
【HTTP】843- 揭秘 HTTP2
 前言
前言前段时间组内小伙伴遇到了一个问题:一个页面上有 10 个视频,因为浏览器对 tcp 连接数的限制,导致同时只能加载 6 个视频。考虑到http2协议的多路复用可以解决这个问题,特地整理此篇关于http2的内容和大家分享。
下面我们先从http1.1说起。
一、http1.1 存在的问题
1.容易触发浏览器 tcp 连接数限制
对于同一个域名,浏览器最多只能同时创建 6~8 个 TCP 连接 (不同浏览器不一样)。因为一个tcp连接一次承载一个请求,也就是说一个时刻最多只能发起6~8个请求,这就是上文说到的只能同时发起 6 个视频请求的问题。为了解决这个限制,行业内惯用域名分区的方案,即将资源分散到不同域名下 (比如二级子域名),这样就可以针对不同域名创建连接并请求。但多域名随之而来的是更多的 dns 查询耗时,以及更多 tcp 连接开销。
2.“队头阻塞”问题
我们都知道,http1.1默认设置请求头部字段keep-alive以保持 tcp 持久连接,以实现多个请求复用同一个 tcp 连接,避免重复建立连接造成的时间开销。但一个问题是这时的 tcp 连接同一时刻只能处理一个 http 请求,即请求时序为“请求1->响应1->请求2->响应2...”,如果请求1没完成,后续的请求2只能等待。
为了尽可能并行发送请求,http1.1 引入了管线技术(pipelining),优化效果对比如下图:

管线技术部分解决了请求并发的问题,仍存在队头阻塞的问题,原因如下:
请求可以并行发出,但是响应必须串行返回。 前一个响应未及时返回,后面的响应就会被阻塞,这就是队头阻塞问题。 必须是幂等请求( GET和HEAD)才能管道化。因为,意外中断时候,客户端需要把未收到响应的请求重发,非幂等请求,会造成资源破坏。
那http2是如何解决这些问题的呢?
二、http2 的优点
http2通过多路复用解决了http1.1队头阻塞和tcp连接数的问题,大家可以先通过下面这个例子(并行加载大量小图)直观感受出http2比http1.1快了很多。

让我们来看看http2是如何做到的!
1.多路复用
http2把原来http所传输的信息划分为多个粒度更小的帧,并对其进行二进制编码,然后将其映射到属于特定流的消息。
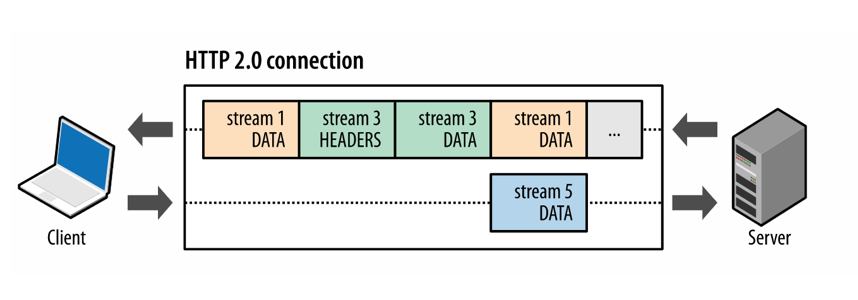
在一个 TCP 连接上,我们可以向对方不断发送帧,每帧的 stream identifier 的标明这一帧属于哪个流,然后在对方接收时,根据 stream identifier 拼接每个流的所有帧组成一整块数据。我们可以把每个请求或者响应都当作一个流,那么多个请求变成多个流,这不同流的数据被分成多个帧,在一个连接中交错地发送给对方,这就是 http2 中的多路复用。
多路复用依赖一个关键技术点,那就是二进制分帧:
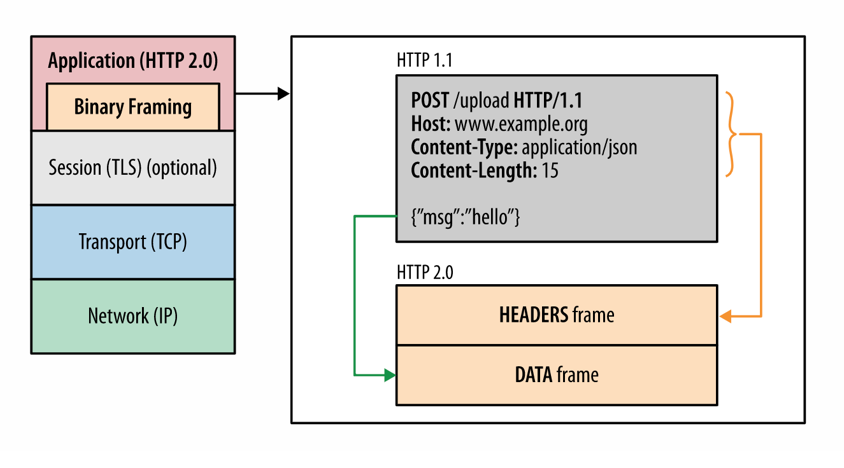
二进制分帧层
二进制分帧层指示如何在客户端和服务器之间封装和传输http消息。它会将所有传输的信息分割为粒度更小的帧,首部信息则被封装到Headers帧,body则封装到Data帧里面。每个帧都以固定的9字节首部开始,里面会至少标明其所属的流。一个流则是一个请求或者响应。正是基于帧和流,且来自不同流的帧可以交错发送,才使多路复用可以实现。
我们前面说到了一个连接里面承载了多个流,并且不同流的帧可以交错发送,那么客户端和服务器交付不同流的帧的顺序成为了关键的性能考虑因素,因为不同资源的优先级是不一样的,为了实现这一点,引入了流优先级。
2.流优先级
http2允许每个流具有流依赖关系以及相关的权重:
权重:可以为每个流分配1到256之间的整数权重
流依赖关系:每个流可以明确依赖一个流
客户端使用权重和流依赖关系的组合信息,向服务端构造和传递“优先级树”,该树表明其希望如何接收响应,即我们期望优先级越高的请求越快得到响应,服务端使用此信息确定流处理的优先级,控制cpu、内存和其他资源的分配。一旦响应数据可用,就分配带宽以确保向客户端最佳的传递高优先级响应。那么如何确认流的优先级呢?
流优先级的计算
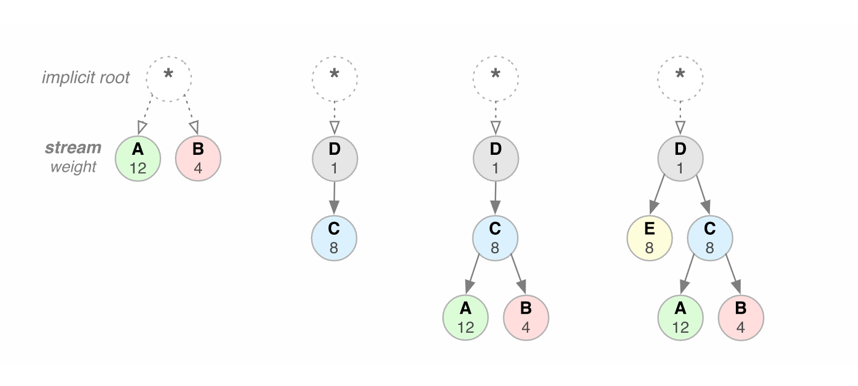
通过引用另一个流的唯一标识符作为其父级来声明http2中的流依赖性; 如果省略,则称该流依赖于“根流”。流依赖性表明,如果可能,则希望在处理它之前先为父流分配资源。例如:C依赖于D,则表明请在响应C之前先处理并响应D。
共享相同父级的流应该按其权重比例分配资源。例如对于上图流A和流B,他们都是根流,A的权重为12,B的权重为4,则A应该接收到资源的比例为12/16=3/4。B接收到资源的比例为1/4。
不过,值得注意的是,流优先级只是表达了一种传输偏好,不表示绝对的要求,因此不保证特定的处理或传输顺序。虽然看上去觉得违反直觉,毕竟设置优先级就是希望资源按照我设定的顺序返回,可是却又并不能保证绝对的顺序。但其实这是合理的行为:当高优先级的资源阻塞的时候,低优先级的资源不会被阻塞。
流优先级的设置
流优先级是由客户端设置,发给服务端的。浏览器中有一个默认的优先级。浏览器基于自身对资源重要性的判读,为不同的资源分配相应的优先级。例如,页面 中的