'
}
}
}
stage('build') {
steps {
container('maven') {
sh 'mvn -o -Dmaven.test.skip=true -gs `pwd`/configuration/settings.xml clean package'
sh 'docker build -f Dockerfile-online -t $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER .'
}
}
}
stage('sleep 0.5h') {
steps {
sh 'sleep 1800'
}
}
}
}
2.6 远程触发流水线脚本
# -*- coding: utf-8 -*-
# import time
import requests
jenkins_job_name = "new"
Jenkins_url = "http://jenkins.chenshaowen.com:8080"
jenkins_user = "admin"
jenkins_pwd = "password"
# buildWithParameters = True # if there are parameters
buildWithParameters = False
jenkins_params = {'token': 'mytoken',
'param1': 'valu1'}
def trigger():
try:
auth = (jenkins_user, jenkins_pwd)
crumb_data = requests.get(
"{0}/crumbIssuer/api/json".format(Jenkins_url),
auth=auth,
headers={
'content-type': 'application/json'})
if str(crumb_data.status_code) == "200":
if buildWithParameters:
data = requests.get(
"{0}/job/{1}/buildWithParameters".format(
Jenkins_url,
jenkins_job_name),
auth=auth,
params=jenkins_params,
headers={
'content-type': 'application/json',
'Jenkins-Crumb': crumb_data.json()['crumb']})
else:
data = requests.get(
"{0}/job/{1}/build".format(
Jenkins_url,
jenkins_job_name),
auth=auth,
params=jenkins_params,
headers={
'content-type': 'application/json',
'Jenkins-Crumb': crumb_data.json()['crumb']})
print(data.status_code)
if str(data.status_code) == "201":
print("Jenkins job is triggered")
else:
print("Failed to trigger the Jenkins job")
else:
print("Couldn't fetch Jenkins-Crumb")
raise
except Exception as e:
print("Failed triggering the Jenkins job")
print("Error: " + str(e))
if __name__ == "__main__":
for i in range(400):
# time.sleep(1)
print("Trigger-" + str(i))
trigger()
3. 测试策略
为了更好的测试 Jenkins 在 Kubernetes 上执行流水线的性能,在上面的配置中,我提供了足够 400 条流水线并发执行的资源。
由于首次运行流水线时,需要拉取镜像、对依赖包进行缓存。在执行测试之前,执行 20 次流水线对节点进行预热。
主要进行五组测试,分别为 50、100、200、400、800 条流水线并发。
观察的指标
触发流水线成功率 Jenkins UI 能否正常打开 Jenkins 创建 Pod 的速度 流水线执行成功率 失败的原因
4. 测试结果
| 流水线并发数量 | 触发成功率 | UI 能否正常打开 | 全部 Pod 创建成功耗时 | 流水线执行成功率 | 失败的原因 |
|---|---|---|---|---|---|
| 50 | 50/50 | 可以 | 12分钟 | 50/50 | - |
| 100 | 100/100 | 可以 | 7分钟 | 100/100 | - |
| 200 | 200/200 | 4 秒加载 | 7分钟 | 178/200 | Gitee 限制了拉取频率 |
| 400 | 400/400 | 11 秒加载 | 21分钟 | 348/400 | Gitee 限制了拉取频率 |
| 800 | 778/800 | 17 秒加载 | 18分钟 | 446/800 | 触发失败、流水线堆积无法调度 |
下面是具体的监控数据和分析
50 并发:正常执行,应该是预热不够充分,后半段速度变慢,创建时间较长。
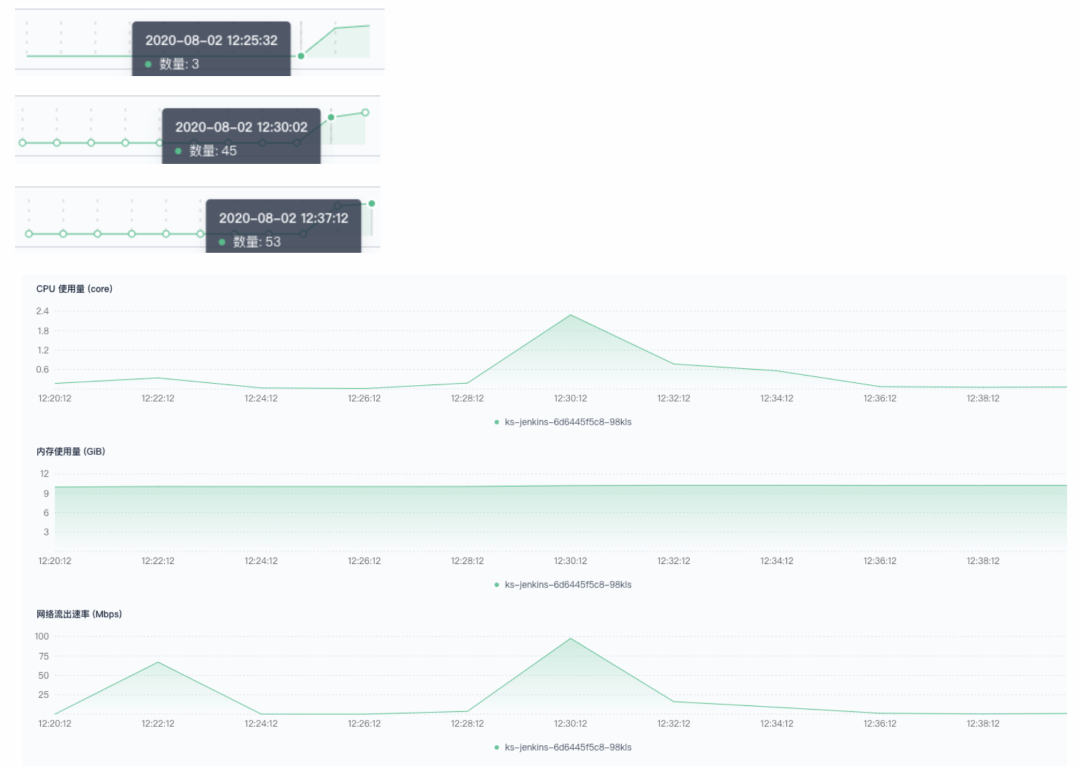
100 并发:正常执行,创建 Pod 速度很快,3~4 秒一个
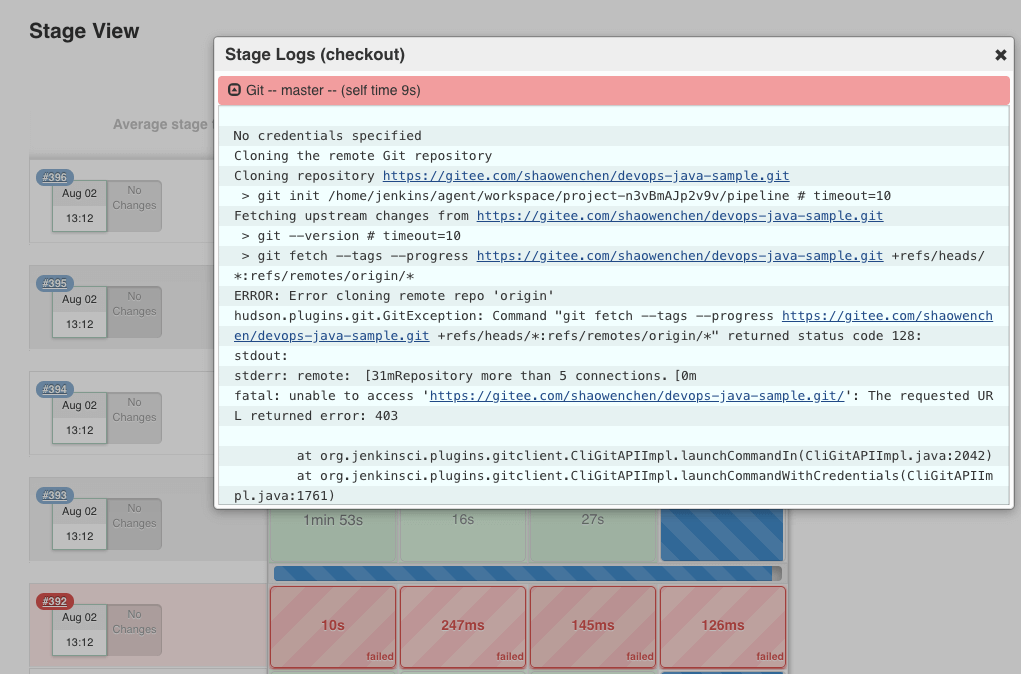
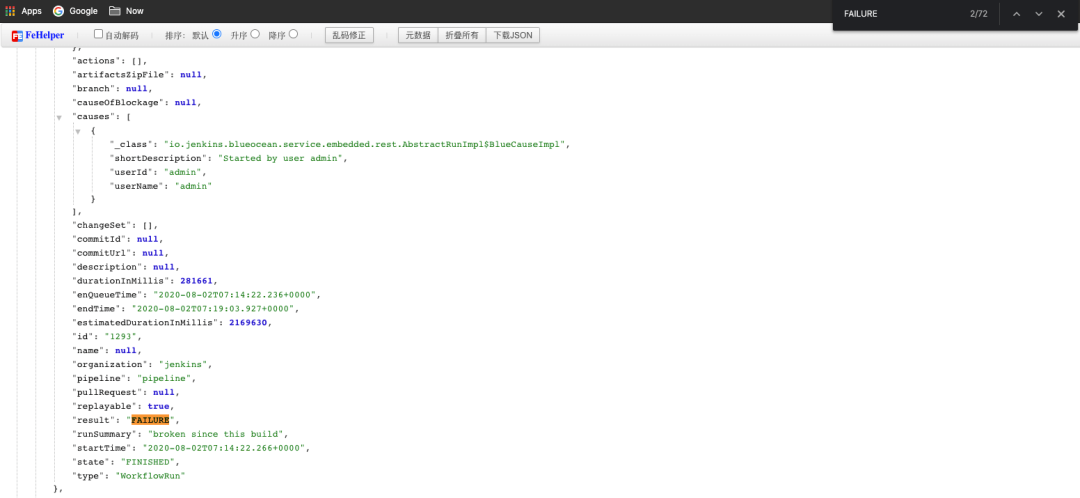
200 并发:触发正常,执行时部分流水线报错。这里的错误,主要是拉取 git 服务器代码受到了限制。错误提示如下:
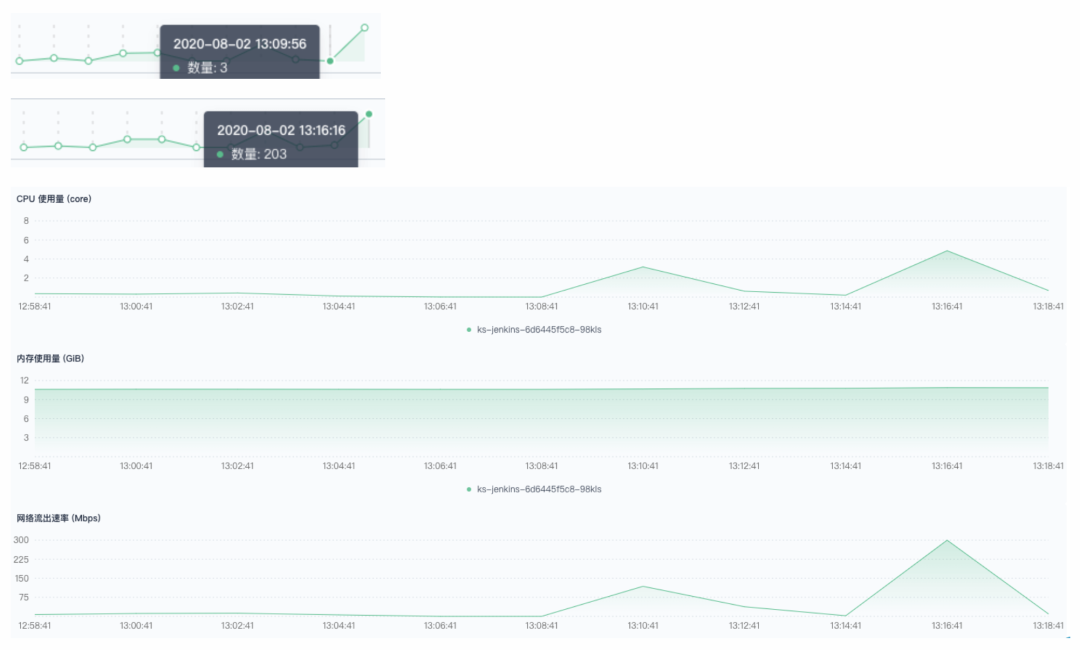
400 并发:有极少量调度到非 CI 节点,同样有大量拉取 git 服务器代码提示错误。
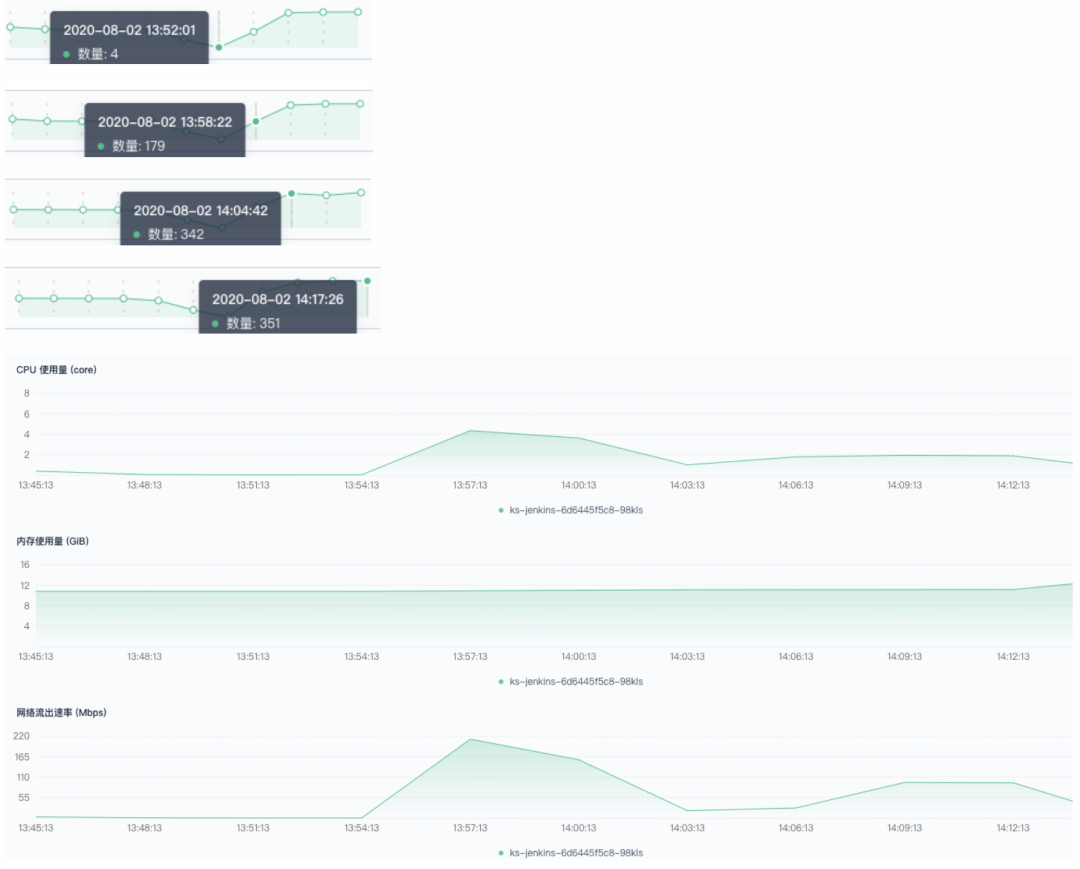
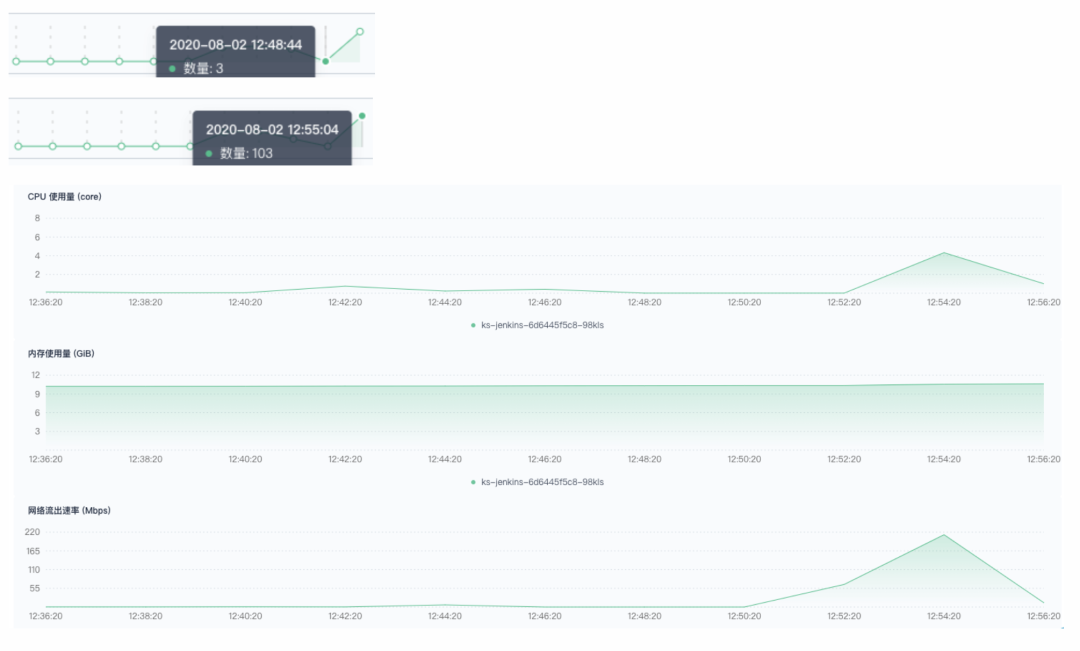
800 并发:460、461、551、552、759-776 触发失败。有少量调度到非 CI 节点,大量流水线堆积在 Build Queue ,这些流水线长时间不被调度,尝试重启 Jenkins 依然无法执行。
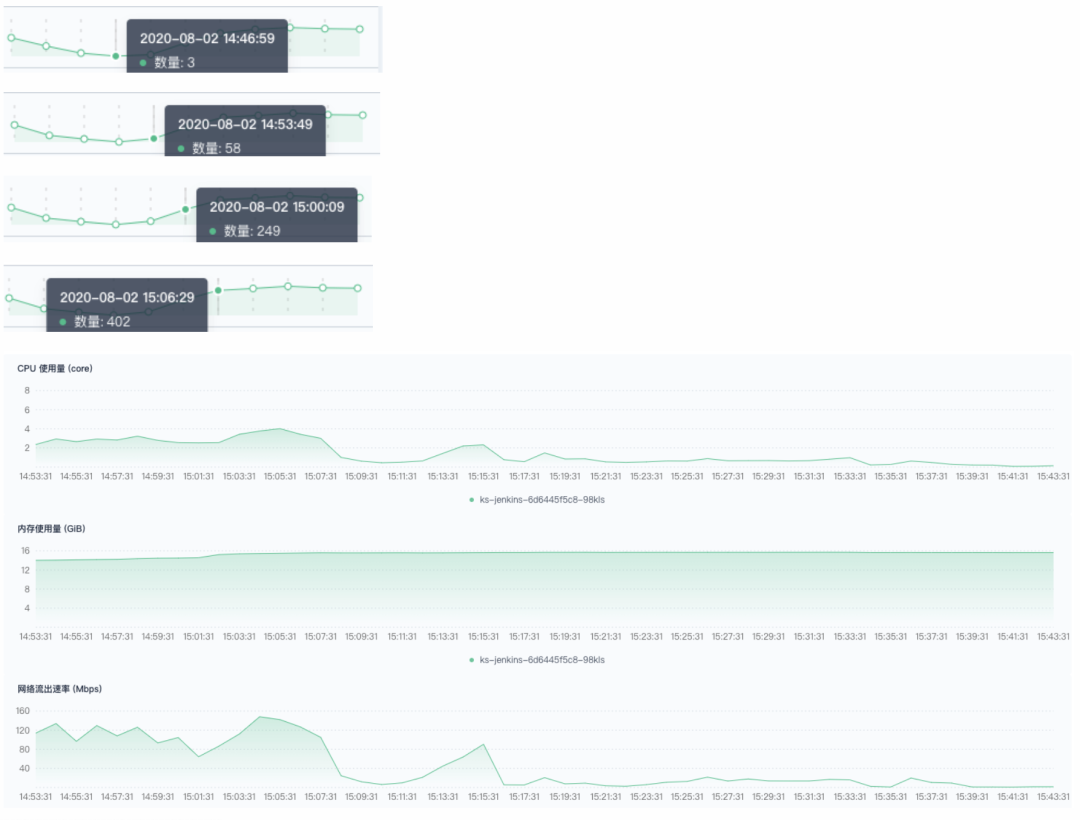
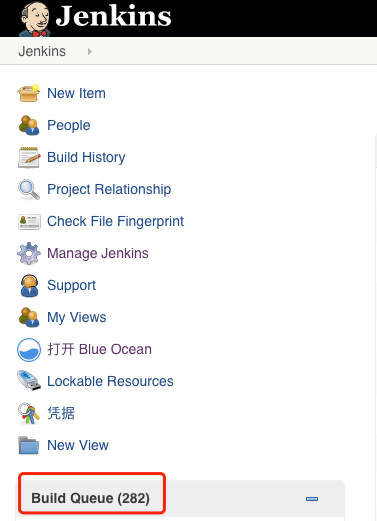
800 条流水线并发,超过了集群的负载极限。Jenkins 使用的内存达到了极限,能连接管理的 jnlp 数量也达到了极限。下面是相关的提示报错:
INFO: Server reports protocol JNLP-connect not supported, skipping
Aug 02, 2020 7:20:33 AM hudson.remoting.jnlp.Main$CuiListener error
SEVERE: The server rejected the connection: None of the protocols were accepted
java.lang.Exception: The server rejected the connection: None of the protocols were accepted
at hudson.remoting.Engine.onConnectionRejected(Engine.java:675)
at hudson.remoting.Engine.innerRun(Engine.java:639)
at hudson.remoting.Engine.run(Engine.java:474)
-XX:MaxRAM=16g 的配置在 400 并发时,明显吃力,到了 800 并发时,已经不够。之后,我又将最大内存使用设置为 32 g 进行测试,触发成功率有所改善,依然达不到 100% ;Pod 创建速度变快,集群资源充足的情况下,依然有部分堵在 Build Queue 中无法调度。
后来,我找了一个 202 个节点的集群进行测试,Jenkins 内存限制设置很大。通过接口不停地发送触发请求,Pod 数量最高峰在 517(=520-3),Pod 中的 jnlp 与 Jenkins 连接出现问题。同时,也伴随着大量触发和构建错误。下图是,关于 Pod 数量监控:

5. 测试总结和建议
从原理上讲 Jenkins 的 Kubernetes 插件实现的功能是调用 Kubernetes 的接口,创建 Pod 用于构建。创建的 Pod 中包含 jnlp 和真正构建环境的容器。
在高并发、高负载的场景下,瓶颈会出现在如下方面:
Jenkins 提供的 API Jenkins 的调度算法 Jenkins 调用的 Kubernetes API Kubernetes 调度创建 Pod 的速度 Pod 运行时的资源消耗,CPU、Mem、IO 等 Jenkins 的 Mem 和 CPU 限制
这次测试不算特别完善,有如下问题:
预热不够充分。测试 50 并发的数据有明显问题,创建速度比 100 并发还慢,说明有些节点没有相关的镜像或缓存。 Jenkins 内存不够充足。在 400 并发时,Jenkins 的内存使用已经接近 limit 限制,页面打开缓慢。
配置建议:
限制 Jenkins 同时连接 Pod 的数量,配置足够的情况下,200 并发是没有问题的,400 并发是可以争取的。Jenkins 需要与每一个 Pod 中的 jnlp 通信,控制并发数量能有效减轻 Jenkins 的负担,避免触发失败的发生。 使用专用的 CI 节点。让流水线的 Pod 在节点之间随意漂移,充分享受 Kubernetes 提供的弹性固然很好,但是大量并发的流水线会挤走节点上的负载,导致其他应用不稳定。 构建的 Pod 需要设置合适的 request 。与创建应用负载类似,过小的 request 会导致调度成功,但是 Pod 起不来的问题。大量流水线并发时,过小的 request 可能会直接压垮节点。 充足的 Jenkins 内存,16 G 基本能保证系统稳定,CPU 4C 及以上即可。Java 应用占用内存比较多。分配充足的内存给 Jenkins,可以提高触发成功率,提高 Pod 的创建效率,同时 Jenkins 也更稳定,不容易出现 Jenkins 页面打不开的情况。 绑定一个专门的节点用来运行 Jenkins。当给 Jenkins 设置了较大的内存限制时,随着并发数量上升,内存使用逐渐增加,虽然 limit 很大,但是节点内存可能不够,这样可能会导致 Jenkins 被调度到其他节点。 使用单实例 Jenkins 。Jenkins 使用磁盘文件存储数据,多实例会让 Jenkins 紊乱。提示错误如下:
Error
Jenkins detected that you appear to be running more than one instance of Jenkins that share the same home directory '/var/jenkins_home'. This greatly confuses Jenkins and you will likely experience strange behaviors, so please correct the situation.
This Jenkins: 449134911 contextPath="" at 6@ks-jenkins-68b8949bb-mgmjc
Other Jenkins: 1869668338 contextPath="" at 6@ks-jenkins-68b8949bb-kg49k
“原文链接:https://www.chenshaowen.com/blog/the-stress-test-about-kubernetes-dynamically-creates-jenkins-agent.html
”
 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习