
NoSQL | MongoDB入门实战教程(2)

上一篇我们了解了MongoDB的基本概念与单节点环境搭建,本篇我们来学习如何搭建一个高可用的复制集集群。
MongoDB复制集的主要意义在于实现服务的高可用,它是MongoDB的一个原生的高可用设计,不需我们额外引入一些组件来实现,因此实现起来相当便利。
主要功能
一是数据写入时将数据迅速地复制到另一个独立的节点上;
二是在接受写入的节点发生故障时自动选举出一个新的替代节点;
附加功能
数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的度延迟;
读写分离:不同类型的压力分别在不同的节点上执行;
异地容灾:在数据中心故障时快速切换到异地;
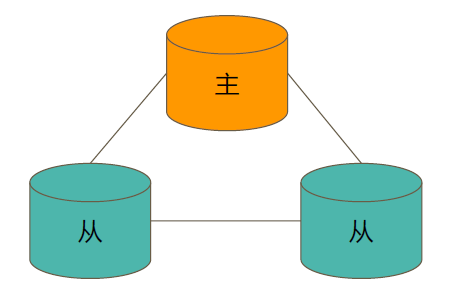
典型结构
一个典型的MongoDB复制集由3个以上具有投票权的节点组成:
(1)一个主节点(Primary),接受写入操作和选举时投票;
(2)两个(或多个)从节点(Secondary),复制主节点上的新数据和选举时投票;
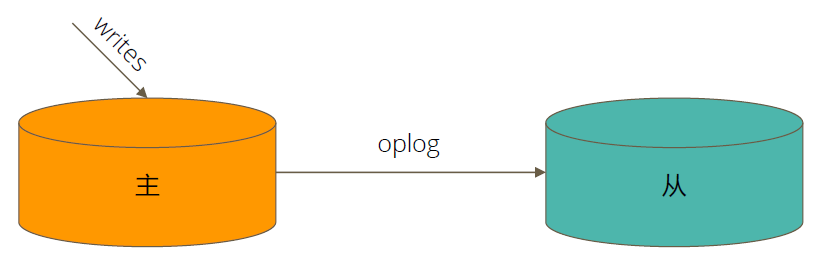
如何复制
当一个Mongo的修改操作(CRUD)成功,在主节点时它对数据的操作会被记录下来,这些记录被称为oplog,并传递给从节点。从节点通过不断获取新进入主节点的oplog,并在自己的数据上进行回放,以此保持和主节点的数据一致。
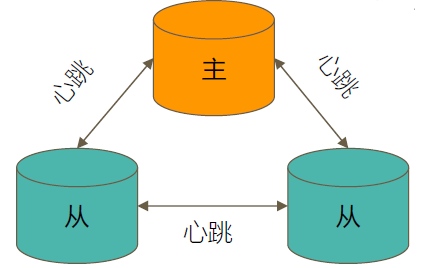
如何选举
具有投票权的节点之间两两互相发送心跳,当5次心跳未收到时则会判断节点为失联。如果失联的是主节点,从节点会发起选举,选出新的主节点。如果失联的是从节点,不会产生新的选举。
整个选举过程基于Raft一致性算法实现,选举成功的必要条件是大多数投票节点存活(这也是为啥大多数需要选举的中间件集群要保持奇数个节点的原因),整个复制集中可以<=50个,但具有投票权的节点<=7个。
准备VMware Workstation
跟上一篇一样,这次我们仍然会通过VMware Workstation启动几个虚拟机来完成搭建实践。
准备三台CentOS 7.x虚拟机
这里模拟的是三个Mongo节点的主从复制集,因此分别命名为mongo-master、mongo-slave1、mongo-slave2。
为了较好的模拟,在三个虚拟机中分别配置一下hosts文件:
vi /etc/hosts在hosts文件中加入以下内容(IP地址为你配置的虚拟机IP):
192.168.58.100 mongo-master192.168.58.101 mongo-slave1192.168.58.102 mongo-slave2
可以验证一下能否通过主机名互相ping通。
下载Mongo Server到三台虚拟机
下载地址:https://www.mongodb.com/try/download/community
目前Server社区版最新版本为4.4.5:
这里,我们复制到的目录假设为:/usr/local/mongodb/tgz
复制完成后,分别进行解压压缩包,然后将其重命名:
tar -zvxf mongodb-linux-x86_64-rhel70-4.4.5.tgzmv ./mongodb-linux-x86_64-rhel70-4.4.5 /usr/local/mongodb
准备三个Mongo节点的目录和文件
进入目录:cd /usr/local/mongodb
创建db目录:mkdir /usr/local/mongodb/data/db
创建日志目录:mkdir /usr/local/mongodb/logs
创建日志文件:touch /usr/local/mongodb/logs/mongodb.log
准备三个Mongo节点的配置文件
进入目录:cd /usr/local/mongodb
创建mongo配置文件:vi mongodb.conf
复制以下内容进入mongodb.conf:
systemLog:destination: filepath: /usr/local/mongodb/logs/mongodb.log # log pathlogAppend: truestorage:dbPath: /usr/local/mongodb/data/db # data directorynet:bindIp: 0.0.0.0port: 27017 # portreplication:replSetName: localrsprocessManagement:: true
添加三个Mongo节点的环境变量
修改profile文件:
cat /etc/profile<<"EOF">export PATH=$PATH:/usr/local/mongodb/bin>EOF
刷新profile文件:
source /etc/profile修改.bashrc文件:
cat >>/root/.bashrc<<"EOF"export PATH="$PATH:/usr/local/mongodb/bin"EOF
这时可以在任何目录下输入mongo命令就可以进入mongo了。
添加三个Mongo节点的开机启动
进入system目录:cd /lib/systemd/system
执行以下命令:
cat mongodb.service<<"EOF"在>提示符下复制以下内容:
[Unit]Description=mongodbAfter=network.target remote-fs.target nss-lookup.target[Service]Type=forkingExecStart=/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.confExecReload=/bin/kill -s HUP $MAINPIDExecStop=/usr/local/mongodb/bin/mongod --shutdown --config /usr/local/mongodb/mongodb.confPrivateTmp=true[Install]WantedBy=multi-user.target
输入EOF结束。
然后,设置mongodb.service的执行权限:
chmod +x mongodb.service最后,设置mongodb.service开机自启动:
systemctl enable mongodb.service在主节点配置复制集
进入mongo shell:mongo
>rs.initiate()localrs:SECONDARY> rs.add("mongo-slave1:27017") # 注意这里master节点还处于SECONDARY角色了localrs:PRIMARY> rs.add("mongo-slave2:27017") # 注意这里master节点已经被选为PRIMARY角色了
在两个从节点配置复制集
localrs:SECONDARY>rs.secondaryOk()测试复制集是否可用
首先,在主节点进入shell并插入一条数据:
localrs:PRIMARY>db.yzjc.insertOne({"name":"cscec-jc-team"})localrs:PRIMARY> db.yzjc.find().pretty(){ "_id" : ObjectId("608b74155839b06ac76a938d"), "name" : "cscec-jc-team" }
然后,分别在两个从节点查询刚刚在主节点新插入的数据是否已经同步:
localrs:SECONDARY> db.yzjc.find().pretty(){ "_id" : ObjectId("608b74155839b06ac76a938d"), "name" : "cscec-jc-team" }
可以看到,已经同步到了两个从节点了。
本文介绍了如何在Linux下安装部署一个三节点MongoDB的复制集集群。
下一篇,我们会学习如何借助Mongo Tools实现数据恢复 与 提升安全性的一些实践。
参考资料
唐建法,《MongoDB高手课》(极客时间)
郭远威,《MongoDB实战指南》(图书)